
Hao Liu
@haoliuhl
Followers
5K
Following
435
Media
102
Statuses
282
Bay Area
Joined September 2018
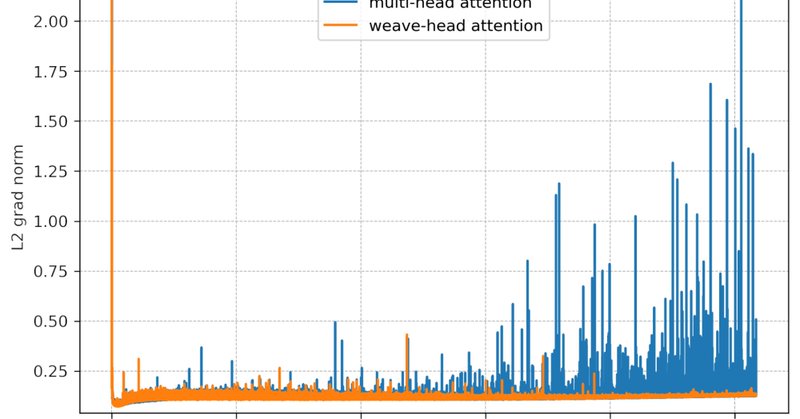
Just wrote a long-overdue blog post on Weave-Head Attention: a minimal change that substantially boosts training stability at scale.
6
16
174
We believe that ElasticTok opens up a promising direction towards adaptive tokenizers, which can enable more efficient processing of long-context data, such as in world models & agents. This is a fun joint work w/ @wilson1yan, @matei_zaharia, @VladMnih, @pabbeel, @AleksandraFaust
0
0
7
The code is available and has been tested in large-scale training. Code: https://t.co/JQUOjXyVha Paper: https://t.co/FXDJp2J3Ps Website:

arxiv.org
Efficient video tokenization remains a key bottleneck in learning general purpose vision models that are capable of processing long video sequences. Prevailing approaches are restricted to...
1
0
6
Check out @wilson1yan’s thread for more details.

We are excited to announce ElasticTok, a simple yet scalable visual tokenizer that can adaptively encode image and video to variable-length sequences! Our model enables more efficient token usage over different images and long dynamic videos.
1
0
0
ElasticTok saves up to 3.5x on images & 5x on video tokens while maintaining the same quality, across different reconstruction thresholds.
1
0
0
ElasticTok uses a scalable masking scheme to achieve elastic representation — dropping a random number of tokens at the end of each frame. Intuition: The model has to learn to keep important info in early tokens since they're less likely to be masked out.
1
0
1
Result? Efficient token usage for images & video. ElasticTok adapts to available info, dynamically allocating tokens based on video content complexity. Top: Groundtruth. Middle: Reconstructed frames with varying tokens. Bottom: Adaptive token allocation over time.
1
0
1
Fixed token allocation per frame in multimodal models is inefficient. Introduce ElasticTok: adaptive encoding that uses variable tokens based on complexity. It conditions on prior frames, uses scalable masking technique. Project: https://t.co/WUS09YJfED
1
8
67

How do LLMs scale to million token context window? Ring Attention is a nice trick to parallelize long sequence across devices and rotate them in a ring with zero overhead scaling. In our new blog, we cover the tricks behind this magic. It looks like this (1/5🧵)
14
117
684

How do state-of-the-art LLMs like Gemini 1.5 and Claude 3 scale to long context windows beyond 1M tokens? Well, Ring Attention by @haoliuhl presents a way to split attention calculation across GPUs while hiding the communication overhead in a ring, enabling zero overhead scaling
5
66
308

Large world models by @haoliuhl et al. is worth checking out if you like the Gemini-1.5 and Sora results. It has 1M context window, generates videos, and is open sourced. 1. LWM shows high recall over 1M context window, and performs exceptionally well with video chat as well.
1
10
56

Current works are restricted to short sequences of texts and images, limiting their ability to model the world. Presenting Large World Model (LWM): capable of processing long text, images, videos of over 1M tokens (and *no* lost in the middle!) Project:
We are excited to share Large World Model (LWM), a general-purpose 1M context multimodal autoregressive model. It is trained on a large dataset of diverse long videos and books using RingAttention, and can perform language, image, and video understanding and generation.
5
35
218

Gemini 1.5 Pro is an impressive work. Sadly, the technical report is very very sparse on details. But this paper from yesterday gives a glimpse on how one may train for extra long context:
We are excited to share Large World Model (LWM), a general-purpose 1M context multimodal autoregressive model. It is trained on a large dataset of diverse long videos and books using RingAttention, and can perform language, image, and video understanding and generation.
2
2
32
LWM opens up exciting possibilities for the development of more capable AI systems that understand both textual knowledge and multimodal world and solve a wide range of problems. Paper: https://t.co/HUdgcCtHke Code: https://t.co/yYLKPFUq1S Website:

github.com
Large World Model -- Modeling Text and Video with Millions Context - LargeWorldModel/LWM
4
1
24
In this work, we propose LWM to model complex million-length language and visual sequences. We curated a large, diverse dataset and utilized RingAttention to scalably train on it. We discover challenges and propose masked sequence packing and model-generated QA to address them.
1
1
15
We open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens, along with the codebase for training and inference. The models are available at https://t.co/wsuKQbpbEg.

huggingface.co
1
8
59
This work provides a highly-optimized, open-source implementation with RingAttention, masked sequence packing, model-generated QA, and other key features for millions-length vision-language training. We have good MFUs even at very large context sizes.
1
1
14
LWM can answer questions based on over 1 hour long YouTube video, while GPT-4V and Gemini Pro Vision struggle.
3
1
15