

William Brandon
@exists_forall
Followers
659
Following
7K
Media
44
Statuses
569
he/him • Trying to become compute-bound • PhD student at MIT CSAIL • Prev: CS & Math at UC Berkeley; ML Compilers at NVIDIA • Opinions my own
Cambridge, MA
Joined March 2019
If any of you ever manage to find another line of code as beautiful as this one, I want to see it.
A thing can be seen or unseen. A thing is usually unseen. Carry out examining: now the noun is seen.
1
5
30
Getting this implemented, tested, and written up quickly was a great team effort with Ani Nrusimha (@Ani_nlp), Kevin Qian (@skeqiqevian), Zack Ankner (@ZackAnkner), Tian Jin (@tjingrant), Zoey (Zhiye) Song, and my advisor Jonathan Ragan-Kelley (@jrk). Go follow them!. 9/9.
0
0
6

Additionally, thanks to @mcarbin for sponsoring the reading group ( where we came up with this idea in the first place!. 8/.
1
0
8
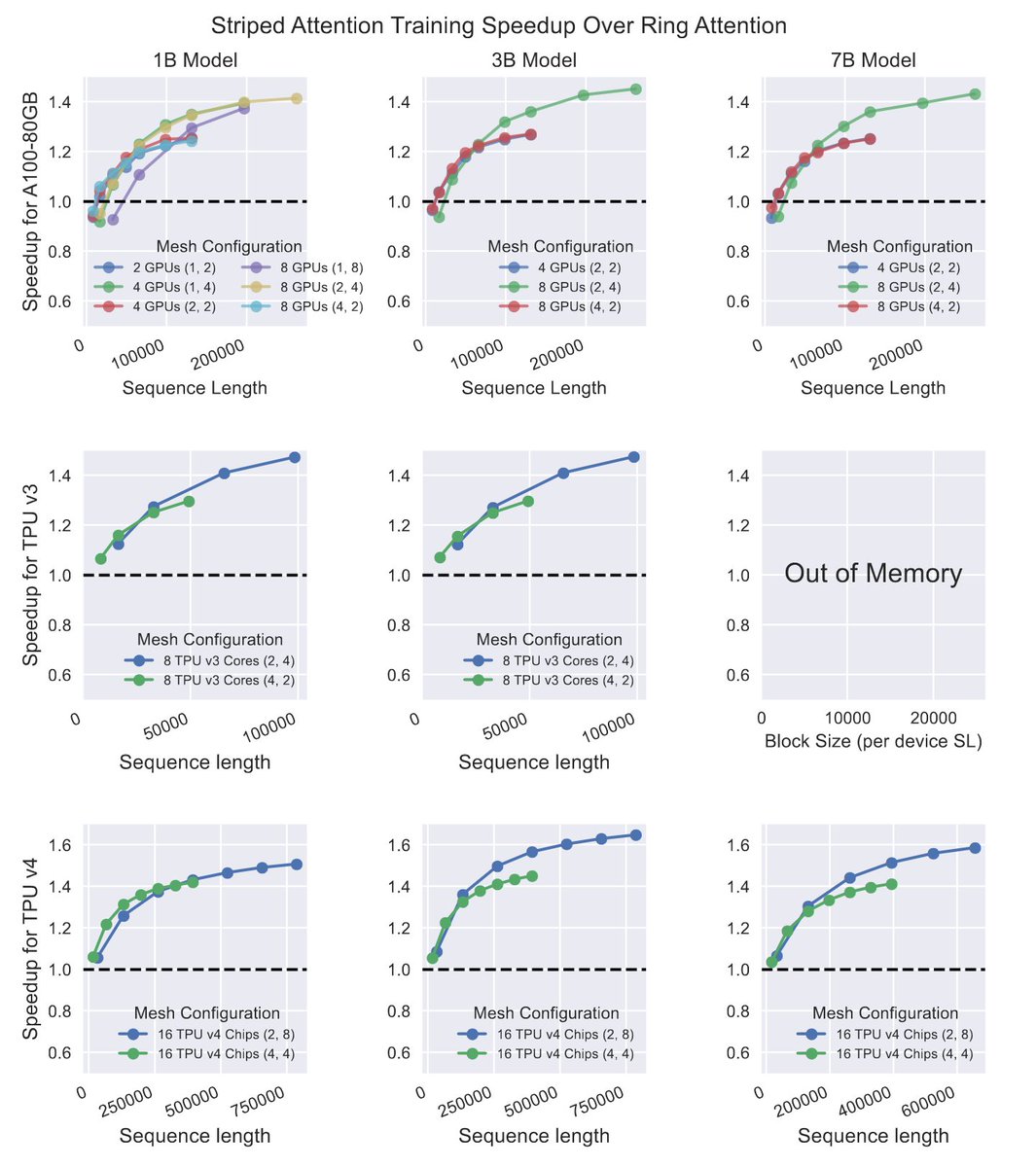
We hope anyone training long-context language models with dense attention considers using Striped Attention to speed up their system!. Big thanks to @haoliuhl for the original Ring Attention technique + code, and to @morph_labs, @mosaicml, and the Google TRC for compute. 7/.
1
0
4
That's it! Like the original Ring Attention, Striped Attention is an *exact* attention algorithm, with no approximations or tradeoffs in accuracy. You should be able to use Striped Attention as a drop-in replacement for the original Ring Attention in any causal transformer. 6/.
1
0
5
Thankfully, there's a very simple way to fix this workload imbalance: just permute the input sequence + the mask! If you pick the right permutation, every device's attention mask becomes upper-triangular on every iteration, and no device has to spend any time sitting idle. 5/


1
0
5
Our key observation is that Ring Attention has a workload imbalance when you consider the causal mask. On any given iteration, some devices will be computing query/key interactions which are entirely masked out, while others compute interactions which are entirely unmasked. 4/

1
0
5
For general bidirectional self-attention, Ring Attention is already close to optimal. It uses a communication pattern which allows overlapping communication with compute, achieving great utilization. However, for *causal* self-attention, we noticed a way to improve it!. 3/.
1
0
5
We build on top of the very cool Ring Attention technique introduced last month by @haoliuhl et al. (. Ring Attention is an efficient algorithm for computing self-attention for huge sequences (>100k tokens) distributed across multiple GPUs (or TPUs). 2/.

arxiv.org
Transformers have emerged as the architecture of choice for many state-of-the-art AI models, showcasing exceptional performance across a wide range of AI applications. However, the memory demands...
1
0
8
New preprint out with colleagues from MIT!. "Striped Attention: Faster Ring Attention for Causal Transformers". We introduce a simple extension to the recent Ring Attention algorithm for distributed long-context attention, and see speedups up to 1.65x!. 1/

5
12
66
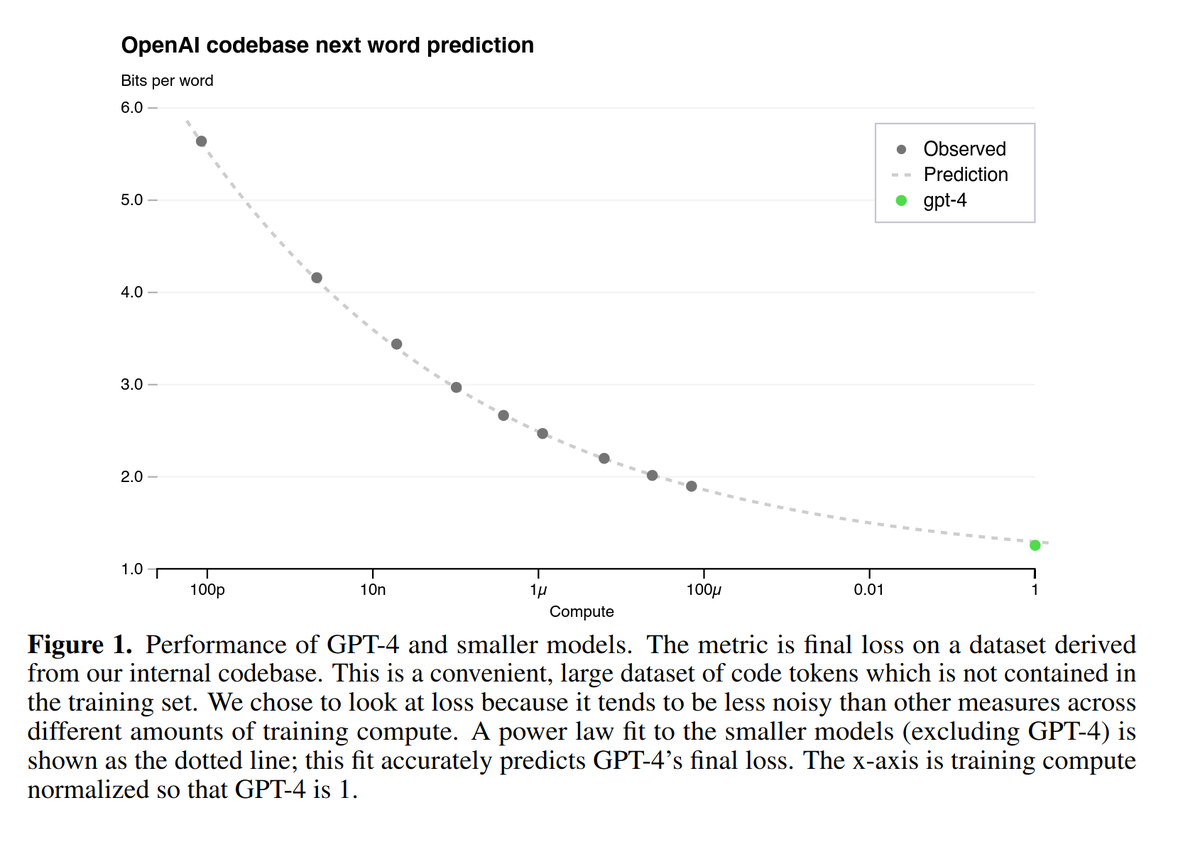
the ~0.12 exponent is asymptotically less training-compute-efficient than the chinchilla scaling exponent of ~0.15. probably suggests the model is overtrained to save on inference costs?.
0
0
1
The equation of the trendline they plot is given by. bits per word = 0.27189 * compute^-0.12200 + 1.02433. where "compute" is measured relative to the GPT-4 training run.
1
0
1
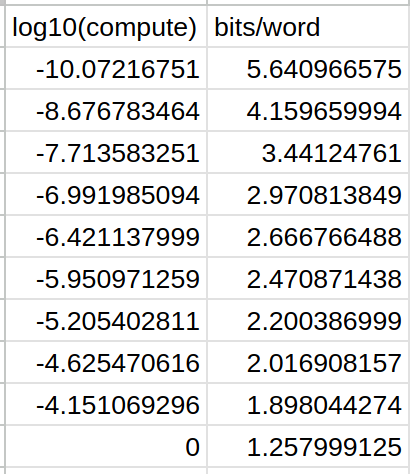
I extracted the coordinates from this scaling plot in the GPT-4 technical report, in case anyone is interested:
1
0
4
Someone should make “Throughput Numbers Every Programmer Should Know” (by analogy to .
0
0
4
RT @plt_amy: If any of this sounds like someone you'd want to have as a student, despite the cons, and getting around the lack of an underg….
0
30
0
Concept: a game which is just a normal platformer, except you can only see the Fourier transform of the screen.
1
0
6