

Matei Zaharia
@matei_zaharia
Followers
43K
Following
20K
Media
173
Statuses
3K
CTO at @Databricks and CS prof at @UCBerkeley. Working on data+AI, including @ApacheSpark, @DeltaLakeOSS, @MLflow, https://t.co/94gROE5Xa0. https://t.co/nmRYAKG0LZ
Joined October 2010
Lots of people are wondering whether #GPT4 and #ChatGPT's performance has been changing over time, so Lingjiao Chen, @james_y_zou and I measured it. We found big changes including some large decreases in some problem-solving tasks:

118
745
3K
Building a ChatGPT-like LLM might be easier than anyone thought. At @Databricks, we tuned a 2-year-old open source model to follow instructions in just 3 hours, and are open sourcing the code. We think this tech will quickly be democratized.
41
489
2K
Interesting trend in AI: the best results are increasingly obtained by compound systems, not monolithic models. AlphaCode, ChatGPT+, Gemini are examples. In this post, we discuss why this is and emerging research on designing & optimizing such systems.
31
259
1K
Very excited to return to UC Berkeley as a professor starting this week. I’ll be collaborating with the Sky Lab, @UCBEPIC, @berkeley_ai and others!.

@Berkeley_EECS welcomes @matei_zaharia, who returns to Berkeley EECS as an Associate Professor. Matei’s research interests include computer systems and machine learning. He is also the co-founder and Chief Technologist of Databricks. Welcome back, Matei!.
49
43
845
Pretty sure I've seen people driving with only 19 neurons too!.

This autonomous car can drive itself using only 19 control neurons. Video: More: (work w/@ISTAustria @tuvienna). #SelfDrivingCars #Autonomy #ML #DL #MachineLearning
6
121
756
We're launching two comprehensive online courses on building and using Large Language Models! The first is on using LLMs in applications, covering topics like prompt engineering, embeddings, chains, and MLOps. The second teaches you to build your own LLMs.
9
142
658
At Databricks, we've built an awesome model training and tuning stack. We now used it to release DBRX, the best open source LLM on standard benchmarks to date, exceeding GPT-3.5 while running 2x faster than Llama-70B.
13
130
646
MLflow just added first-class support for LLMs, including integrations with @huggingface transformers/pipelines, @OpenAI and @LangChainAI! Open source #LLMOps is here.
4
142
595
We've just launched a version of Dolly on HuggingFace, with new examples showing its capabilities. This is all with just 50k training examples. Stay tuned for new versions with other datasets soon.
9
90
555
Who are the World Cup champions? I knew ChatGPT would get it wrong when it launched, but it's surprising that all the new search+LLM engines do too. Combining retrieval+LMs won't just be a matter of prompting. That's why we've been building tools like DSP at Stanford to do it.




22
57
519
Thrilled to receive this award; the credit is due to my students, my mentors, my collaborators in academia and open source, and my colleagues at Databricks for making all this work happen!.

The 2023 @ACMSIGOPS Mark Weiser was presented to @matei_zaharia for innovation and impact in large-scale data processing. The award was announced at @sospconf. From next year, awards will be announced annually as @sospconf is now an annual conference. See you in #austin in 2024.
52
38
452
Super excited to announce MLflow, a new open source Machine Learning platform from Databricks to manage the complete machine learning lifecycle:
6
205
411

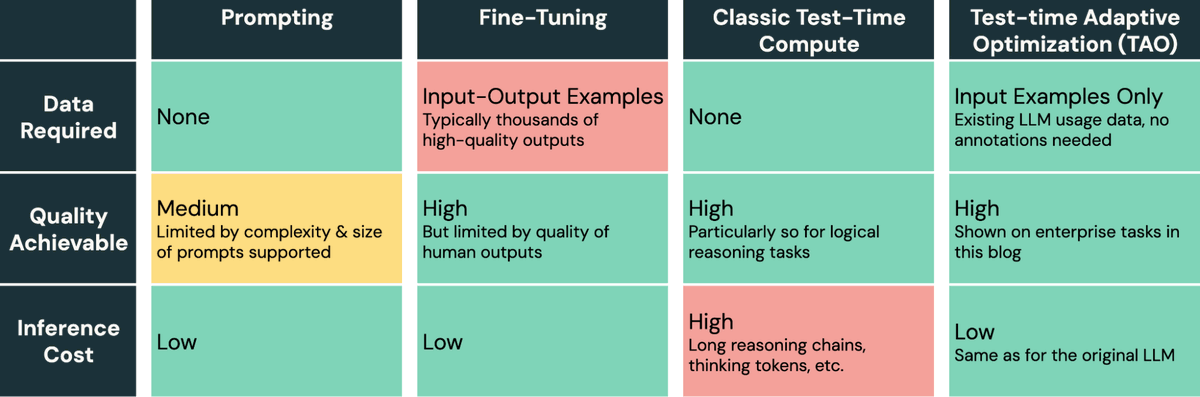
Really cool result from the Databricks research team: You can tune LLMs for a task *without data labels*, using test-time compute and RL, and outperform supervised fine-tuning! Our new TAO method scales with compute to produce fast, high-quality models.
9
73
433
Not a problem with Lakehouse.

my friend works in fashion. i set her up with one of my tech homies. this is how it went.

17
24
422
For example, GPT-4's success rate on "is this number prime? think step by step" fell from 97.6% to 2.4% from March to June, while GPT-3.5 improved. Behavior on sensitive inputs also changed. Other tasks changed less, but there are definitely singificant changes in LLM behavior.
11
54
399
One of my favorite announcements: English SDK for @ApacheSpark! No more need to remember weird syntax, just chain transformations in natural language with the familiar Spark API. So many fun examples.

12
71
407
Due to COVID19, we decided to make #SparkAISummit virtual and also *free* for anyone to attend this year! We still have the same great program with over 200 talks and keynotes from @NateSilver538, @jenniferchayes, @apaszke and more. Tune in for the largest data & AI summit ever.

We can’t wait to solve the world’s toughest problems — and it starts with #SparkAISummit, the world’s largest data and machine learning conference. As a global virtual event, we'll converge to shape the future of big data, analytics and AI. Join us:

10
156
357
Our MOOC on Large Language Models: Application through Production started today! Join me, Sam Raymond, Chengyin Eng and Joseph Bradley from Databricks as we cover how to build end-to-end apps with LLMs, including components like vector DBs and chains.
4
60
354
Our new MOOC on #LLM Foundation Models from the Ground Up is now available! Join me, Chengyin Eng, @sjraymond, Joseph Bradley and @abhi_venigalla for a detailed look at how LLMs are built, how to improve them, and where the field is going.
4
83
351
Congrats to my student @codyaustun (with @pbailis) on defending his PhD today! Cody did amazing work improving the resource and data efficiency of deep learning, including widely used benchmarks (DAWNBench/MLPerf), perf analysis, and new 10-1000x faster algorithms (SVP & SEALS).



14
34
335
Does long context solve RAG? We found that many long-context models fail in specific and weird ways as you grow context length, making the optimal system design non-obvious. Some models tend to say there's a copyright issue, some tend to summarize, etc.
12
77
328
How can you efficiently evaluate RAG-based LLM applications like document question answering? We've tested several methods on our internal question answering applications at Databricks and found some effective ways to do this using LLMs.
0
61
321
I'm super honored to have received a #PECASE award this year. Percy Liang from @StanfordNLP also got one, which is great news for Stanford CS. Congrats to everyone else who received one!
17
26
306
This thread highlights a point we've been seeing in for a while: you can't meaningfully talk about capabilities of a *language model*, you have to talk about capabilities of a *system*, including the inference algorithm. 32-CoT is not the same as 5-shot.

.@JeffDean why the need to do 32-CoT Gemini Ultra vs 5-shot GPT-4? Why not just report 5-shot vs 5-shot?.
6
40
309
For @VLDB2020, we wrote a paper on @DeltaLakeOSS, one of the most exciting new technologies from Databricks. By adding ACID transactions over cloud object stores, we can provide data-warehouse-like capabilities & performance on low-cost, HA cloud storage.

5
88
300
We've made the ebook version of Learning Spark 2nd edition available for free -- don't miss it!
5
93
285
Excited to share our #Lakehouse technical paper published at #CIDR21. We describe a new class of data platforms that are (1) completely open, (2) efficiently support #MachineLearning, and (3) provide all traditional #DataWarehouse capabilities+performance.

6
87
286
Databricks just set a new record on the official TPC-DS data warehousing benchmark, showing that a lakehouse system based on open data formats can outperform previous DW systems. Don't listen to folks who say open means bad performance!
4
67
284
Really excited to introduce the MLflow Model Registry today, a new MLflow component for collaboratively sharing and managing models:
2
95
268
To be fair, if you're asking someone who worked on Windows, "shut down and restart" worked pretty well there.

5
31
269
#ApacheSpark 3.0 greatly simplifies writing Python user-defined functions through type hints, and makes it easier for your functions to process data efficiently in batches via Pandas and Apache Arrow. Check out how to use them:
2
75
262
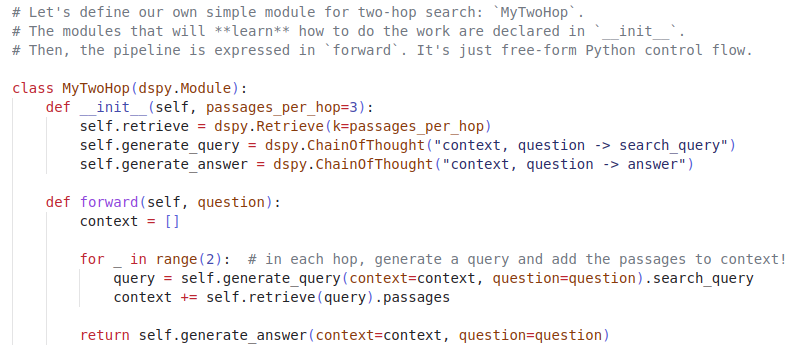
This is a big release: we've spent the past 3 years working on LLM pipelines and retrieval-augmented apps in my group, and came up with this rich programming model based on our learnings. It not only defines but *automatically optimizes* pipelines for you to get great results.

🚨Announcing 𝗗𝗦𝗣𝘆, the framework for solving advanced tasks w/ LMs. Express *any* pipeline as clean, Pythonic control flow. Just ask DSPy to 𝗰𝗼𝗺𝗽𝗶𝗹𝗲 your modular code into auto-tuned chains of prompts or finetunes for GPT, Llama, and/or T5.🧵.

1
49
274
#ApacheSpark 2.4 is out today! This release has tons of new features including barrier execution mode for ML applications, higher-order functions in SQL, optional eager evaluation for previewing DataFrames in Jupyter, Scala 2.12 support and more.
0
123
254
I'm co-organizing a new conference on Systems for Machine Learning starting in February; our first call for papers is up at so submit your interesting SysML work by Jan 5th!.
7
144
247
As we worked with customers using LLMs, a common pattern we saw was that everyone wanted to add a layer in front of the LLM API to manage credentials, rate limits, etc, and to easily swap between models. We've built this the open source @MLflow AI Gateway:.
4
52
239
We're very excited to be one of the launch partners for Meta's Llama 2 🦙! We got to test Llama 2 in advance and were very impressed. The new version also has a much more permissive license. We've set everything up so you can run it on Databricks today.
1
43
237
Cool to see this model from @MosaicML being trained on RedPajama and Dolly data. Fully open source AI is becoming a reality -- open source efficient training, curated web dataset, and instruction data. Still early and small model but it will get better.
1
44
241
Super excited about the new Agent Framework, Tool Catalog, Vector Search, Evaluation and Training capabilities we launched today in Mosaic AI. We see more companies building compound AI systems, and we have created an end-to-end environment to do this.

2
50
236
Want to efficiently query a vector DB while filtering on structured attributes? My student Liana Patel, together with @petereliaskraft and @guestrin, modified HNSW to do this efficiently in ACORN, to appear at SIGMOD:

4
41
231
We just posted ColBERTv2, which dramatically reduces the space usage of ColBERT and gets state-of-the-art information retrieval quality on MS MARCO as well as out-of-domain on BEIR🍺, Open-QA retrieval, and our new long-tail task benchmark LoTTE☕️.
5
50
232
Databricks just published our #StateofDataAI report, with interesting trends at our enterprise customers: 1. Adoption of LLMs is booming, with use of SaaS LLM APIs exploding since #ChatGPT launched, but the largest use (and growth) still in custom LLMs.
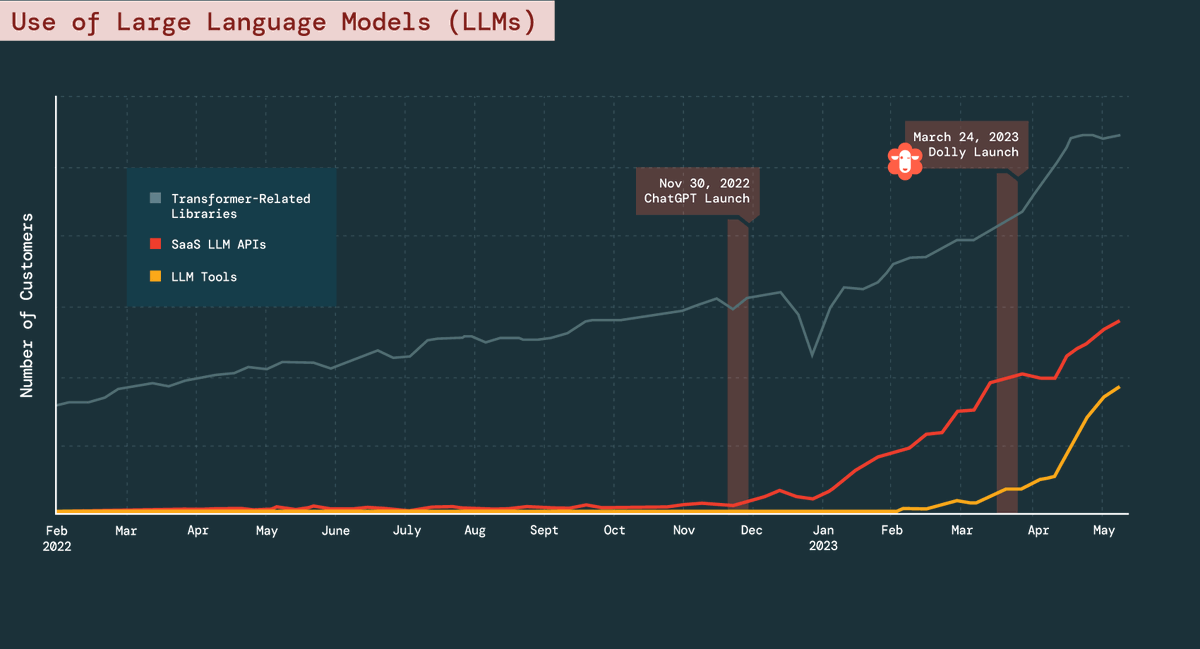
2
55
222
Very cool to see Dolly-v2 hit #1 trending on HuggingFace Hub today. Stay tuned for a lot more LLM infra coming from Databricks soon. And register for our @Data_AI_Summit conference to hear the biggest things as they launch -- online attendance is free.

2
37
223
Large NLP models are expensive and opaque, but maybe it doesn't have to be that way. This exciting work with Omar Khattab and @ChrisGPotts uses retrieval to set SotA results in hard NLP tasks at low cost. Our Baleen paper will be a spotlight at NeurIPS.
3
43
226
Want to build your own chat AI from scratch? We're launching a Building LLMs course at @Data_AI_Summit to teach everyone how to build a Dolly clone: Tiny model, big attitude, for anyone. #DemocratizeAI

5
38
209
It's hard to believe that #ApacheSpark was first released as a research project 10 years ago! My @SparkAISummit keynote (live now) goes through the lessons in the past 10 years and what's new in #ApacheSpark 3.0.

6
39
206
As good a time to say this as any: if you’re on the AI research job market, Databricks is hiring, with the mission to democratize AI. We power amazing customer use cases and we publish. Check or reach out.
5
29
207
Databricks is now available on @googlecloud! We've also built great integrations with BigQuery, Looker, GCS and Google AI services across the product.

Open #lakehouse platform meets open #cloud with unified data engineering, data science and analytics. Learn more about Databricks on @GoogleCloud:
7
41
209
We're thrilled to announce the keynote speakers for #MLSys2025: @AnimaAnandkumar, @soumithchintala, Ling Liu and @istoica05! Registration is open to attend the conference in Santa Clara.

2
29
210
Very excited that @ApacheSpark won the SIGMOD System Award this year. Congrats to the whole community behind the project!.

2022 ACM SIGMOD Awards. Edgar F. Codd Innovations Award goes to Dan Suciu. Contributions Award goes to Christian S. Jensen. Test-of-Time Award goes to “NoDB: Efficient Query Execution on Raw Data Files”. Systems Award goes to “Apache Spark”. Congrats!.
5
24
204
We updated the code for Dolly so it only trains in 30 minutes now. It’s nice to be able to experiment quickly with instruction tuning.

We’re actively updating the Dolly repo with model improvements! Make sure to pull the latest changes. At $30 / 30min per training run it’s dead simple to run multiple experiments. Also, 688 stars in 20 hours! Neat!.
2
43
198
DSP: and some of our past work on retrieval-based NLP for accurate question answering and other tasks:
4
30
206
I gave a keynote at @ACMSoCC about lessons from building a large-scale cloud service at @Databricks. Did you know that Databricks runs millions of VMs/day to process exabytes of data with <200 engineers? Slides here:

2
51
198
Congratulations and so well deserved, Omar! It's been fantastic working together.
I'm excited to share that I will be joining MIT EECS as an assistant professor in Fall 2025!. I'll be recruiting PhD students from the December 2024 application pool. Indicate interest if you'd like to work with me on NLP, IR, or ML Systems! Stay tuned for more about my new lab.
3
8
194
Congrats to the #ApacheSpark community on the 3.0 release! Over 440 developers contributed 3400 patches to this release, with big improvements in SQL performance, ANSI SQL support, Python usability and management features.

[ANNOUNCEMENT] Congrats to the Apache Spark community and all the contributors! The Apache Spark 3.0 is here. Try it out!
1
59
189
Exciting times at @Databricks. We're hiring in all departments, so take a look if you want to help shape the next generation of infrastructure for data and AI.

Databricks raises $1B at $28B valuation as it reaches $425M ARR by @alex and @ron_miller.
3
25
190
I'm co-organizing the inaugural research workshop on Compound AI Systems on June 13th: . Send in your work on designing & optimizing such systems!. Thrilled to have @RichardSocher, @MonicaSLam and @polynoamial as speakers, and host this at @Data_AI_Summit.
2
32
191
Meet #LakehouseIQ: a knowledge engine from your enterprise that understands your business & data to power AI apps. Every platform is adding an AI assistant, but in data, LLMs don't just work out of the box, because every org has its own jargon, data, etc.

11
88
182
Really cool to see OpenAI o1 launched today. It's another example of the trend towards compound AI systems, not models, getting the best AI results. I'm sure that future versions will not only scale inference, but also use tools (coding, search, etc) for better results.
Interesting trend in AI: the best results are increasingly obtained by compound systems, not monolithic models. AlphaCode, ChatGPT+, Gemini are examples. In this post, we discuss why this is and emerging research on designing & optimizing such systems.
4
24
186
We also have a big announcement for @MLflow today: it's joining the @linuxfoundation as a long-term vendor-neutral home to host the project! We've been blown away with how fast MLflow has grown and hope this leads to even more contributors.
1
78
181
We just posted the first release of open source Unity Catalog! It supports tables, unstructured data, and AI, and we have a great set of partners across data and AI integrating with it. Read more at

2
33
177
Second big announcement is open sourcing Databricks Delta as Delta Lake. Delta dramatically simplifies building reliable data lakes on HDFS and cloud storage through ACID transactions, indexes and scalable metadata handling. More info here:
5
105
170
The great thing is that for customers wishing to build such models that natively understand their data, the cost could be even less. We have the checkpoints, data cleaning pipeline, instruction tuning pipeline, etc from DBRX — just apply these to your data.

Just $10M and two months to train from scratch a GPT3.5 - Llama2 level model. For context, it probably cost 10-20x more to OAI just a year ago!. The more we improve as a field thanks to open-source, the cheaper & more efficient it gets!. All companies should now train their own

1
20
157
Probably the thing I’m most excited about with DBRX, it’s super fast! Easily 150 tokens/s for quality comparable to much slower closed models.


6
29
171
How can you make LLM-as-judge reliable in specialized domains? Our applied AI team developed a simple but effective approach called Grading Notes that we've been using in Databricks Assistant. We think this can help anyone doing domain-specific AI!
4
29
167
Congrats to my student @deepakn94 for defending his PhD! Deepak worked on a ton of exciting systems and ML research, including Weld, DAWNBench/MLPerf, and most recently pipelining methods for efficient DNN training, including PipeDream-2BW (ICML'21) and Megatron's 1T param model.

5
7
164
MLflow 2.8 is out today, with new support for LLM-based eval metrics among other features. Read about how we've been using it to improve our RAG apps at Databricks, like our docs assistant:
2
29
166
Thrilled that Forrester named Databricks a Leader in their report on AI Foundation Models in enterprise! We help organizations build the best AI for *their* domain and data, using the best techniques available, with a world-class research team to back it.

5
38
162
Everyone is doing RAG on unstructured docs, but what if you want to mix in structured business data? Databricks RAG can connect to feature tables & functions to query the latest data in your catalog, all with centralized governance, security and MLOps.
3
27
155
Really proud of my student @sppalkia who passed his (online) PhD defense today! He's the first of my students to graduate, and he did awesome work accelerating data applications with Weld, Mozart and other systems. You can see his talk and slides here:
1
26
159
Apache Spark (and Databricks) are getting first-class support in @HuggingFace! You can now rapidly load data from these engines for HuggingFace training and inference, giving up to 40% speedups.
2
21
153
Everyone’s excited about vector DBs, but there’s a lot to do to get truly high quality retrieval systems! Check out this paper benchmarking quality, latency and cost.

#acl2023 findings paper for folks working on retrieval leaderboards- Read on:. ✅ We show multi-dimensional tradeoffs e.g. quality , latency & cost (instead of just F1).✅ Metrics that include concrete efforts e.g. DynaScore. -- Code in PrimeQA:

2
23
156
One of my favorite features in the upcoming #ApacheSpark 3.0 is Adaptive Query Execution (AQE), which tunes number of reduce tasks, join algorithms and skew joins automatically. Learn how it works and how it speeds up TPC-DS queries by up to 8x:
0
41
156
The new research group I'm part of at Stanford, DAWN, is building infrastructure for usable machine learning:
1
69
151
Super excited about our agreement to acquire @neondatabase, bringing state-of-the-art, serverless elastic Postgres to Databricks! Building end-to-end data and AI apps is about to get much easier.

I am super excited to announce that we have agreed to acquire Neon, a developer-centric serverless Postgres company. The Neon team engineered a new database architecture that offers speed, elastic scaling, and branching and forking. The capabilities that make Neon great for.
5
11
157
We’re hiring for the RAG / AG research team at Databricks. Come help make AI even better at incorporating real-time data and external tools.

“How’s your sabbatical?” Well…DBRX is GREAT at RAG!. If you’ve been using Mixtral/Llama2/GPT3.5, then try DBRX! The combination of RAG with its SoTA capabilities on knowledge/code/reasoning will unlock new CompoundAI opportunities.
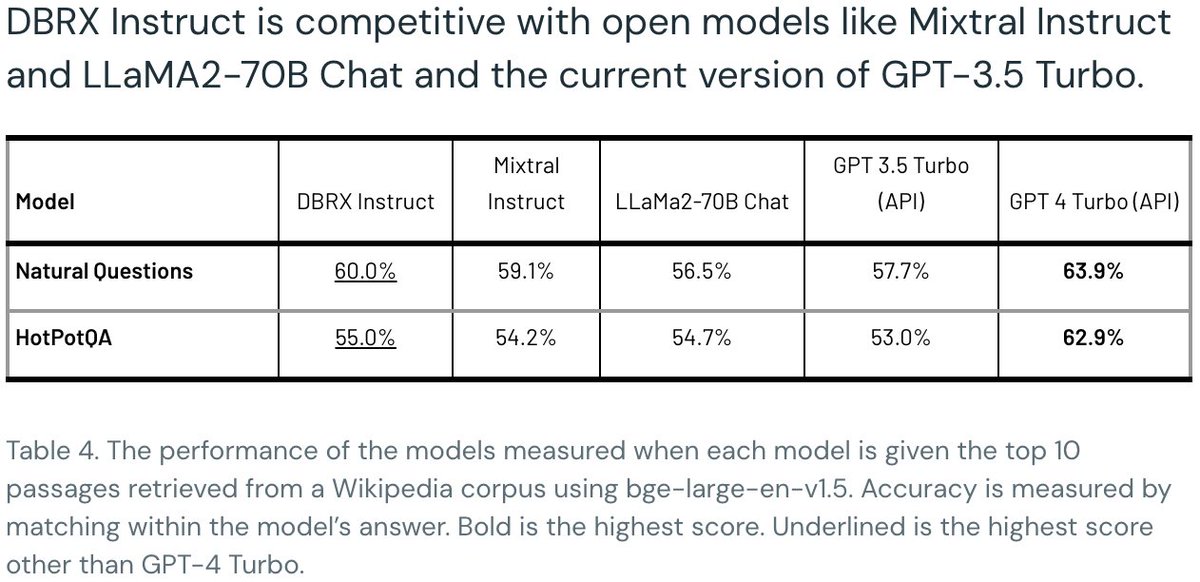
2
20
151
Want to build your own conversational AI from open datasets and your own data? Join this free webinar on April 25th with some of the Dolly authors:

2
43
152
So excited about this -- bringing amazing platforms for data and AI together. @NaveenGRao, @hanlintang and @jefrankle have built an amazing team that has steadily reduced the cost of AI training and released breakthroughs like the first open source LLMs with >64K context.
Today we’re announcing plans for @MosaicML to join forces with @databricks! We are excited at the possibilities for this deal including serving the growing number of enterprises interested in LLMs and diffusion models.
4
17
146
Just in time for my lecture on data quality at Stanford.

5
12
147
Sad about the chaos around OpenAI, which was crazier than anyone imagined, and how it’s affecting people, especially those on visas. I hope everyone lands on their feet!.
4
13
147
We want to run a longer study on this and would love your input on what behaviors to test!.
21
9
138
Congrats to the whole team at Databricks for the continued ultra-fast growth! We're hiring in all roles to continue simplifying how organizations work with data through technologies such as @DeltaLakeOSS, @MLflow, @ApacheSpark and more.
We're excited to announce that we've raised $400 million to continue our rapid global growth and engineering expansion, an investment that brings our valuation to $6.2 billion. Learn more:
1
23
142
My talk on #Lakehouse systems from #CIDR21 is now online, explaining this new trend in data management systems: You can also find our paper at
2
34
144
Welcome Omar, and really excited to keep working together on research along with the DSPy community.
Some personal news: I'm thrilled to have joined @Databricks @DbrxMosaicAI as a Research Scientist last month, before I start as MIT faculty in July 2025!. Expect increased investment into the open-source DSPy community, new research, & strong emphasis on production concerns 🧵.
4
6
142
We've just released a suite of awesome features for building high-quality RAG apps on Databricks: In talking with enterprises, we found quality was often the top concern with RAG, so we help teams monitor and improve it at all levels of the stack.
4
30
138
Pretty accurate!.

Apache Spark - Query Execution Plan. #apachespark #sql #dataengineering #databricks #scala #python #azure #Hyderabad
5
19
135
#PySpark downloads are growing 3x year-on-year. As a result, the @ApacheSpark community is investing a lot in making its Python APIs easier as part of "Project Zen". Read about some of the work currently in progress, including type hints, viz and docs:
3
42
136
My keynote talk on the MLflow Model Registry is now available online, including a great demo from Corey Zumar:
0
42
137
We're serious about an open, compatible foundation for all enterprise data. Very excited to work with the @tabulario team to make the open source data ecosystem even better.
Databricks to acquire @tabulario, a data platform from the original creators of Apache Iceberg. Together, we will bring format compatibility to the lakehouse for @DeltaLakeOSS and @ApacheIceberg.
4
22
125
Super excited about this work, and it's open source! One of the coolest open source frameworks from my research group. It lets developers use language-based models (including retrievers) in a composable way to build complex apps.
Introducing Demonstrate–Search–Predict (𝗗𝗦𝗣), a framework for composing search and LMs w/ up to 120% gains over GPT-3.5. No more prompt engineering.❌. Describe a high-level strategy as imperative code and let 𝗗𝗦𝗣 deal with prompts and queries.🧵.
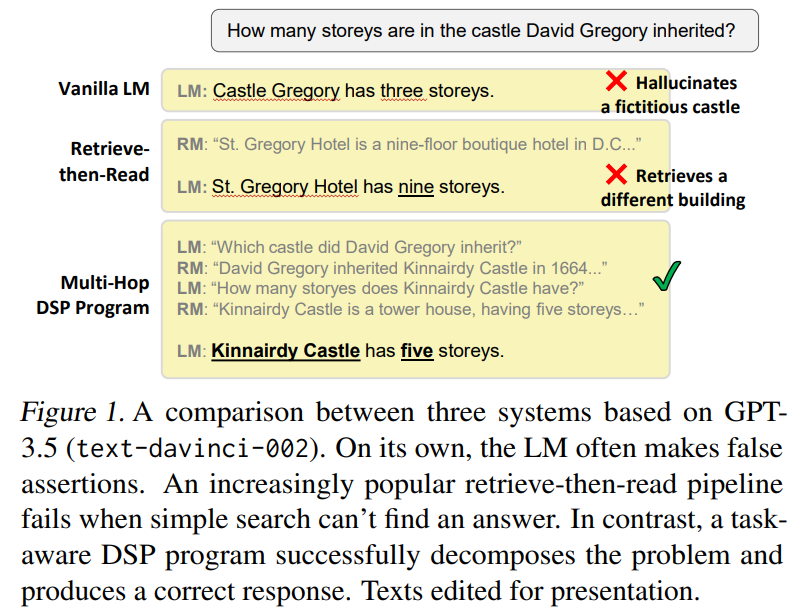
2
17
132

A lot happened in Databricks SQL in 2023 -- no wonder it's one of the fastest growing data warehouse platforms. Read how we improved latency and concurrency, made it serverless, and began automatically optimizing most workloads with AI:
3
21
127
I'm excited to participate in the LLMs in Production virtual conference on June 15-16! I will be speaking about "The Emerging Toolkit for Reliable, High-quality LLM Applications". Register here to join:

4
25
131
Proud to see Databricks named a leader in the Gartner CDBMS MQ for the 3rd year, advancing in both dimensions! We’ve made so many improvements to the platform this year and we’re just getting started with data intelligence, marketplace, cleanrooms & more.

5
22
132