
Weijia Shi
@WeijiaShi2
Followers
9K
Following
4K
Media
58
Statuses
1K
PhD student @uwnlp @allen_ai | Prev @MetaAI @CS_UCLA | 🏠 https://t.co/Q6Mzg8ow2j
Seattle, WA
Joined August 2019
Can data owners & LM developers collaborate to build a strong shared model while each retaining data control? Introducing FlexOlmo💪, a mixture-of-experts LM enabling: • Flexible training on your local data without sharing it • Flexible inference to opt in/out your data

Introducing FlexOlmo, a new paradigm for language model training that enables the co-development of AI through data collaboration. 🧵
9
87
280

What happens when AI is guided by law-like principles? Can we design some computational tools to "debug" rules? Check out our new work 📝 𝕊𝕥𝕒𝕥𝕦𝕥𝕠𝕣𝕪 ℂ𝕠𝕟𝕤𝕥𝕣𝕦𝕔𝕥𝕚𝕠𝕟 𝕒𝕟𝕕 𝕀𝕟𝕥𝕖𝕣𝕡𝕣𝕖𝕥𝕒𝕥𝕚𝕠𝕟 𝕗𝕠𝕣 𝔸𝕀🧑⚖️ to find out more! 🧵(1/10)

1
13
37

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
550
645
4K
We need more reviewers for the 1s Workshop on Efficient Reasoning(ER) at @NeurIPSConf, if you are interested, please fill out the nomination form
docs.google.com
We strive to expand our reviewing pool by welcoming newer members of the community. We encourage nominations from senior community members as well as self-nominations from individuals who have either...

🌟 Announcing the 1st Workshop on Efficient Reasoning (ER) at @NeurIPSConf 2025 — Dec 6 or 7, San Diego ! 📣 We welcome submissions! Submit your work here: https://t.co/13TumRabVh 🗓️ Deadline: September 1, 2025 (AoE) 🔗 Website: https://t.co/tcTfZ6r6lS 💬 Topics

0
4
7

Can frontier LLMs solve unsolved questions? [1/n] Benchmarks are saturating. It’s time to move beyond. Our latest work #UQ shifts evaluation to real-world unsolved questions: naturally difficult, realistic, and with no known solutions. All questions, candidate answers,

13
39
244

New paper! We explore a radical paradigm for AI evals: assessing LLMs on *unsolved* questions. Instead of contrived exams where progress ≠ value, we eval LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far:

12
73
367

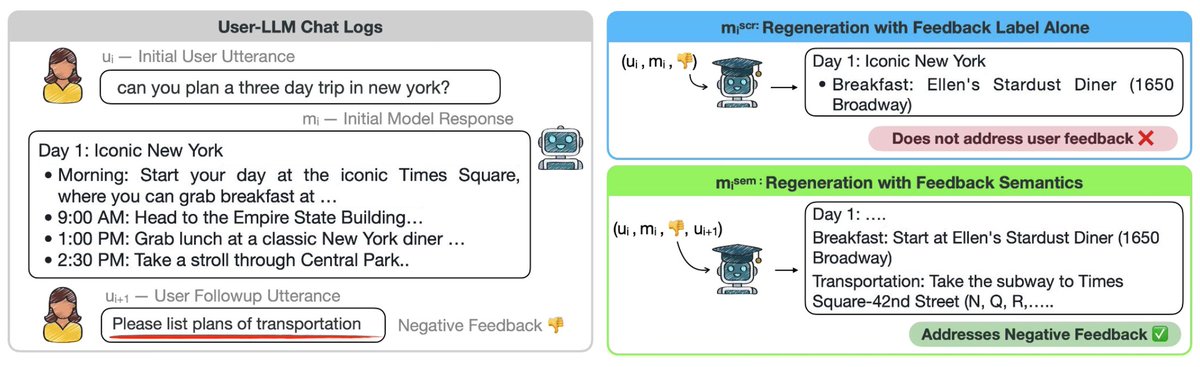
We looked into user interaction logs, searching for learning signal to improve LLMs. We find user data noisy and nontrivial to leverage, yet we learned a lot about user behaviors! See our #EMNLP25 paper.

👀Have you asked LLM to provide a more detailed answer after inspecting its initial output? Users often provide such implicit feedback during interaction. ✨We study implicit user feedback found in LMSYS and WildChat. #EMNLP2025
3
8
66

We released 44B synthetic tokens from our CoT-guided rewriting, offering higher quality pretraining data than the average human-written web texts📈 🤗Data: https://t.co/FN6X1oFPNL 📜Paper: https://t.co/78Vu89UvuD (accepted at #COLM2025) Excited to see what the community builds!

arxiv.org
Scaling laws predict that the performance of large language models improves with increasing model size and data size. In practice, pre-training has been relying on massive web crawls, using almost...
4
47
220

I'm starting to get emails about PhDs for next year. I'm always looking for great people to join! For next year, I'm looking for people with a strong reinforcement learning, game theory, or strategic decision-making background. (As well as positive energy, intellectual
2
28
247
If you're running agents in production, consider taking this short survey from my research group! We're collaborating with IBM, Stanford, UIUC, Intesa Sanpaolo and others to better understand the challenges in building agents. It only takes 5 minutes:

agents-survey.github.io
A collaboration of over 20 researchers across UC Berkeley, Intesa Sanpaolo, IBM Research, UIUC, and Stanford working on industry-grade agentic AI systems.
6
21
105

Talking about my research journey and the GLA, DeltaNet, and PaTH line of work in my first podcast ever—hope you enjoy :)

Huge thanks to Songlin Yang for coming on the Delta Podcast! Check out the podcast episode here: https://t.co/UQbvXUCeHJ

4
11
204
Come share your work at the efficient reasoning workshop @NeurIPSConf 2025 🎉 🔗:
🌟 Reminder: Submission Deadline Approaching! 🌟 The 1st Workshop on Efficient Reasoning (ER) @ NeurIPS 2025 — happening Dec 6 or 7 in San Diego — is fast approaching, and we’d love to see your work there! 📌 Submission Deadline: September 1, 2025 (AoE) 🔗 Submit here:
1
5
69
Glad to share that our paper was accepted the main EMNLP 2025 Conference! https://t.co/hTZS3Gyys2

🚨 New Paper! 🚨 Guard models slow, language-specific, and modality-limited? Meet OmniGuard that detects harmful prompts across multiple languages & modalities all using one approach with SOTA performance in all 3 modalities!! while being 120X faster 🚀 https://t.co/r6DGPDfwle

4
7
69

Been quiet here for a bit, but had to share what I just tried with Mirage 2!! 📣📣📣 I dropped in a random ❄️Game of Thrones image and suddenly I could walk around inside it with just my keyboard, then typed 🧟♂️🧟♀️ “Night King + White Walkers” and they appeared 😱 The controls

Introducing Mirage 2 — a real-time, general-domain generative world engine you can play online Upload any image—photos, concept art, classic paintings, kids' drawings—and step into it as a live, interactive world. Prompt your worlds with text to create any surreal scenes and
6
23
155

Thanks for the invite! Excited to be presenting our work on training MoE over distributed data next Monday!

We have a fun collaboration of @GPU_MODE x @scaleml coming up! We’re hosting a week-long online bootcamp that explores the core components of GPT-OSS while also diving into cutting-edge research that pushes beyond what’s currently in GPT-OSS! For example, how can MoE's power

1
5
119

Evaluating language models is tricky, how do we know if our results are real, or due to random chance? We find an answer with two simple metrics: signal, a benchmark’s ability to separate models, and noise, a benchmark’s random variability between training steps 🧵

📢 New paper from Ai2: Signal & Noise asks a simple question—can language model benchmarks detect a true difference in model performance? 🧵

3
44
233
Check out Data Swarms by @shangbinfeng: co-evolving synthetic data generators and LMs for stronger evaluations and model capability

👀 How to find more difficult/novel/salient evaluation data? ✨ Let the data generators find it for you! Introducing Data Swarms, multiple data generator LMs collaboratively search in the weight space to optimize quantitative desiderata of evaluation.

0
7
74
👀 How to find more difficult/novel/salient evaluation data? ✨ Let the data generators find it for you! Introducing Data Swarms, multiple data generator LMs collaboratively search in the weight space to optimize quantitative desiderata of evaluation.
2
17
114

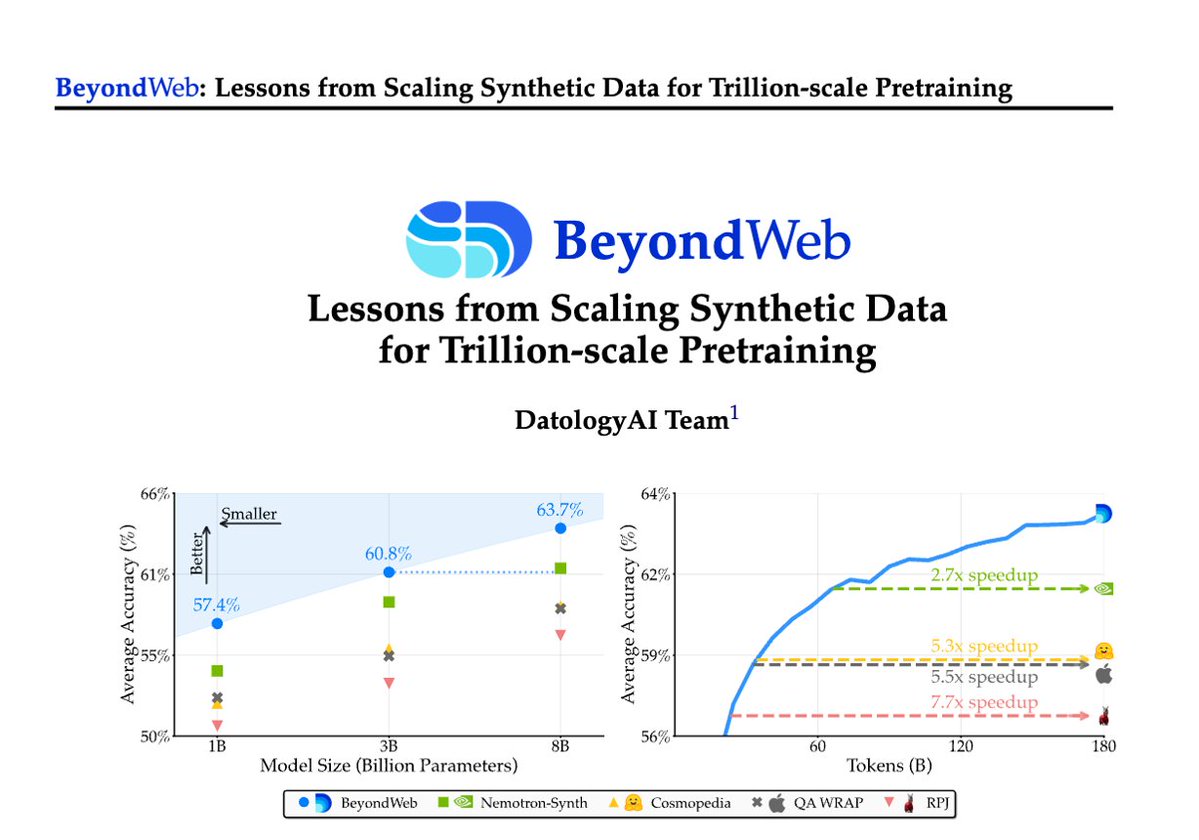
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳 - 3B LLMs beat 8B models🚀 - Pareto frontier for performance
23
125
704

I’m excited to share our new @Nature paper 📝, which provides strong evidence that the walkability of our built environment matters a great deal to our physical activity and health. Details in thread.🧵 https://t.co/omO3YcHrvG

68
712
3K

As computer-use agents (CUAs) handle critical digital tasks, open research is key to study their capabilities, risks. 🚀After a year, we release OpenCUA: 1) largest CUA dataset/tool, 2) training recipe, 3) ~SOTA model on OSWorld. Released to drive transparent,safe CUA research!


We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data. 🔗 [Paper] https://t.co/naBIDnyvYY 📌

2
26
120

This was a really fun collab during my time at @databricks !! It’s basically a product answer to the fact that: (1) People want to optimize their agents and to specialize them for downstream preferences (no free lunch!) (2) People don’t have upfront training sets—or even

Really excited about ALHF, new work from our research team that lets users give natural language feedback to agents and optimizes them for it. It sort of upends the traditional supervision paradigm where you get a scalar reward, and it makes AI more customizable for non-experts.

10
20
171