
Yuhan Liu
@YuhanLiu_nlp
Followers
465
Following
1K
Media
9
Statuses
149
CS PhD student @NYU_Courant advised by @eunsolc, previous intern @tsvetshop
NYC
Joined March 2022
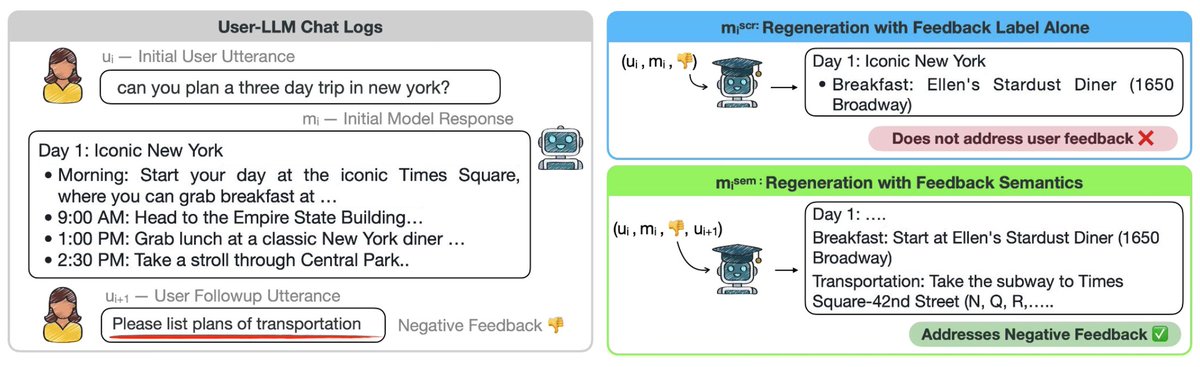
👀Have you asked LLM to provide a more detailed answer after inspecting its initial output? Users often provide such implicit feedback during interaction. ✨We study implicit user feedback found in LMSYS and WildChat. #EMNLP2025
2
21
75

🌀Diversity Aware RL (DARLING)🌀 📝: https://t.co/MH0tui34Cb - Jointly optimizes for quality & diversity using a learned partition function - Outperforms standard RL in quality AND diversity metrics, e.g. higher pass@1/p@k - Works for both non-verifiable & verifiable tasks 🧵1/5

4
81
406

We looked into user interaction logs, searching for learning signal to improve LLMs. We find user data noisy and nontrivial to leverage, yet we learned a lot about user behaviors! See our #EMNLP25 paper.
👀Have you asked LLM to provide a more detailed answer after inspecting its initial output? Users often provide such implicit feedback during interaction. ✨We study implicit user feedback found in LMSYS and WildChat. #EMNLP2025
3
8
65
Q: Can we use it to provide targeted improvement to the model? A: Depends on the evaluation domain! Finetuning with feedback semantics shows improvement on MTBench, but not on WildBench. We hypothesize that this is because WildBench has more clearly specified instructions.

1
1
4
Q: When does such user feedback occur? A: User feedback can be a result of their low-quality initial requests. We find several factors that correlate with later feedback, such as the quality of user instructions.

1
0
2

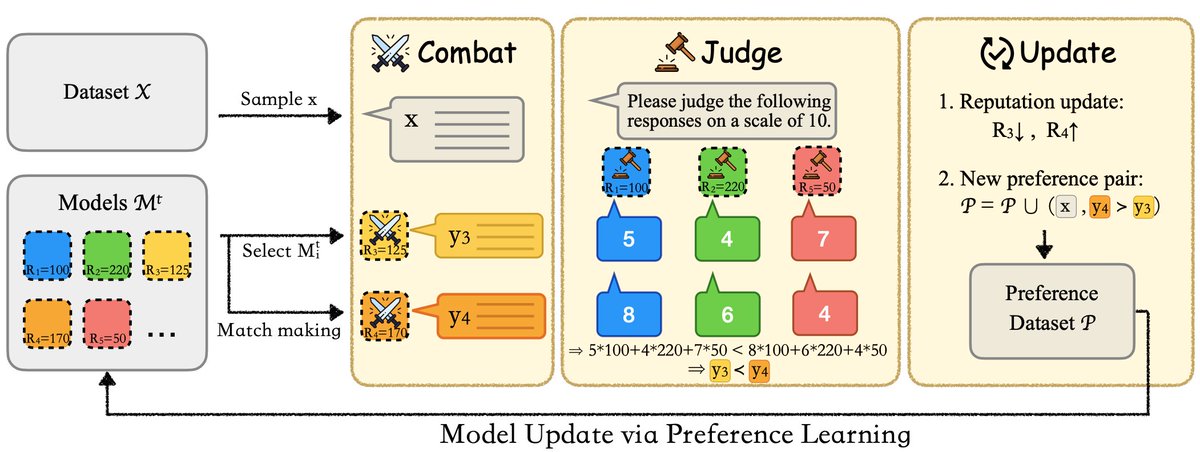
Two caveats with self-alignment: ⚠️ A single model struggles to reliably judge its own generation. ⚠️ A single model struggles to reliably generate diverse responses to learn from. 👉 Introducing Sparta Alignment, where multiple LMs collectively align through ⚔️ combat.
2
10
34
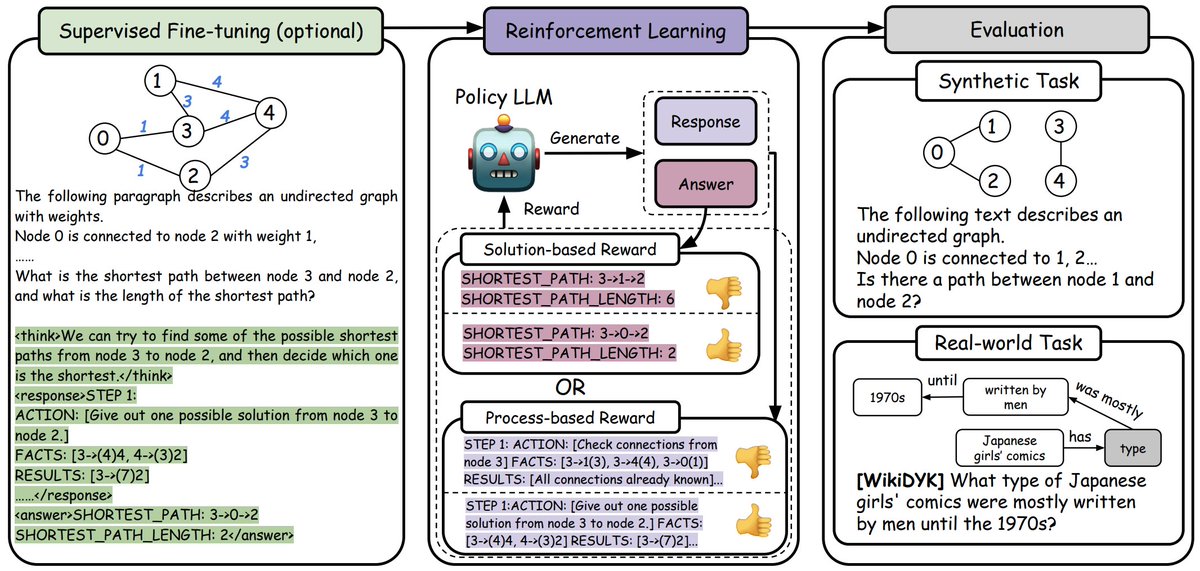
🙅 We don’t need LLMs as solvers of graph problems like shortest path. (already have Dijkstra) 🤔 What we need: learn from synthetic graphs and generalize to real-world problems with graph implications. (e.g. multi-hop QA) 💡 We unlock this generalization with alignment and RL.
2
14
74
ParaSpeechCaps has been accepted to the EMNLP 2025 Main Conference!

Introducing ParaSpeechCaps, our large-scale style captions dataset that enables rich, expressive control for text-to-speech models! Beyond basic pitch or speed controls, our models can generate speech that sounds "guttural", "scared", "whispered" and more; 59 style tags in total.

0
3
40
🔎 Can you guess these words? [answer @ end of thread] 🤔 Will VLMs decipher human creativity behind these Minecraft builds and work out the answers? 👉 Introducing GuessBench, evaluating VLM creativity understanding with data sourced from human players and real-world gameplay.


2
7
12
👀 How to find more difficult/novel/salient evaluation data? ✨ Let the data generators find it for you! Introducing Data Swarms, multiple data generator LMs collaboratively search in the weight space to optimize quantitative desiderata of evaluation.

2
17
114

📢I'm joining NYU (Courant CS + Center for Data Science) starting this fall! I’m excited to connect with new NYU colleagues and keep working on LLM reasoning, reliability, coding, creativity, and more! I’m also looking to build connections in the NYC area more broadly. Please


94
45
765
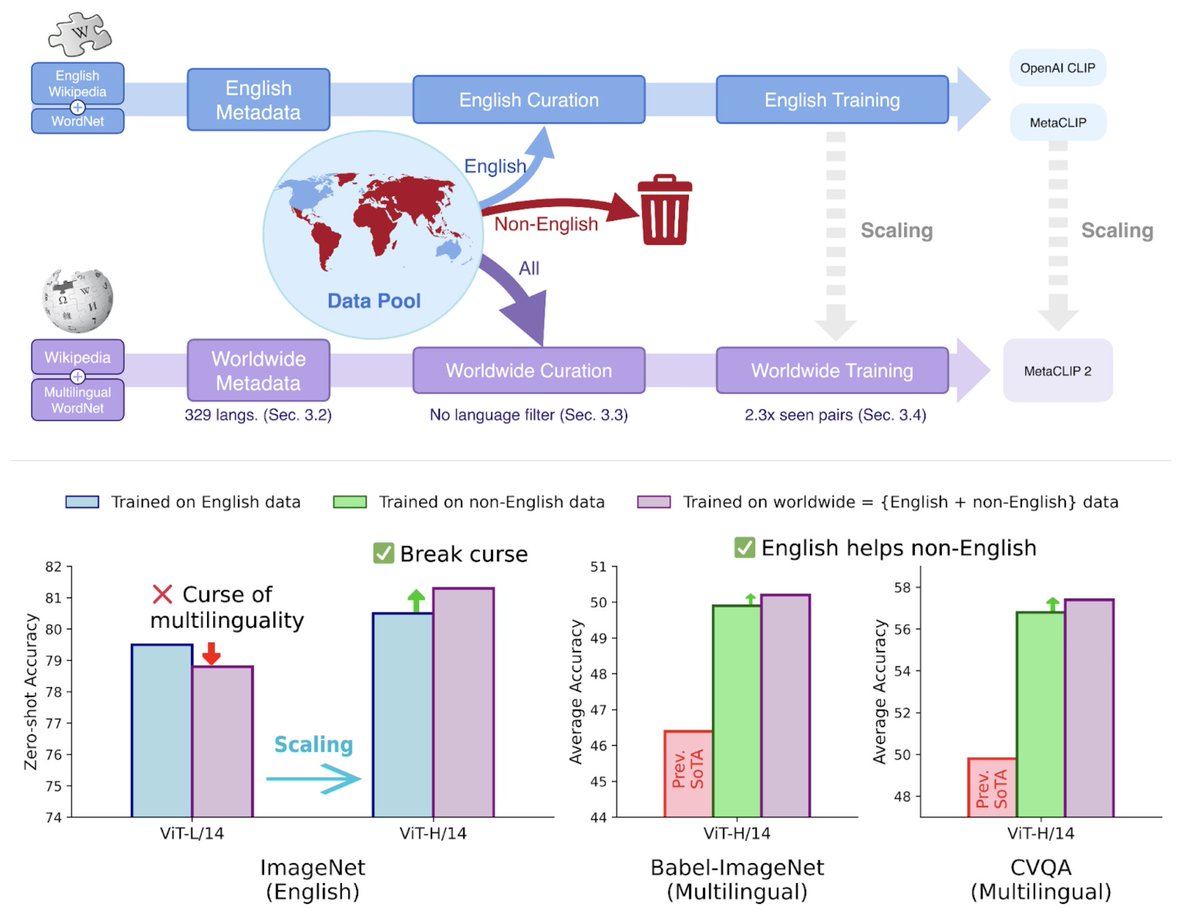
🌿Introducing MetaCLIP 2 🌿 📝: https://t.co/RyytqxRAw3 code, model: https://t.co/P0POS9E2EC After four years of advancements in English-centric CLIP development, MetaCLIP 2 is now taking the next step: scaling CLIP to worldwide data. The effort addresses long-standing
14
68
331

BREAKING NEWS! Most people aren’t prompting models with IMO problems :) They’re prompting with tasks that need more context, like “plz make talk slides.” In an ACL oral, I’ll cover challenges in human-LM grounding (in 60K+ real interactions) & introduce a benchmark: RIFTS. 🧵

5
52
273
At #ACL2025 this week! Please come check out our poster 11:00a.m. to 12:30p.m. today at Hall 4/5.

Can we generate long text from compressed KV cache? We find existing KV cache compression methods (e.g., SnapKV) degrade rapidly in this setting. We present 𝐑𝐞𝐟𝐫𝐞𝐬𝐡𝐊𝐕, an inference method which ♻️ refreshes the smaller KV cache, which better preserves performance.

1
4
36
I'll be at ACL Vienna 🇦🇹 next week presenting this work! If you're around, come say hi on Monday (7/28) from 18:00–19:30 in Hall 4/5. Would love to chat about code model benchmarks 🧠, simulating user interactions 🤝, and human-centered NLP in general!

When benchmarks talk, do LLMs listen? Our new paper shows that evaluating that code LLMs with interactive feedback significantly affects model performance compared to standard static benchmarks! Work w/ @RyanShar01, @jacob_pfau, @atalwalkar, @hhexiy, and @valeriechen_! [1/6]

1
5
52

Novel cognitive science grounded approach to preference modeling: synthetic counterfactual training + attention-based attribute integration. Empirical validation across 45 communities with human evaluation confirming interpretability claims! 🌟

WHY do you prefer something over another? Reward models treat preference as a black-box😶🌫️but human brains🧠decompose decisions into hidden attributes We built the first system to mirror how people really make decisions in our #COLM2025 paper🎨PrefPalette✨ Why it matters👉🏻🧵

0
4
8

Talking to ChatGPT isn’t like talking to a collaborator yet. It doesn’t track what you really want to do—only what you just said. Check out work led by @jcyhc_ai and @rico_angel that shows how attackers can exploit this, and a simple fix: just look at more context!

LLMs won’t tell you how to make fake IDs—but will reveal the layouts/materials of IDs and make realistic photos if asked separately. 💥Such decomposition attacks reach 87% success across QA, text-to-image, and agent settings! 🛡️Our monitoring method defends with 93% success! 🧵

2
7
27

🤔Now most LLMs have >= 128K context sizes, but are they good at generating long outputs, such as writing 8K token chain-of-thought for a planning problem? 🔔Introducing LongProc (Long Procedural Generation), a new benchmark with 6 diverse tasks that challenge LLMs to synthesize


3
49
220

📢 (1/16) Introducing PaTH 🛣️ — a RoPE-free contextualized position encoding scheme, built for stronger state tracking, better extrapolation, and hardware-efficient training. PaTH outperforms RoPE across short and long language modeling benchmarks https://t.co/nJItUuYKWZ

arxiv.org
The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for...
9
92
542