

Sam Havens
@sam_havens
Followers
2K
Following
5K
Media
17
Statuses
239
Nandan consistently putting out great datasets!.

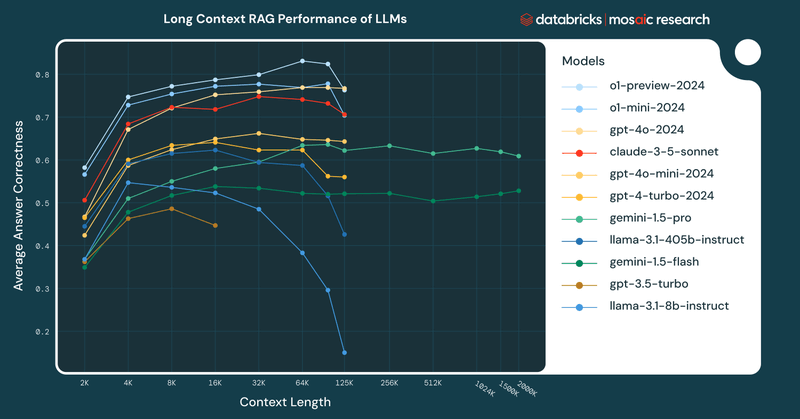
Existing IR/RAG benchmarks are unrealistic: they’re often derived from easily retrievable topics, rather than grounded in solving real user problems. 🧵Introducing 𝐅𝐫𝐞𝐬𝐡𝐒𝐭𝐚𝐜𝐤, a challenging RAG benchmark on niche, recent topics. Work done during intern @databricks 🧱
0
1
1
calling it "minions" is so funny lol. I hope that term catches on as a generic name for a small local subtask spawned by an agent.

How can we use small LLMs to shift more AI workloads onto our laptops and phones?. In our paper and open-source code, we pair on-device LLMs (@ollama) with frontier LLMs in the cloud (@openai, @together), to solve token-intensive workloads on your 💻 at 17.5% of the cloud cost
1
3
17
RT @DbrxMosaicAI: New blog post! @quinn_leng, @JacobianNeuro, @sam_havens, @matei_zaharia, and @mcarbin have released part 2 of our investi….
databricks.com
0
19
0
RT @DbrxMosaicAI: Function calling significantly enhances the utility of LLMs in real-world applications; however, evaluating and improving….
0
11
0
RT @dan_biderman: *LoRA Learns Less and Forgets Less* is now out in its definitive edition in TMLR🚀 Checkout the latest numbers fresh from….
0
20
0
RT @rajammanabrolu: This is also why trying to do LLM agents without optimizing at a sequence level (many current tool use works) does not….
0
1
0
low hanging fruit when using llm-as-judge.

How can you make LLM-as-judge reliable in specialized domains? Our applied AI team developed a simple but effective approach called Grading Notes that we've been using in Databricks Assistant. We think this can help anyone doing domain-specific AI!
0
0
7
RT @gupta__abhay: The new Llama-3.1 base models are pretty much the same as the old one, barring the multilingual + extended context length….
0
10
0
RT @ZackAnkner: New paper where we explore using a small LM’s perplexity to prune the pretraining data for larger LMs. We find that small….

arxiv.org
In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing...
0
62
0
RT @dan_biderman: People think LoRA is a magic bullet for LLMs. Is it? Does it deliver the same quality as full finetuning but on consumer….
0
106
0
RT @mattshumer_: One of the more interesting things about the new DBRX model is it uses the GPT-4 tokenizer. Compared to the LLaMA tokeniz….
0
11
0
very lucky to have such an amazing wife who bore the brunt of all the work I did over the last few months. love you @celletheshell excited to see you more.
DBRX is a 16x12B MoE which was trained for 12T tokens at a final context length of 32k. I and my team have been fine tuning it and I am sure that the community is going to love this one, it's got great vibes.
0
0
25
RT @srush_nlp: Underrated LLM research challenge: make Chatbot Arena super-fun. Cute mascot, level up screens, fireworks, daily quests. The….

lmarena.ai
An open platform for evaluating AI through human preference
0
10
0

DBRX is a really strong model and Instruct just scratches the surface of what we can do with it. However, it's also incredible given our short time with the base model. Expect even better iterations from the team: @alexrtrott Brandon Cui @rajammanabrolu @pkyderm @KartikSreeni.
0
0
9
It's also a very strong coder. I hooked it up to an eval() loop on my laptop (w/o sanitation, yolo right?) and it was able to solve much harder reasoning problems than w/o access to code. Can't wait to explore this direction further!.
1
0
8
DBRX Instruct is the current result of that fine tuning. It is a very strong instruction-following model with good system prompt fidelity. @alexrtrott can take credit for that :) It should do a very good job in pipelines where it plays a role as a fictional character or assistant.
1
0
3
DBRX is a 16x12B MoE which was trained for 12T tokens at a final context length of 32k. I and my team have been fine tuning it and I am sure that the community is going to love this one, it's got great vibes.

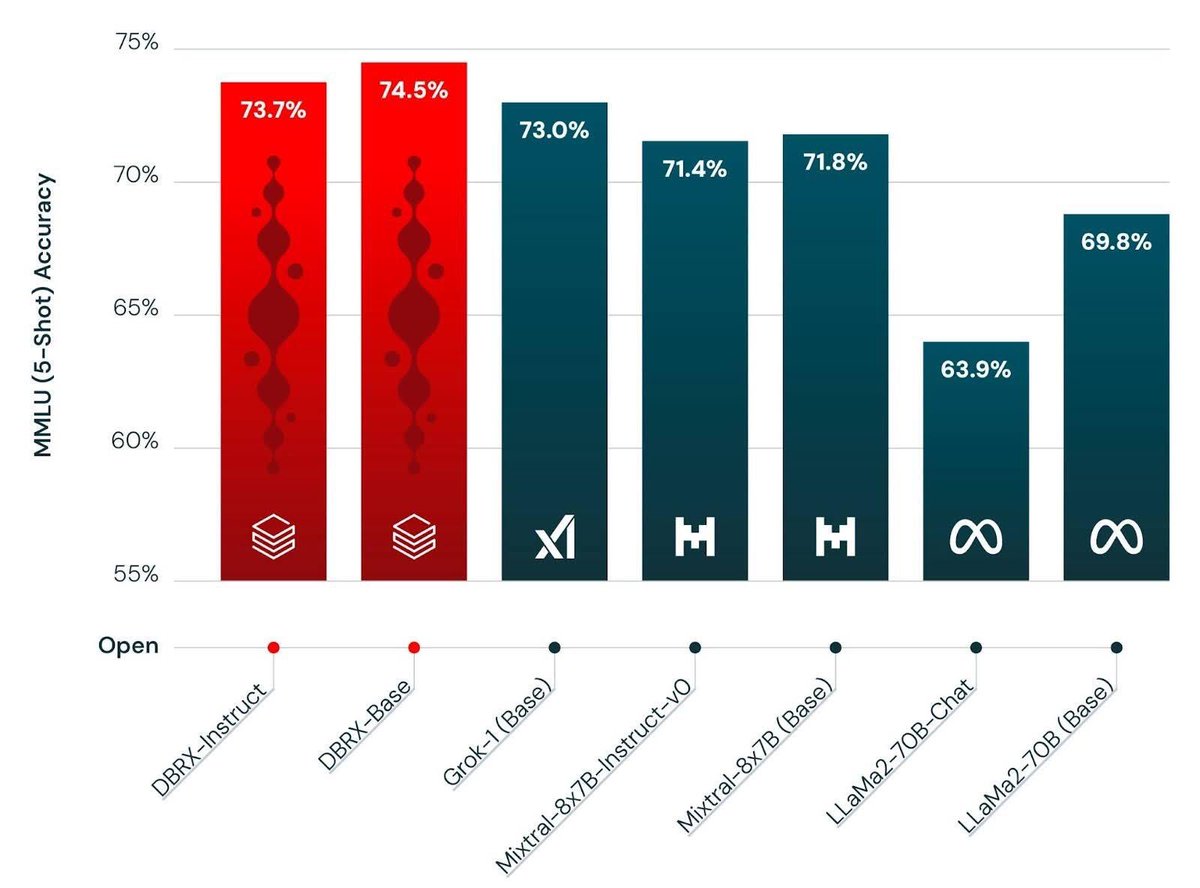
It’s finally here 🎉🥳. In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
3
8
42