
Moin Nadeem
@moinnadeem
Followers
2,180
Following
986
Media
451
Statuses
16,799
Co-Founder at Phonic. Previously @Stanford CS PhD Dropout, @MosaicML , CS @MIT . I tend to be wrong, but the learning process makes it enjoyable. 🇵🇰🇺🇲
San Fransisco Bay Area
Joined October 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Northern Lights
• 146703 Tweets
オーロラ
• 138107 Tweets
#aurora
• 110495 Tweets
Knicks
• 77770 Tweets
Pacers
• 53547 Tweets
#solarstorm
• 49138 Tweets
BECKY X MAYBELLINE LIVE
• 46350 Tweets
Game 4
• 42641 Tweets
#REBECCAPINKLOVELIVE
• 36133 Tweets
Ushuaia
• 34536 Tweets
Brunson
• 34368 Tweets
melanie
• 33784 Tweets
Timberwolves
• 31299 Tweets
BUMP
• 27511 Tweets
#キントレ
• 26768 Tweets
Protection Campaign
• 23752 Tweets
HBD LINGLING KWONG
• 22705 Tweets
#MenolakLupa271T
• 18746 Tweets
UsutTuntasRBT UsutRBS
• 18602 Tweets
Nembhard
• 16705 Tweets
Hughes
• 16321 Tweets
バチコン
• 11918 Tweets



















Pinned Tweet

As pretrained language models grow more common in
#NLProc
, it is crucial to evaluate their societal biases. We launch a new task, evaluation metrics, and a large dataset to measure stereotypical biases in LMs:
Paper:
Site:
Thread👇


4
21
71
What are the improvements over a standard Transformer?
- Gated Linear Units (Shazeer, 2020)
- Multi-Query Attention (Shazeer, 2019)
- Mixture of Experts (Shazeer, 2017)
Wait, is it just me, or am I noticing a pattern? 😉
19
29
451
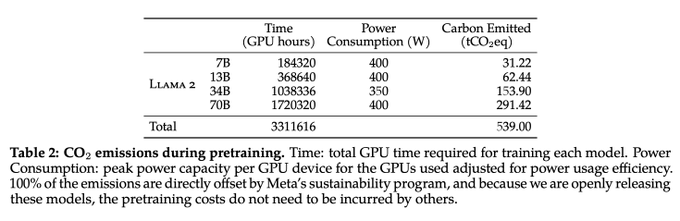
This is an important plot from the LLaMa 2 paper. It directly outlines the pre-training hours for the model!
Costs below, assuming $1.50 / A100 from
@LambdaAPI
:
- the 7B model cost $276,480!
- the 13B model cost $552,960!
- the 34B model cost $1.03M!
- the 70B model cost $1.7M!
11
33
246
It's under-discussed how a lot of people are largely just a function of their environment
My friends in Boston are interested in becoming professors.
My friends in Bay Area PhD programs are either interested spending their life in industrial research labs, or going into…
8
4
151
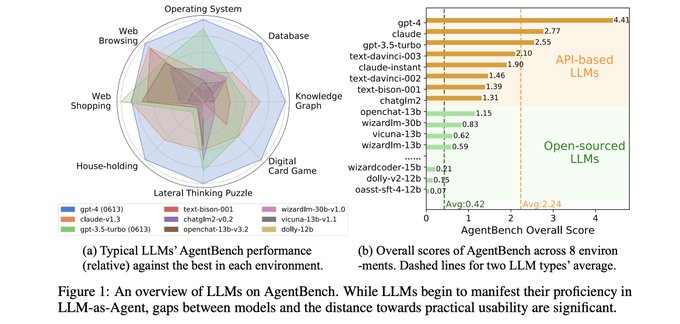
One of my favorite ways to evaluate LLMs is to evaluate them on unreleased tasks.
It's the perfect test set! The task didn't even *exist* at the time the LLM was trained.
AgentBench () evaluates 25 LLMs and shows there remains a significant gap between…
5
27
148
Fun fact: our training setup is wired to my room's lighting system. If a job fails in the middle of the night, my lights turn on and I wake up to fix it.
You really do have to be on call all the time.

there is no way the 9-5, strict 40 hour 5-day week is a workable schedule for anyone training LLMs or being involved in this.
it's a sport. you have to be on call all the time.
7
5
96
11
0
126
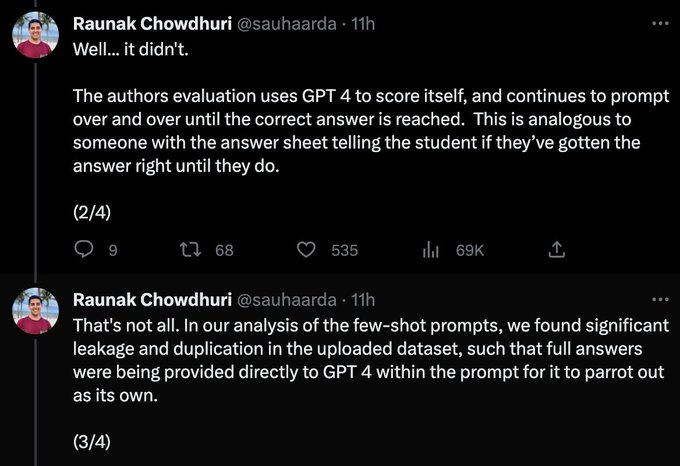
Now that ML research is hype, people really have no clue what they are talking about anymore.
(1) This is a paper led by undergraduates. The institution has no role in it. This is about a couple of 20 year olds who probably got a little too excited about their results.

Researchers at MIT wrote a paper claiming GPT4 scored 100% on MIT's EECS curriculum.
Turns out they were just prompting GPT4 again & again till it gave the right answer.
That's not all. They actually uploaded full answers within the prompt!
Very, very dishonest. This is MIT -…

76
571
3K
5
2
99
New AACL paper!
Sampling from a language model is a crucial task for generation. While many sampling algorithms exist, what properties are desirable in a good sampling algorithm? 🧐
Joint work w/
@TianxingH
,
@kchonyc
, Jim Glass, and I
Paper:
Thread 👇

2
13
79
My heart goes out to ORU students for their Intruder on Campus earlier today. Truly heartbreaking.
2
28
68
Hot take: Starting with an enterprise-first go-to-market motion in this current AI era is a mistake.
We're in a period where enterprises have no clue what they want. If you listen to them, you'll only be confused.
Cater to the best developers and the enterprises will follow.
4
2
72
EDIT: thanks to
@appenz
for pointing out a mistake on the 34B and 70B parameter models 🙂
Costs below, assuming $1.50 / A100 from
@LambdaAPI
:
- the 7B model cost $276,480
- the 13B model cost $552,960
- the 34B model cost $1.56M
- the 70B model cost $2.6M
This is an important plot from the LLaMa 2 paper. It directly outlines the pre-training hours for the model!
Costs below, assuming $1.50 / A100 from
@LambdaAPI
:
- the 7B model cost $276,480!
- the 13B model cost $552,960!
- the 34B model cost $1.03M!
- the 70B model cost $1.7M!
11
33
246
0
11
71
After a few years at MIT, I started realizing that the people I admired the most didn't voice their opinion on every matter, but rather only voiced their opinion when their opinion mattered. They were happy to admit they weren't qualified to speak up.
0
8
71
💯
The model isn't the moat. Once your business hits PMF, stop giving your margins to
@OpenAI
and train your own GPT-3 using
@MosaicML
.

@martin_casado
@moinnadeem
@hausdorff_space
This shows that LLMs act as databases. The contents of the DB is the training data. It's crucial to build models on your own data to have level of predictability of the outputs...
2
4
27
1
3
67
After getting 'randomly checked' at the airport three times in a row, I've started to wonder how random these checks actually are for the Pakistani Muslim who travels a lot.
I pay for TSA Precheck so I can avoid these things and I'm a US citizen. What more do I have to do?
6
0
50
Dream big kids, and when you don't reach that goal, slip in a $20 bill and a "please" with your exam.

6
1
49
Finally! Someone brings encoder-decoder models back! I'm so excited about this.

Along with Core, we have published a technical report detailing the training, architecture, data, and evaluation for the Reka models.


2
61
370
3
3
51
Jenks High School, it's been a ride. Thank you for letting me be part of it.

2
6
48
@zacharylipton
Hi Professor Lipton! Undergrad here who really benefited from . Quick question: some advise writing the abstract last, since your story in the paper may change as you write it. Do you have any thoughts / advice? I noted you listed it first
3
11
47
Honestly, I feel like COVID took away a little bit of my love of research. I loved working with people in-person on challenging problems, and discussing with my elders whenever I got stuck. Now, the loneliness of research feels even worse under quarantine.
2
0
41
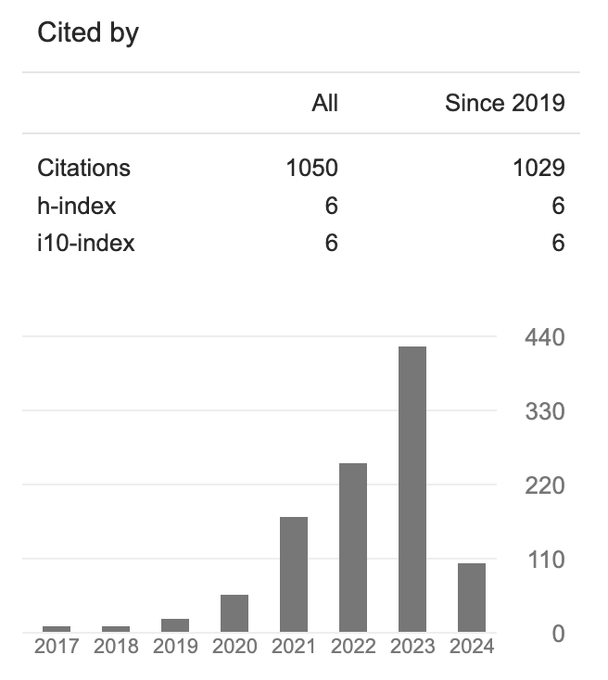
It doesn't matter for me anymore, but a fun milestone to hit 1k citations :)
1
0
38
Does anyone know of a single example of recursive self-improvement actually working in LLMs? How does this not yield diminishing returns?
As number of recursive steps tends towards infinity, I'd claim that you aren't capturing new parts of the distribution to actually change…

The new CEO of Microsoft AI,
@MustafaSuleyman
, with a $100B budget at TED:
"AI is a new digital species."
"To avoid existential risk, we should avoid:
1) Autonomy
2) Recursive self-improvement
3) Self-replication
We have a good 5 to 10 years before we'll have to confront this."

250
144
923
15
4
38
Often, take the exact same person and transplant them in a different environment, and they'll go down a different path. Paul Graham hints at this in his "Cities" essay:
@RichardSocher
said he started his PhD program wanting to be a professor, but started…
0
1
35
(2) This is why peer review exists! Just because it's a paper doesn't mean it is any good. The important part is that the community caught on and verified or deconstructed claims extremely quickly.
That actually makes me feel better!
1
1
35
Looking back, Boston really is a wonderful city to live in, and especially to spend your college years.
1
0
35
@sharifshameem
> computers can make us feel things now
buddy have you never wanted to chuck your computer across the atlantic when debugging code before??
1
1
34
Incredibly excited for my first research paper to be published at the Cornell University Library!
6
7
33
5 months ago, I quit my job to join
@NaveenGRao
,
@hanlintang
, and
@jefrankle
on a mission to make ML training more efficient. Since then, we've made progress on our mission, and our results are publicly available for everyone to inspect.

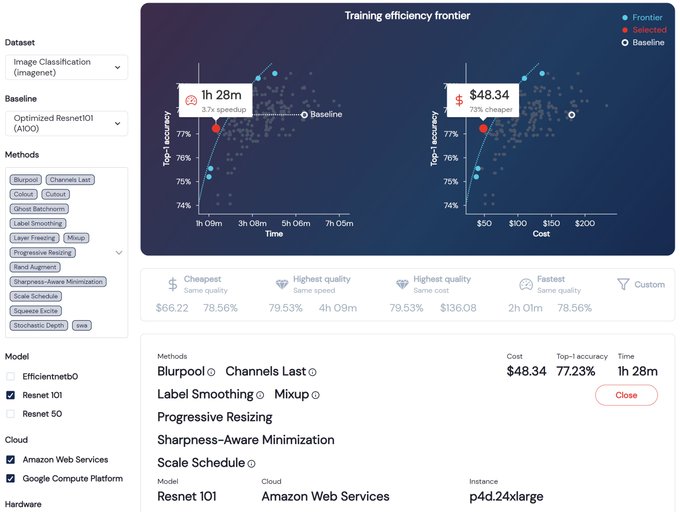
Hello World! Today we come out of stealth to make ML training more efficient with a mosaic of methods that modify training to improve speed, reduce cost, and boost quality. Read our founders' blog by
@NaveenGRao
@hanlintang
@mcarbin
@jefrankle
(1/4)
7
41
164
2
3
33
Tonight, we explored Boston by rooftops, did intense math on napkins, and grabbed Mexican soul food at 3AM.
Needless to say, I love it here
2
0
32
One of the problems with tech is that it provides a (relatively) large sum of wealth to relatively young people, who then get overconfident about their general problem-solving abilities and intelligence.
2
4
32
I can't believe that these hackers control Heads of State, major CEOs, and all they did was run a Bitcoin scam.
1
0
32
Always sad that people from my high school choose to spread around the anti-vax movement; they should know better, and I understand the good intentions, but its just misinformation that is being spread.
0
1
31
For current MIT students: if you're interested in machine learning and efficiency,
@MosaicML
will be on campus next week giving a talk about our work! See the FB event for more:

0
3
31
Wow, ChatGPT is pretty good! This furthers my belief that we'll be moving towards domain-specific models soon, and there won't be "one model to rule them all" for a lot longer.
We had our model-itis era, and now we're realizing that the (potentially human) data is important too.
5
1
31
@dblalock_debug
If you include that Noam was on the Transformer paper (which had a randomized author order), his impact on the field is almost unbelievable.
Remove Noam from modern AI and it actually looks measurably different!
2
0
31
Wanted to add this to the thread for visibility:
@jeremyphoward
has a good point: Dauphin et al, 2016 invented the GLU unit, and Noam just brought them to the Transformer.

@moinnadeem
GLU was Dauphin et al (2016) - Shazeer just added them into the transformer arch. (They were originally used as an LSTM cell replacement in an RNN.)
1
0
26
0
0
31
> After the war, Robert Oppenheimer remarked that the physicists involved in the Manhattan project had "known sin". Von Neumann's response was that "sometimes someone confesses a sin in order to take credit for it."
Interesting to think about in today's times :)
0
10
30
Got my car broken into after ~2 months of living in SF. I don't have any particularly unique thoughts here, but I wish the city could just be better about this. Feeling some level of personal safety and trust is a large quality of life difference.
2
0
29
S/O TO OUR TU PRESIDENTIAL SCHOLARS (full ride, room, board, everything is covered)
@connerbender
and
@juliarichardso
!!
0
2
28
@davidmarcus
@TaylorLorenz
Is this really the solution? Why not still be happy about your gains but then go spend part of them ordering takeout from your local small business? Do these things have to be mutually exclusive?
2
2
25
0
0
28
@agihippo
i mean there's a ton of research questions (unify diffusion and auto-regressive objectives, conditional computation, recurrence), but everyone is chasing "being the best LLM" rather than trying to push the frontier
1
0
26
Poli Sci professor to room full of MIT students: "anyone know how to work this computer? Any tech people in here?"
everyone: "lol"
2
1
22
Ramadan Mubarak :)
If I have been rude or hurtful towards anyone over the past year, please accept my apologies and forgive me. Excited to start this holy month with a fresh start
1
0
24
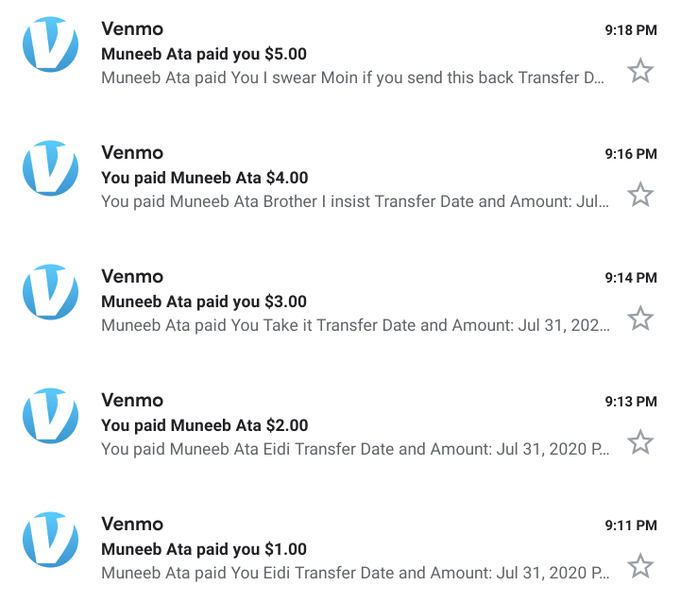
How do you recognize a true friend? It's the one that fights with you over Eidi.
Miss you bhai
@MuneebAta
1
1
23
Is anyone else finding it really difficult to be productive after being home for so long? I'm regressing to quite a bit of daily netflix.
1
0
23
I can attract 22,000 people to a website in a single day, but can't nab that last point on my ACT. C'mon, that's gotta count for something.
1
2
21
@TheDapperDr
@ImGreenGuru
@FatimagulHusain
To be clear, it's a group of Muslims to hang out with at MIT (we're all students). Let's not make it anything more than a community, no need to politicize it.
1
0
21
If you thought your Secret Santa was good, I feel bad for you son.
I got 99 problems, but Whitney Mitchell ain't one



0
2
20
The high-level bit on success in AI is whether hallucination is harming you or helping you.
For Midjourney, Character, and others: hallucination is a feature, not a bug. The model isn't lying, it's ✨ creativity ✨.
For enterprise knowledge applications, hallucination is the…
2
0
20

It's surprising this product didn't exist until now.
Everything we do at work is real-time and collaborative... except coding.
Replit Teams is a real-time layer atop Git where branches are live; you can see what your coworkers are doing and branch in and out super fast.
Best…
35
51
991
0
0
19
This was a blast, thanks Charlie!
We chatted about language modeling, automated fact checking, and my love of CSAIL! Charlie is also an excellent host who has a wonderful charm that puts people at ease.

🚨 New ML Engineered 🎙 episode with
@moinnadeem
!
✅ Why language models in the future will be extraordinary 🚀
✅ Building automated fact-checking pipelines
✅ How the MIT CS & AI Lab is so prolific
👇Thread with best quotes and takeaways👇
(Link at the end)

1
1
5
0
2
20
Clearly she didn't use TurnItIn

2
3
19


Got pics back from me killing my presentation at MIT. I highly urge you to apply, its free:



1
1
17

I started my research career four years ago, and as pre-trained models grew in importance, so did my level of frustration.
Most interesting research questions were surrounded in a shroud of inaccessibility! The sesame street of BERTs really excited me, but I couldn't anything.

TLDR: Announcing 🌟COMPOSER🌟, a PyTorch trainer for efficient training *algorithmically*. Train 2x-4x faster on standard ML tasks, a taste of what's coming from
@MosaicML
. Star it, 𝚙𝚒𝚙 𝚒𝚗𝚜𝚝𝚊𝚕𝚕 𝚖𝚘𝚜𝚊𝚒𝚌𝚖𝚕, contribute, be efficient!
Thread:
8
79
383
2
1
19
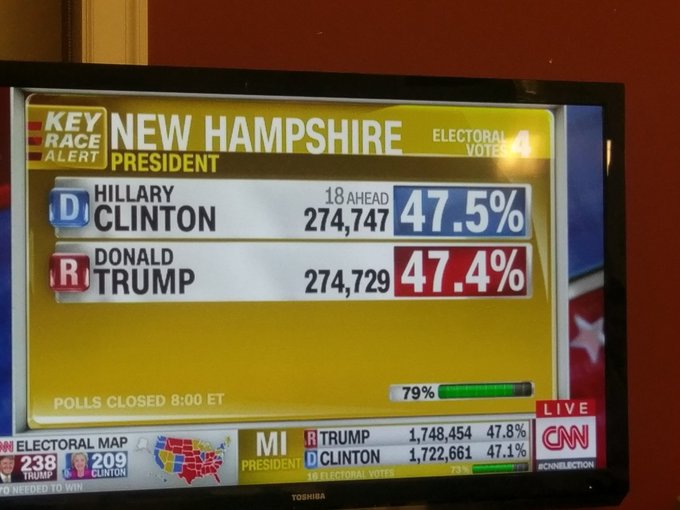
A strong narrative in 2016 was that the country didn't love Trump, but not enough people voted to show that.
In 2020, the election is still so close despite a record-shattering turnout. America has some work to do.
1
2
19
It's interesting a lot of the goals people set for themselves coincide with the core tenents of Islam.
Donating 3% of income to charity -> Zakat
Taking some time daily to meditate and reflection -> 5 prayers a day for Muslims
Intermittent fasting to improve health -> Ramadan
2
2
19
Reference to how many Muslims there are, versus how many are actually terrorists. Great chart to visualize it
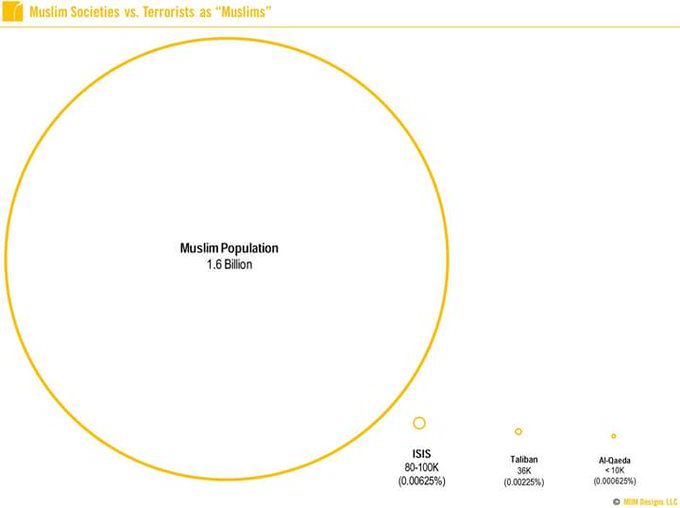
1
14
18
@pitdesi
> It costs an extra $786 a year to cover window damage in SF.
I've just paid out of pocket. My window replacements have usually been ~$200 so the math works out.
2
0
19
AP Stat sub: "What's your name?"
Me: "Moin"
"You're not in this class..."
"Oh I know. I'm not in many of my classes."
*confused expression*
0
0
19
I was thinking about this, and reformulating Twitter's social graph into an interest graph is really the way to go. Develop a "for you" page like a deck of cards that notices what you're (temporally) interested in and recommends more. Can also enable a "freshness" boost.
I wish GPT-3-like temperature slider could exist on social feed algorithms for when your feed needs some freshness.
1
3
35
3
1
18
I gotta say,
@rajko_rad
is a class act. He acts with integrity and really cares for his friends in a way that is rare in SV. Really, a wonderful human being.
3
0
18
For the claim that "foundation models" lock academia out of pretraining: why can't you train a few small (~50 - 150M) parameter models and show pareto optimality over an existing model, since scaling laws should extrapolate that pareto optimality to larger models as well?
5
1
17
MIT frat dinners are where you start by talking about gains and somehow end up talking about whether math is a subset of the universe or not
2
0
18
Can we start a rumor that Muslims hate donuts so that we can get free donuts sent to the Mosque every Friday?
0
3
18
A little late, but extremely honored to win the one of best Undergraduate Research projects at MIT: .
Thankful for everyone that got me here, and can't wait to release FAKTA in the future iA!
0
1
18
My classmates who spent winter break at home are unable to come back thanks to Donald Trump
1
5
16
I feel like senior year second semester is just one huge waiting game for college
0
5
17
Huh, I copied pasted values from a table and multiplied them by 1.5.
And got 33k views / 100 likes.
Are we at peak AI hype yet?
This is an important plot from the LLaMa 2 paper. It directly outlines the pre-training hours for the model!
Costs below, assuming $1.50 / A100 from
@LambdaAPI
:
- the 7B model cost $276,480!
- the 13B model cost $552,960!
- the 34B model cost $1.03M!
- the 70B model cost $1.7M!
11
33
246
3
0
18
@anaganath
All of these are great! Big fan of each one.
but FlashAttention isn't an architectural improvement, it's a hardware-cognizant implementation.
S4/S5/Hyena are alternative architectures!
I should have been more precise: one of the few people to *improve* upon a Transformer is…
2
0
17

Upside: I started swimming every day and I feel great
Downside: man the chlorine is really wrecking my hair
2
0
17
There's the dude who created MasteringPhysics sitting right in front of me telling me how many students love their digital textbooks
5
1
17
2018 Review:
🎓 Vastly improved my grades from my first year
🎉 Published a paper in a workshop (2019: conference?)
😍 Found life-long friends
📕 Finished 5 books
0
0
17
I wish more of my peers understood this: the world is complicated, and generally speaking, a software engineer likely does not know more about some wide societal problem than an expert. If you do: go and do their job, it'll likely be much more impactful.
1
1
17
I've realized that growing up in a family that ran a small business really forced me into a customer obsessed mindset.
If, even as a 10 year old working the cash register, your parents perpetually remind you to make the customers happy, then it sticks with you as an adult.
1
0
16
I'm approaching the time in my life where I'm deciding whether I want to do meaningful work, or make a shit ton of money.
4
5
15
Every bright undergrad researcher that I know is pivoting from *ACL / ML conferences to MLSys. Sign of the times.
0
0
16
MIT is only letting back seniors for the fall. I miss the vibrancy of a college campus, and I'll miss all of the escapades that you get to do with your friends. Hoping a COVID vaccine comes out soon.
0
0
16
My crowning achievement in life so far is that I haven't caved in and downloaded Pokémon Go yet.
4
1
16
One of my friends made his final project a scientific study on the optimal method to shotgun a beer, and I can't stop laughing
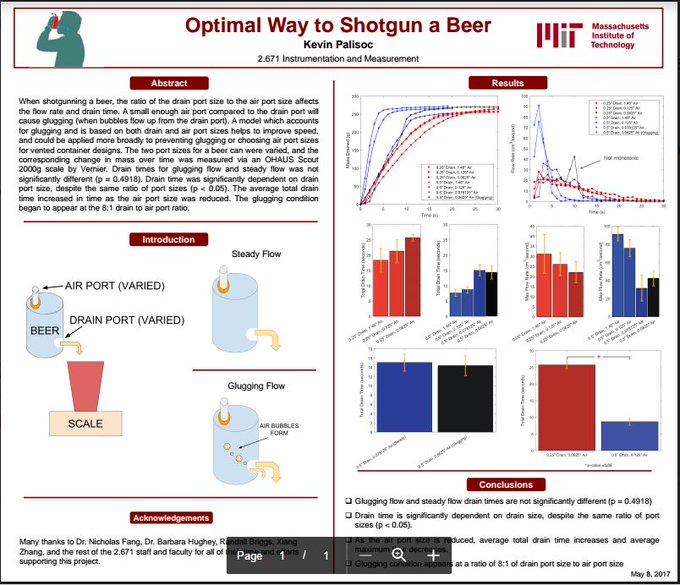
0
0
15
I don't advocate for abolishing guns, but 92% of Americans support stronger background checks, as do I.
0
3
16
Taking performance engineering in undergrad has been ~10x more fruitful for me than all of those math classes that I took.
3
0
16
There's a great joy in seeing your friends fulfill their dreams. Many congratulations to the
@gather_town
team! Well deserved
@_npfoss
@k_m_y_l
@michaelssilver

Excited to announce that
@gather_town
has raised a $50M Series B led by
@sequoia
and
@IndexVentures
, with participation from
@zoink
,
@jeffweiner
,
@ycombinator
!
Given all the Metaverse talk lately, we wanted to elaborate on what this means to us:
45
110
913
0
0
15
Dear person running
@complimentjhs
this year,
I couldn't be more proud of you. Keep up the good work.
1
1
15
@MartinaFOX23
None of the other schools hacked Snapchat to make a story JUST for the State Game. No one does it better than the Jenks family
1
2
15