

Baseten
@basetenco
Followers
4K
Following
2K
Media
415
Statuses
1K
DeepSeek-V3 dropped today and the LLM world just got turned upside down. Again. Early indicators are that this model completely transforms the closed and open-source model landscapes. Tl;Dr - OSS is now SOTA/Top3 again. Here are the key details to know:. - Open source and
21
109
692
DeepSeek-R1 is blowing up right now, but we're not surprised. And not just because we’ve been working closely with @deepseek_ai to bring these models to production. We've been betting on powerful, open-source models like DeepSeek-R1 from day one. 1/n 🧵
20
71
574
We’re excited to launch Meta’s Llama 3 in our model library, in both 8B and 70B 🎉. The newly introduced Llama 3 is a significant improvement over Llama 2, with increased tokens, and reduced false refusal rates. These models deliver unparalleled performance, showcasing.
7
23
237
🎉 We’re really excited to be announcing BaseTen today. BaseTen is the fastest way to build applications powered by machine learning. Check it out yourself!.
4
51
222
🍮 FLAN-T5 fine-tuning is now available on Blueprint!. Sign up, try it out, and show us what you build below - we’ll be giving away swag to some of our favorites next week:
2
17
166
"Panicking about privacy for DeepSeek only makes sense if you don't run the model in the US or EU. Models can't magically transport data out of your VPC unless you're not running them in your VPC." - @tuhinone . Want more takes from people who actually deploy models instead of

10
16
147
We're excited to announce that we've raised a $40M Series B to help power the next generation of AI-native products with performant, reliable and scalable inference infrastructure.
12
18
112
We’ve updated our evaluation of the best open source LLMs and—spoiler alert—Llama 3 70B Instruct tops the list. Our complete recommendations:.
1
4
69
We’re launching something big — meet Blueprint. . Blueprint is the fastest way for developers to fine-tune and integrate generative models into their APIs.
2
10
72
Exciting news—we made Baseten available to everyone starting today 🥳. Baseten lets data scientists turn ML models into full-stack web apps in minutes. So you can translate ML into business value. How about a quick tour?.
1
19
60
We have day 0 support for #Qwen3 by Alibaba Qwen on Baseten using SGLang. Qwen 3 235B's architecture benefits from both Tensor Parallelism and Expert Parallelism to run Attention and Sparse MoE efficiently across 4 or 8 H100 GPUs depending on quantization. More in 🧵

4
12
50
The first Baseten bot is live on Poe! It's very fast, you can ask questions in your language of choice and get instant answers. We're excited to partner with Quora to power the fastest open-source models for the Poe community!
3
10
44
Launching today 🎉. Double your throughput or halve your latency for @MistralAI, @StabilityAI + others?. Do both at ~20% lower cost with @nvidia H100s on Baseten. Here’s how 👇.
2
16
39
🚀 New Generally Available Whisper drop: The fastest, most accurate, and cost-effective transcription with over 1000x real-time factor for production AI workloads. 🚀. Our new Generally Available Whisper implementation delivers:. 🏎️ Over 1000x real-time factor.✨ The lowest word
6
15
35
🔥 We have two huge announcements today! 🔥. We’re thrilled to announce early access to our new Baseten Hybrid offering and our launch on the @googlecloud Marketplace!. Links to the announcement blogs and waitlist for Hybrid in the comments below 👇. With Baseten Hybrid, you have
8
11
36
We're excited to introduce our new Engine Builder for TensorRT-LLM! 🎉. Same great @nvidia TensorRT-LLM performance—90% less effort. Check out our launch post to learn more: Or @philip_kiely's full video: . We often use
4
13
34
Thank you to the ML engineers, scientists, and founders who attended our NYC AI breakfast yesterday morning. New York's community of AI leaders is just getting started!

6
4
35


1
5
34
Congrats @zeddotdev on the new open-source model drop! It was a pleasure customizing Zeta's inference performance to hit your aggressive targets. Zeta is currently #3 on @newsycombinator 🔥

0
2
34
🚨 OpenAI just dropped a new open-source model 🚨. Whisper V3 Turbo is a new Whisper model with:. - 8x faster relative speed vs Whisper Large.- 4x faster than Medium.- 2x faster than Small.- 809M parameters.- Full multilingual support.- Minimal degradation in accuracy

2
3
32
40% lower latency and 70% higher throughput for Stable Diffusion XL? . Using NVIDIA TensorRT to optimize each component of the SDXL image generation pipeline, we achieved these performance gains on an H100 GPU. Full results: .
2
12
29
Today @usebland launched on @ProductHunt, and we’re psyched to support them with state-of-the-art AI infrastructure. With Baseten, @usebland reduced latency from 3 seconds to under 400 milliseconds, and gained seamless autoscaling with 100% uptime to date.

2
5
31
Last week, @varunshenoy_ felt the need … the need for speed. He went deep on optimizing SDXL inference to squeeze every last drop of performance out of our GPUs. Here’s what he did to get down to 1.92 seconds for SDXL and 0.43 seconds for Stable Diffusion 1.5 on an A100:

3
6
31
fast!.

Baseten launches Mistral 7B API with leading performance 🚀. @basetenco has entered the arena with their first serverless LLM offering of Mistral 7B Instruct. Artificial Analysis are measuring 170 tokens per second, the fastest of any provider, and 0.1s latency (TTFT) in-line
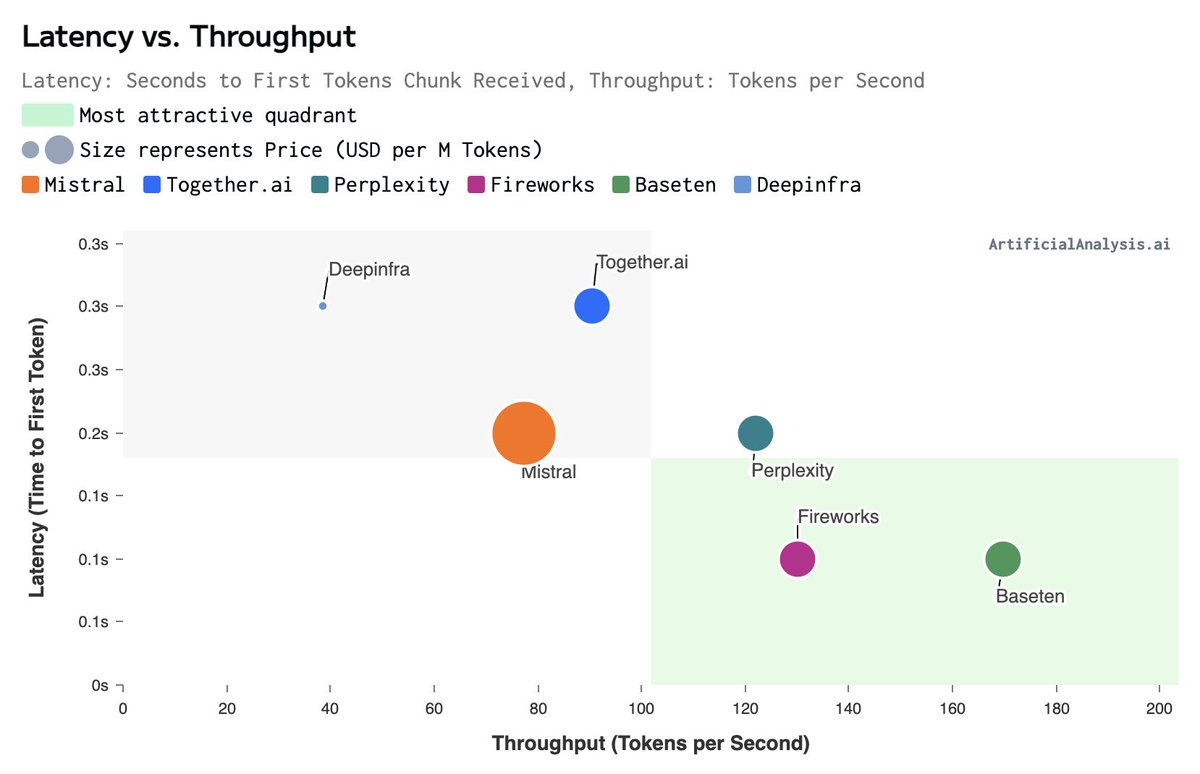
2
1
28
Happy Turkey Day! . Try out the brand-new Stable Diffusion v2 released last night here:

1
6
27
Here’s something fun to do with your family this week: Restore your low-quality family photos with this photo restoration app, built with BaseTen and powered by the GFP-GAN model 🖼.
0
5
28
The open-source community is still reeling from @deepseek_ai's new R1 drop, the new best-in-class reasoning model on par with o1. We're thrilled to have a close relationship with the DeepSeek team, hosting DeepSeek-R1 (and V3) from day one (running on H200s). 🚀. Learn more
2
2
27
Deploy Mixtral 8x22B in one click!. Mixtral fast facts:. - #1 pretrained model on the Open LLM leaderboard.- Mixture of Experts architecture.- Apache 2.0 license.- Uses 4 A100s in fp16, optimized implementations coming soon!.
2
7
28

Llama 4 is here! 🦙🚀. Scout | 109B Parameters | 10M Context.Maverick | 400B Parameters | 1M Context. Llama 4 models are natively multimodal, use a MoE architecture, and set a new frontier for performance/cost. We're excited to offer dedicated deployments of Llama 4!

6
9
27
See how quickly you can deploy a machine learning model with BaseTen in this tutorial on deploying fastai models 💨
0
10
25
We're excited to announce our partnership with @nvidia to provide inference for NVIDIA NIM models on dedicated endpoints, including the new Llama 3.3 Nemotron Super 49B!. You can get a scalable, dedicated endpoint for NIM models like Llama 3.3 Nemotron now in a few clicks.

📰 #GTC25 News: NVIDIA Llama Nemotron reasoning family of models ➡️ Designed to provide a business-ready foundation for creating advanced #AIagents to solve complex tasks requiring reasoning, instruction following, chat and function calling.

4
9
27
We recently sat down to chat with @dpatil, the very first (!!!) Chief Data Scientist of the United States 🇺🇸. Stay tuned next week for the full talk!
0
5
26
LangChain + Baseten = ♥️. Build with LLMs like Falcon, WizardLM, and Alpaca in just a few lines of code using LangChain's Baseten integration.


⭐️LangChain Integrations⭐️. In this fast moving LLM landscape, we want to give everyone the power and flexibility of as many options as possible. But we also want to make it simple and easy to navigate. That's why we're launching an integrations hub.
1
5
23
We’re thrilled to partner with Canopy Labs to offer production-grade real-time inference for Orpheus TTS!.

People told us they want Orpheus TTS in production. So we partnered with @basetenco as our preferred inference provider!. Baseten runs Orpheus with:. • Low latency (<200 ms TTFB).• High throughput (up to 48 real-time streams per H100).• Secure, worldwide infra

2
3
25
🎉 We’re excited to announce Baseten Self-hosted for unparalleled control over AI model deployments!. 👉🏻 Check out our announcement blog to learn more: Our Self-hosted offering is specifically designed for companies and enterprises that need enhanced
1
7
23
"Model serving isn’t just a hard problem, it’s a hard problem that constantly demands new solutions.". Read about Truss in @TDataScience.
0
6
23
Come build with us! 🛠 🧠. We just opened two roles for:. 🚀 Field & Event Marketing Leaders 🚀 Sales Development Representatives 👀 Check out the full list: Apply directly 👆 or reach out with questions!

1
1
23
Another first 🎉. Unlock the power of @nvidia's Multi-Instance GPU (MIG) virtualization technology with H100mig GPUs on Baseten:
3
7
21
🚀 We’re excited to introduce our Speculative Decoding integration for our TensorRT-LLM Engine Builder! . Our new integration allows engineers to:. • Leverage SpecDec as part of our Engine Builder flow.• Hit the ground running with pre-optimized configs.• Lift the hood and
0
7
21
🚀 We’re thrilled to introduce Baseten Embeddings Inference (BEI), the most performant embeddings solution available! 🚀. BEI is optimized specifically for embeddings workloads, which often receive high numbers of requests and require low latency for individual queries. Across
3
8
22
"In this market, your No. 1 differentiation is how fast you can move. That is the core benefit for our customers. You can go to production without worrying about reliability, security and performance." - @tuhinone . Thanks @jordannovet and @CNBC for talking with us about what it

1
4
22
If you read the Technology section of the @nytimes this morning, you might have noticed some familiar names. Thanks @CadeMetz and @megatobin1, we're thrilled to be working so closely with @deepseek_ai! Shout out to @zhyncs42 for his incredible work in this area.

2
3
22
Deploy Falcon-7B in a couple clicks from our model library, or deploy Falcon-40B using Truss, our open source model packaging framework. @sidpshanker shows you how in his latest blog post:
0
7
18
🎶 MusicGen Large is now in the Baseten Model Library! Deploy in just a few clicks and get started using this music generation model from Facebook:.
1
4
16
Using Medusa, we achieved a 94% to 122% increase in tokens per second for Llama 3! 🤯. Medusa is a method for generating multiple tokens per forward pass during LLM inference. After trying more fundamental optimizations (like quantization, using H100 GPUs, or TensorRT-LLM), more

1
3
17
Jeremy Fisher built automated D&D referee—running on Baseten—that lets anyone play and never generates the same text twice. “You can play it forever.” We will. Soon to be released on

1
1
17
@usebland It's been awesome to be on the journey with you. Can't wait to see how what you all do next!.
1
0
19
Here’s another sneak peek at our Blueprint progress 👀. Meet our Web IDE. Think of it as the single place for building, testing, and deploying API endpoints with generative AI models—in your browser.
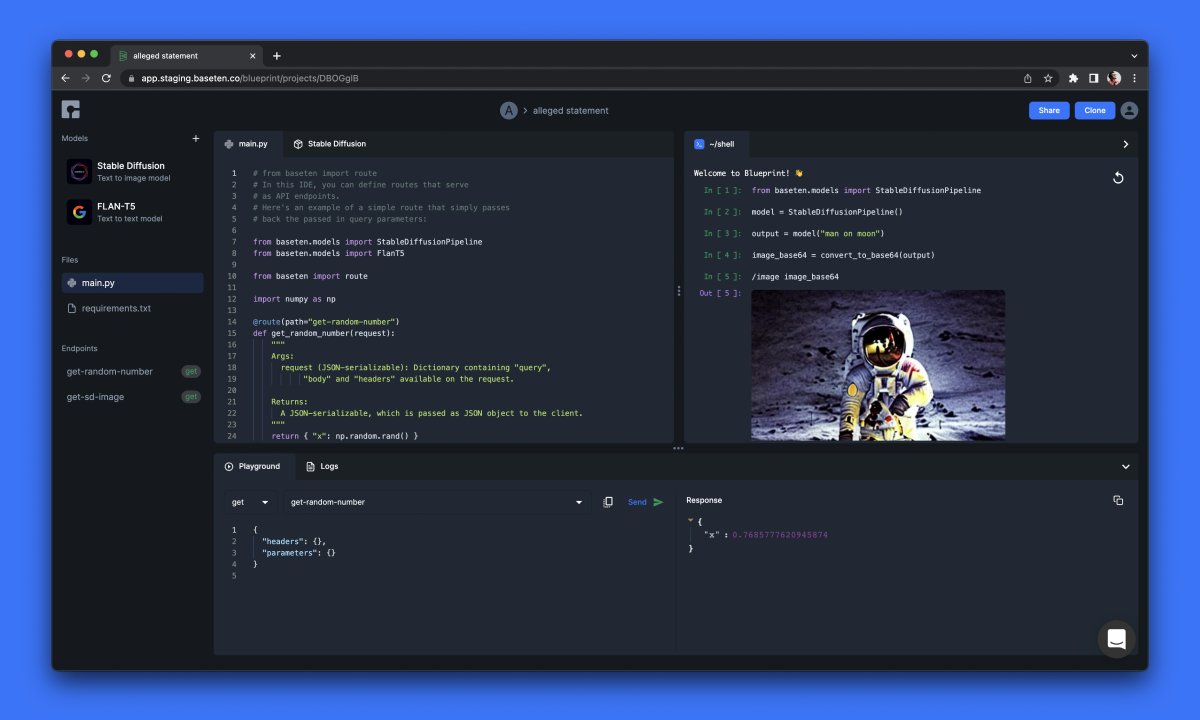
3
6
18
We're thrilled to be included in the #ForbesAI50! 🎉. Congratulations to everyone who made it, it's great to see so many of our customers and partners here too!.

3
6
19
Stable Diffusion 3 is now available in our model library! 🚀. Deploy it on an A100 optimized for production and generate highly detailed, high-resolution images in seconds.
2
4
19


We had a hard time finding a reliable source for r1-zero testing - hanging/dropped requests, latency issues. But then @basetenco (@tuhinone) and @hyperbolic_labs ( came in the clutch. If you need to do your own testing on r1-zero, start there.
2
0
18
Congrats to our friends at @rimelabs on the new text-to-speech model drop!. It’s very realistic, capturing nuances of human speech, accents, and emotion. 100% running on Baseten. Try it out!.

Introducing Arcana: AI Voices with Vibes 🔮. We just launched the most realistic spoken language (TTS) model like ever!. At Rime, we're dedicated to capturing the authentic nuances of real human speech, accents, laughter, sighs, and everything in between. Arcana also lets
1
8
18
The new DeepSeek-R1 drop by @deepseek_ai isn’t just an open-source model that rivals o1. It’s a massive upgrade to every generalist LLM ever made. This release includes multiple smaller, high-performing model distillations, showcasing the ability to use R1 for custom fine-tuning
1
3
18
🚀 You can now use NVIDIA B200s on Baseten and get higher throughput, lower latency, and better cost per token! 🚀. From benchmarks on models like DeepSeek R1, Llama 4, and Qwen, we’re already seeing:. • 5x higher throughput.• Over 2x better cost per token.• 38% lower latency

10
6
16
The hackathon is packed! Haven’t seen this much creative energy in one place since @Lin_Manuel met up with @sama.

0
2
17
Co-founders @wivincent and @lucaswcampa were a week away from launching @trytobyAI on @producthunt, but their AI infra wasn’t ready for the launch-day traffic spike. With Baseten, they hit #3 on Product Hunt with zero minutes of downtime. Read their story:

4
5
18
Congratulations to @lilyjclifford and the team at @rimelabs for their launch of Mist, the first TTS model to reproduce the genre-specific characteristics of voice.

Thrilled to introduce Mist, Rime's family of next-gen TTS models. Trained on a massive dataset of conversational speech, Mist is a powerful building block for real-time voice applications.

0
4
18
After witnessing so many AI builders encounter the limitations of real-time inference, we’re excited to announce async inference on Baseten! 🔄 🎉. Check out our blog to learn more: And don't miss our live webinar on August 15th!

1
6
18
We’ve got drinks, dinner, demos, and discussion - all we need is you!. Join builders and founders at our next AI meetup this Thursday, August 10th, in San Francisco.

1
4
16
How can you run DeepSeek-R1 on H100s when it doesn’t fit on a single node?. With multi-node inference you can split DeepSeek across two H100 nodes – 16 GPUs working together to run the world’s most powerful open-source LLM. Learn how in @saltyph and @philip_kiely's new blog 🧵

1
7
17

With Blueprint, you can fine-tune open source models, deploy fine-tuned models on serverless GPUs, and build endpoints to interact with your fine-tuned model. Get the inside scoop from our CEO in this 🔥Twitter thread:.

👋 Meet Blueprint: An easy way for developers to fine-tune and serve open source foundation models. Check it out here: 🧵 A thread on why we built Blueprint and what you can do with it:.
0
2
15
OpenAI’s #Whisper is the best audio transcription model ever. And today, you can deploy it for free in your Baseten account. Plus, for your own models, logs are now 10x shorter while surfacing new information like OOM errors. Full changelog:

0
4
16
Why should serializing, packaging, and serving a TensorFlow model require different steps and technologies than a PyTorch model?. It shouldn’t. That’s why Baseten built and open-sourced Truss, a seamless bridge from model development to model deployment.
0
4
15
🚀 We’re thrilled to announce that Baseten Chains is now GA for production compound AI! 🚀. In 5 years, every app will have multiple models embedded in it. What matters is a great app experience. To achieve the ultra-low latencies necessary for a competitive UX, AI builders
1
4
16
Ready to try open source LLMs?. Switch from GPT to Mistral 7B in the smallest refactor you'll ever ship: just 3 tiny code changes. If you're making the jump, DM us for $1,000 in free credits.
0
8
15
You can now deploy models with Baseten as part of @vercel's AI SDK! 🎉. Run OpenAI-compatible LLMs in your Vercel workflows with our best-in-class model performance. Plus: access all our LLM features (including streaming)—in any JS framework—with just a few lines of code. 💪

1
0
15
#SDXL Stable Diffusion XL 1.0 is here: the largest, most capable open-source image generation model of its kind. You can deploy it in 2 clicks from our model library: Note the accuracy and detail in the face and hands of this kind old wizard:

1
6
15
Today, @Get_Writer launched outstanding new industry-specific LLMs for medicine and finance. State-of-the-art models deserve state-of-the-art inference performance. With Baseten and TensorRT-LLM, Writer saw 60% higher TPS on their new custom models.
2
5
16
Want to use the brand-new Stable Diffusion model without writing a line of code?. Try our Stable Diffusion demo to generate an original image from a text prompt. Reply with your results!. Try it here 👉

2
4
14
Exciting to see all the hype around LLaMa over the last couple of weeks! Here's a quick demo of a ChatGPT-style chatbot using LLaMA deployed on Baseten.

1
2
15
It's finally #KubeCon! Come say hi to @alphatozeta8148, @philip_kiely, @drsarfati, @DelanieAI, @daniel_varney, @mj_bilodeau, and @Katz_ML at the booth!. 👉 Booth L12, Floor 1

0
3
16
@areibman @iporollo @gloriafelicia_ @amber_yanwang knocked it out of the park with Menu Bites, a generator for independent restaurants that creates studio-quality food photography out of customer pics. Sure to elevate your favorite local takeout spot!

1
2
15
Mixtral 8x7B beats Llama 2 70B on quality for many benchmarks, but it also wins on inference speed. Here’s why:. - Mixtral is only 46.7B parameters.- Only 12.9B are used during inference.- You can make it even faster with TensorRT-LLM and int8 quantization

1
5
15
🎊 We're excited to announce our new export metrics integration, allowing you to easily export model inference metrics to your favorite observability platforms like @grafana Cloud!. After working with our customers, including @DescriptApp, @rimelabs, and @Pixis_AI, we
3
3
15
AI is becoming increasingly multi-model. With Not Diamond, you're always leveraging the best LLM for your use case—at a lower cost, and lower latency. Congrats @tomas_hk on the release of Not Diamond! Can't wait to see this take off 💎.

Today we're releasing Not Diamond…. The world’s most powerful AI model router. Not Diamond maximizes LLM output quality by automatically recommending the best LLM on every request at lower cost and latency. And it takes <5m to set up. Watch this to see how to start using it:
0
3
15
We’re excited to launch canary deployments on Baseten! 🐦 🎉. Canary deployments let you gradually shift traffic to new model deployments, with seamless rollback if needed. Learn more in our launch blog 👇

2
1
14
How do you serve a fine-tuned Stable Diffusion model to over 2,000 users per minute?. Riffusion, a generative model for creating music, is a viral project by @sethforsgren and Hayk Martiros hosted on Baseten. The 3 biggest challenges of serving a generative model at scale:.
1
5
14
Gemma 3 just dropped from @GoogleAI. 🔥 If you want to try it out, you can deploy it in two clicks from our model library. Gemma 3 introduces:.• Multimodality (vision-language input).• Longer context windows (up to 128k tokens).• LMArena ELO comparable to 20x bigger models
2
4
15
💡 Read how we implemented the solution, and what we discovered in the process: . ⚙ Achieving performance increases like these with ease was one of the reasons we built our TensorRT-LLM Engine Builder. Check it out:
0
1
6
New bots for Llama 4 Scout and Maverick are now live on Poe! Get started with an 8M token context window for Scout (yes, you read that right) and 1M for Maverick. We're thrilled to power the fastest open-source models for Quora—more to come!
1
4
14
Who wants to take the 30b parameter Alpaca model for a ride? Announcement coming tomorrow.
2
0
13
Happy Monday!. We spent our weekend playing with the new Stable Diffusion XL ControlNet modules from @huggingface. Deploy it yourself today on Baseten 👇
1
2
14
Hmm 🧐. If you've ever wondered about open source models, we've got the checklist for you:

3
3
11
While exploring Mixtral performance, we had three goals: . 1️⃣ Get time to first token below 200 ms.2️⃣ Get above 50 perceived tokens per second.3️⃣ Save on cost by running the model on a single A100. Using TensorRT-LLM and quantizing the model to int8, we can achieved all three. 💪

1
2
12
Congrats to @waseem_s, @MatanPaul, @dorisjwo, and the whole team at @Get_Writer on the $200M Series C! . It’s been incredible getting a front-row seat to watching the team build such an incredible platform. 🚀.

🎉 We're excited to announce that we've raised $200M in Series C funding at a valuation of $1.9B to transform work with full-stack generative AI!. Today, hundreds of corporate powerhouses like Mars, @Qualcomm, @Prudential, and @Uber are using Writer’s full-stack platform to
1
1
12

Thank you to the ML creators who came out for @samshineeee’s talk on async inference, we had a blast!. #NYTechWeek isn’t over yet, don’t forget to RSVP for our party tonight for ML Engineers:


0
3
13
Developers need a way to call LLMs and get 100% guaranteed output structure without extra latency. Today, we’re launching two new features within our TensorRT-LLM engine builder to address this need: structured output and function calling! 🎉
1
6
12
1
0
12