

Greg Kamradt
@GregKamradt
Followers
42K
Following
14K
Media
962
Statuses
8K
President @arcprize, Founder https://t.co/clDqzdHe1A, builder/engineer
San Francisco, CA
Joined January 2011
Intelligence is interactive. Life does not happen in a single turn, but yet, frontier AI is measured with static benchmarks. Today we're previewing a preview of ARC-AGI-3 an Interactive Reasoning Benchmark. You can play (and build agents) on it today.
Today, we're announcing a preview of ARC-AGI-3, the Interactive Reasoning Benchmark with the widest gap between easy for humans and hard for AI. We’re releasing:.* 3 games (environments).* $10K agent contest.* AI agents API. Starting scores - Frontier AI: 0%, Humans: 100%

6
13
101

100% agree. We have a comparable w/ humans. H200 uses 36x the power of a human brain

intelligence per watt is the only important metric in the end.
5
0
16
7 day update w/ ARC-AGI-3 Preview. * As expected, humans have found the optimal run for each game. This helps us set the lower bound of # actions needed. Though, keep in mind this is after many iterations of playing, so it's useful only as a lower bound of actions (not learning)
4
1
16
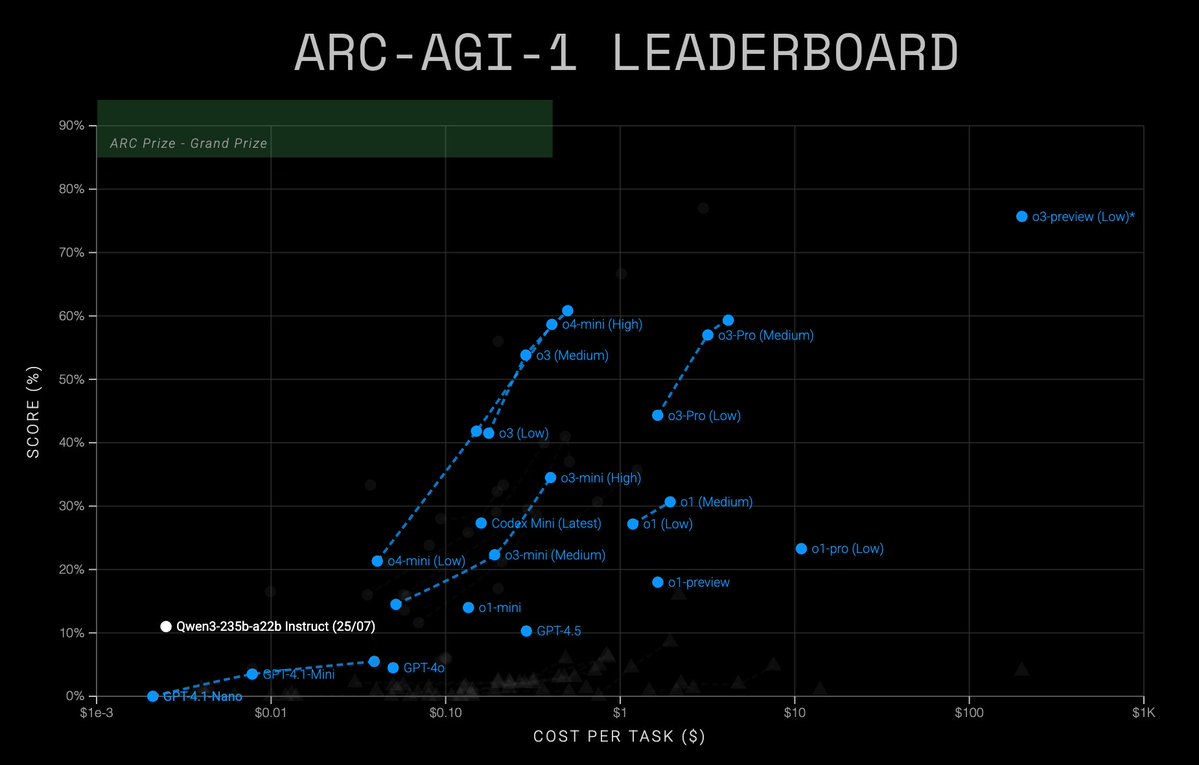
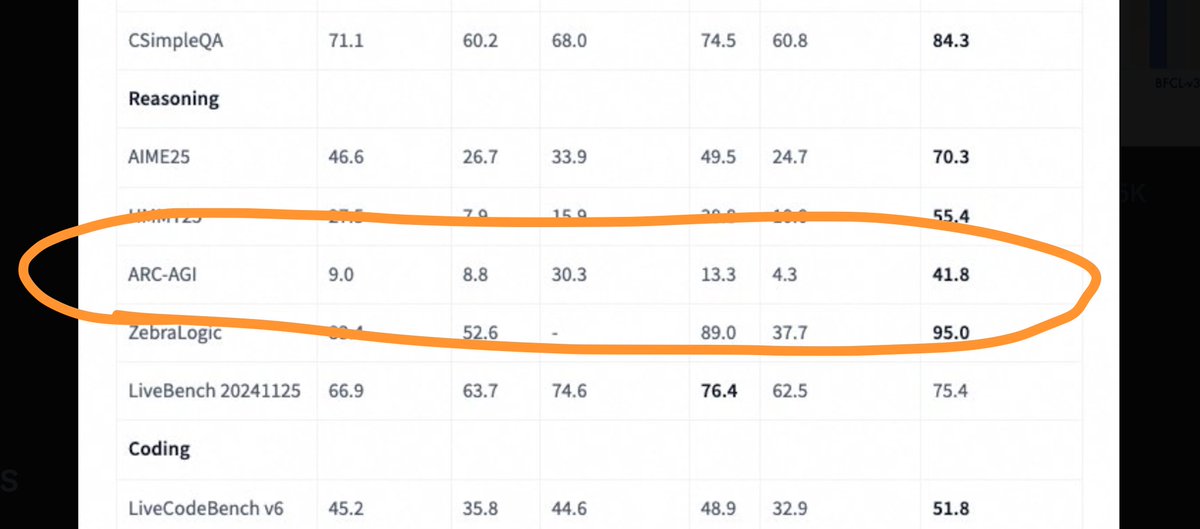
I was in contact with the Qwen team trying to reproduce their 41% results on ARC-AGI-1 but ultimately couldn't. They open sourced their method and code if anyone wants to check it out and confirm. We tested their model exactly the same as we test all other models (o3-high, grok.

Qwen3-235b-a22b Instruct-2507 ARC-AGI Semi Private Eval. * ARC-AGI-1: 11%, $0.003/task.* ARC-AGI-2: 1.3%, $0.004/task
15
34
410
I asked @yash_anysphere how many people were working on Cursor's "memory" feature. "just me". Cursor is a $10B company and Yash is the engineer that remembers your code base. He shared what worked (and what didn't) building memory for 1M daily-active-devs
11
8
179
This was one of those quotes that I felt a "before and after" moment. It changed how I thought about picking projects

remember: it’s rarely about the magnitude of your force vector, but the angle. most failures come from insufficient direction, not insufficient effort.
5
7
63
Happy to have @timshi_ai as a sponsor of ARC Prize. He's on the v3 learning path with us.

trying out ARC-AGI-3 (@arcprize) as a human baseline and some thoughts:. frontier models without hardcoding game knowledge into prompt get to close to 0. but humans seemly could drop into the environment and *learn on the fly* (using @fchollet 's words). initially i had no clue
0
1
3
RT @typewriters: Happy to see that the @WhiteHouse AI Action Plan includes many of our @arcprize recommendations and prioritizes the values….
0
8
0
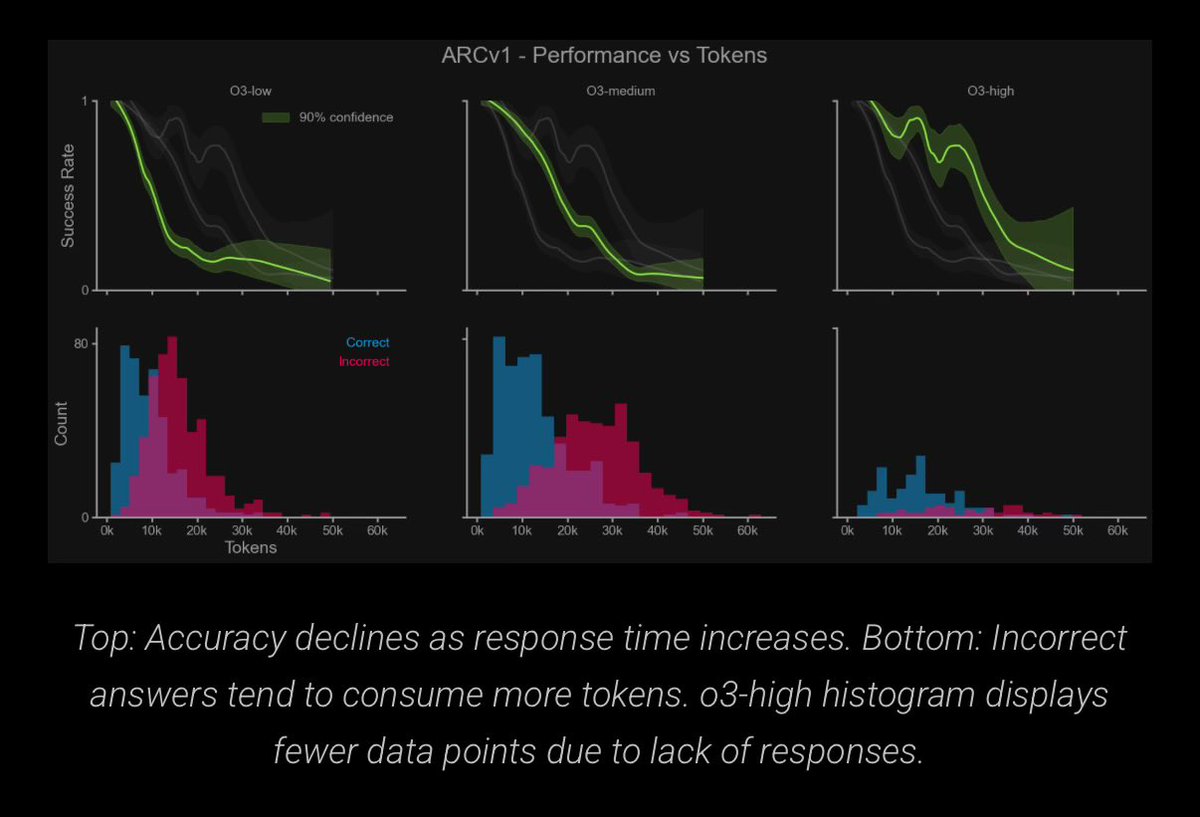

Anyone have a connection at @Alibaba_Qwen?. Trying to reproduce the results on @arcprize and getting different metrics. Want to get a hold of them and find out how they tested.
.@arcprize listed on the @Alibaba_Qwen model card. 2nd model card for us in 2 weeks. Excited for ARC-AGI to be seen as a supported way to measure model performance.
10
6
65

The world is moving towards agents. Static benchmarks don't measure what agents do best (multi-turn reasoning). Thus, interactive benchmarks:. * Terminal Bench (@alexgshaw, @Mike_A_Merrill).* Text Arena (@LeonGuertler).* BALROG (@PaglieriDavide, @_rockt).* ARC-AGI-3 (@arcprize).
14
29
220

> git clone https://github. com/arcprize/ARC-AGI-3-Agents.git && cd ARC-AGI-3-Agents && uv sync. > cp .env-example .env. > uv run main .py --agent=random --game=ls20. You just ran your first agent against ARC-AGI-3.
ARC-AGI-3 Agent Competition (27 days left). $10K prize pool in partnership with @huggingface. Your first submission is 3 lines of code away. Here are quick-start templates from @LangChainAI @AgentOpsAI and @AnthropicAI and lessons learned from devs who've tried ARC-AGI-3. 🧵

1
3
26