

ARC Prize
@arcprize
Followers
20K
Following
4K
Media
141
Statuses
436
A North Star for AGI. Co-founders: @fchollet @mikeknoop. President: @gregkamradt. Help support the mission - make a donation today.
Joined March 2024
Today we are announcing ARC-AGI-2, an unsaturated frontier AGI benchmark that challenges AI reasoning systems (same relative ease for humans). Grand Prize: 85%, ~$0.42/task efficiency. Current Performance:.* Base LLMs: 0%.* Reasoning Systems: <4%

66
344
2K

Clarifying o3’s ARC-AGI Performance. OpenAI has confirmed:. * The released o3 is a different model from what we tested in December 2024. * All released o3 compute tiers are smaller than the version we tested. * The released o3 was not trained on ARC-AGI data, not even the train.
37
83
1K
Verified DeepSeek performance on ARC-AGI's Public Eval (400 tasks) + Semi-Private (100 tasks). DeepSeek V3:.* Semi-Private: 7.3% ($.002).* Public Eval: 14% ($.002). DeepSeek Reasoner:.* Semi-Private: 15.8% ($.06).* Public Eval: 20.5% ($.05). (Avg $ per task).
19
107
1K
Introducing SnakeBench, an experimental benchmark side quest. We made 50 LLMs battle each other in head-to-head snake 🐍. 2.8K matches showed which models are the best at snake real-time strategy and spatial reasoning. Here’s the top match between o3-mini and DeepSeek-R1. 🧵


44
149
1K
Gemini-2.5-Pro Experimental Preview Results. ARC-AGI-1.* Public Eval: 24.3%.* Semi Private: 12.5%. ARC-AGI-2.* Public Eval: .8%.* Semi Private: 1.3%. These results are on par with Deepseek's R1.
27
73
1K
o3 and o4-mini on ARC-AGI's Semi Private Evaluation. * o3-medium scores 53% on ARC-AGI-1.* o4-mini shows state-of-the-art efficiency.* ARC-AGI-2 remains virtually unsolved (<3%). Through analysis we highlight differences from o3-preview and other model behavior

39
126
1K
We put OpenAI o1 to the test against ARC Prize. Results: both o1 models beat GPT-4o. And o1-preview is on par with Claude 3.5 Sonnet. Can chain-of-thought scale to AGI? What explains o1's modest scores on ARC-AGI?. Our notes:.

45
148
854
o3-mini performance matches o1 on ARC-AGI-1 Semi-Private Test Set. Scores by reasoning effort:.> Low: 11% ($0.009/task).> Med: 29% ($0.02/task).> High: 35% ($0.04/task)

24
104
810
GPT-4.5 Results on ARC-AGI. Semi Private Set (100 hold out tasks):.* Score: 10.33%.* Average Cost per Task: $0.29

43
69
829
Verified o1 performance on ARC-AGI's Semi-Private Eval (100 tasks). o1, Low: 25% ($1.5/task).o1, Medium: 31% ($2.5/task).o1, High: 32% ($3.8/task).
30
56
689
AGI is reached when the capability gap between humans and computers is zero. ARC Prize Foundation measures this to inspire progress. Today we preview the unbeaten ARC-AGI-2 + open public donations to fund ARC-AGI-3. TY Schmidt Sciences (@ericschmidt) for $50k to kick us off!

24
69
686
Llama 4 Maverick and Scout on ARC-AGI's Semi Private Evaluation. Maverick:.* ARC-AGI-1: 4.38% ($0.0078/task).* ARC-AGI-2: 0.00% ($0.0121/task). Scout:.* ARC-AGI-1: 0.50% ($0.0041/task).* ARC-AGI-2: 0.00% ($0.0062/task)

47
48
676
New ARC-AGI high score! 53% (Prize goal: 85%) Congratulations, MindsAI!

40
45
595
ARC Prize remains unbeaten. In 2024, SoTA moved from 33% to 55.5%. Announcing: ARC Prize 2024 Winners & Technical Report.

21
96
635
Claude Sonnet 3.7 + Thinking 1/8/16K results. - Base: 13.6%, $.05/task.- Thinking 1K: 11.6%, $.07/task.- Thinking 8K: 21.1%, $.21/task.- Thinking 16K: 28.6%, $.33/task. Performance is on par with o3-mini for slightly increased cost per task

28
58
640
This performance on ARC-AGI highlights a genuine breakthrough in novelty adaptation. This is not incremental progress. We're in new territory. Is it AGI? o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence. 2/4.
4
39
622
GPT-4.1 on ARC-AGI's Semi Private Evaluation. GPT-4.1:.* ARC-AGI-1: 5.5% ($0.039/tsk).* ARC-AGI-2: 0.0% ($0.069/tsk). GPT-4.1-Mini:.* ARC-AGI-1: 3.5% ($0.0078/tsk).* ARC-AGI-2: 0.0% ($0.0139/tsk). GPT-4.1-Nano:.* ARC-AGI-1: 0.0% ($0.0021/tsk).* ARC-AGI-2: 0.0% ($0.0036/tsk)

20
58
600
R1-Zero matches performance of R1 on ARC-AGI. We’ve verified that R1-Zero scored 14% on ARC-AGI-1 (vs 15% on R1). @mikeknoop explains why R1-Zero is more important than R1, why scaling inference isn’t going away, and what happens when “inference becomes training”. 1/4.
10
69
575
New ARC-AGI high score!.55.5% (Prize goal: 85%).Congratulations, MindsAI!

27
36
560
New ARC-AGI high score!.54.5% (Prize goal: 85%).Congratulations, MindsAI!

24
34
535
QwQ-32B on ARC-AGI. * Public Eval: 11.25%, $0.036 per task.* Semi Private: 7.5%, $0.039 per task

10
40
521
Today, alongside our analysis of o3's ARC-AGI-Pub performance, we're also releasing data (results, attempts, and prompt) from our high-compute testing. o3 was unable to solve ~9% set of Public Eval tasks that are straightforward for humans. Curious to see why?. We invite the.
20
55
476
New ARC-AGI high score! 48% (Prize goal: 85%).Congratulations, MindsAI!

26
33
433
Wow! One of our donors has anonymously decided to materially increase their support to $1M!. This fully funds our 2025 goal in just 1 day. With this support, we’ll launch v2, build v3, and continue driving progress in measuring AGI

We're not done - @bryanhelmig just pledged $15K to ARC Prize.
11
22
376
Announcing ARC Prize. A $1M+ competition to beat the ARC-AGI benchmark and open source the solution. Hosted by @mikeknoop & @fchollet.
24
110
374
Previously shared, ARC-AGI-2 (same format - verified easy for humans, harder for AI) will launch alongside ARC Prize 2025. We're committed to running the Grand Prize competition until a high-efficiency, open-source solution scoring 85% on the latest ARC-AGI is created. 3/4.
3
16
374
New ARC-AGI high score! 49% (Prize goal: 85%).Congratulations, MindsAI!

11
22
343
New ARC-AGI high score! 47% (Prize goal: 85%) Congratulations, MindsAI!

9
23
294
New ARC-AGI high score! 43% (Prize goal: 85%).Congratulations, MindsAI!

12
17
303


New ARC-AGI high score! 46% (Prize goal: 85%) Congratulations, MindsAI!

5
31
283
On Dec. 6. We'll announce the winners of ARC Prize 2024, including top score & paper award progress prizes. And we'll publish a paper documenting state-of-the-art approaches to ARC-AGI. We're now reviewing paper submissions and verifying the leaderboard. Stay tuned. .
10
18
269
The Next Chapter: ARC Prize Foundation. Beyond the benchmark - the North Star for AGI. We're excited to announce important updates to our leadership, entity structure, and initiatives for 2025. 1/5

7
22
263
[Paper] One approach to solve ARC-AGI is to learn a domain-specific language from the training set and add to the DSL on-the-fly when faced with novel tasks.
7
35
257
Novel test-time-training method to solve ARC-AGI without pretraining. "CompressARC achieves 34.75% on the training set and 20% on the evaluation set".

Introducing *ARC‑AGI Without Pretraining* – ❌ No pretraining. ❌ No datasets. Just pure inference-time gradient descent on the target ARC-AGI puzzle itself, solving 20% of the evaluation set. 🧵 1/4


4
22
253
[Paper] Dreamcoder's inductive program synthesis has inspired many ARC-AGI approaches. By combining neural networks + symbolic abstractions, it can tackle tasks from programming to physics.
7
34
247
ARC Prize 2025 Leaders. 2 weeks in, 7 months to go. The Grand Prize is still unclaimed

12
17
248
New ARC-AGI high score! 39% (Prize goal: 85%). Congratulations, MindsAI!

6
18
238
New ARC-AGI high score! 38% (Prize goal: 85%). Congratulations, MindsAI!

6
15
234
New ARC-AGI high score! 41% (Prize goal: 85%) Congratulations, MindsAI!

5
17
211
ARC Prize is now 3 months old - we're announcing:. 🏆 +$100K Grand Prize (now $600k).📜 +$25K Paper Awards (now $75k). And we're committing funds for a US university tour in October and the development of the next iteration of ARC-AGI.
6
30
205
Every ARC-AGI-2 task, however, is solved by at least two humans, quickly and easily. We know this because we tested 400 people live.

6
9
218
New ARC-AGI high score! 42% (Prize goal: 85%).Congratulations, MindsAI!

5
10
208
One goal for ARC Prize was to provide a public measure of progress towards AGI. Here's what we see now when new models like o1 come out.

4
20
213

6
15
220
Base LLMs (no reasoning) are currently scoring 0% on ARC-AGI-2. Specialized AI reasoning systems (like R1 and o3-mini) score <4%. Even AI systems with high adaptation like o1 pro and o3 low score single-digits (est.)

7
14
212
Our belief is that once we can no longer come up with quantifiable problems that are relatively easy for humans, yet hard for AI, we have reached AGI. ARC-AGI-2 proves that we do not have AGI. New ideas are still needed!.
3
9
206
ARC-AGI-1 was designed to challenge deep learning. ARC-AGI-2 challenges reasoning systems – while still maintaining a 100% human solve rate. Early results show frontier AI systems scoring 10-20% on ARC-AGI-2 and we're launching it March 2025. This gap demonstrates that we have

10
16
199
Deep learning is not enough to beat ARC Prize. We need something more. @mikeknoop & @fchollet share a path to defeat ARC-AGI via Program Synthesis.
6
33
192


DeepSeek performance is on par, albeit slightly lower, with o1-preview.
2
12
187
Not only can children solve ARC-AGI tasks, they can create them, too.

9
20
153
ARC-AGI-1 (2019) pinpointed the moment AI moved beyond pure memorization in late 2024 demonstrated by OpenAI's o3 system. Now, ARC-AGI-2 raises the bar significantly, challenging known test-time adaptation methods. @MLStreetTalk is helping us launch ARC-AGI-2 with an interview.
1
4
183

7
9
177
Inspired by @karpathy's recent tweet - games are a great test environment for AI. They require:.• Real-time decisions.• Multiple objectives.• Spatial reasoning.• Dynamic environments. So we built SnakeBench to explore how LLMs would do.

I quite like the idea using games to evaluate LLMs against each other, instead of fixed evals. Playing against another intelligent entity self-balances and adapts difficulty, so each eval (/environment) is leveraged a lot more. There's some early attempts around. Exciting area.
5
4
178
Symbolic interpretation. Frontier AI reasoning systems struggle with tasks requiring symbols to be interpreted as having meaning beyond their visual patterns. Systems attempted symmetry checking, mirroring, transformations, and even recognized connecting elements, but failed to

4
8
180

[Paper] Neural diffusion models that. Invert "noise" applied to syntax trees. Iteratively edit code while preserving syntactic validity, making it easy to combine the model w/search. Learn to convert images into programs that produce those images.

5
29
172
ARC Prize 2025 is Live. $1M competition to open source a solution to ARC-AGI. Your objective: Reach 85% on the private evaluation dataset. Progress needs new ideas, not just scale

7
34
166
Intelligence isn't just capability; it's efficiency. We can no longer report performance as a single metric. Going forward our leaderboard will track the *cost* of performance as a first class citizen. ARC-AGI-2 is showing material resistance over ARC-AGI-1 towards reasoning

3
9
164
o3-medium does great on ARC-AGI-1, scoring 41% (low) and 53% (medium). This is currently the top public model score we've verified. o4-mini shows SOTA levels of efficiency costing only $0.05/task for 21% accuracy. In contrast, o1-pro (low compute) requires ~$11/task for the

3
8
163
New baseline score on ARC-AGI-Pub. GPT-4o mini: 3.6%. This score is against the public evaluation set

20
12
156
ARC-AGI-2 isn't about superhuman skills; it's about exposing what's missing in current AI: efficient acquisition of new skills. It challenges capabilities like symbolic interpretation, compositional reasoning, and contextual rule application.
1
7
162
Leading AGI research lab DeepMind is implementing nearly identical techniques we're seeing at the top of ARC Prize leaderboards. 1. test time fine-tuning.2. blast inference + search. AlphaProof = closed source.ARC Prize winning solutions = open source (by end of 2024)

7
14
157
[Paper] "Automated Design of Agentic Systems" features a case study on ARC-AGI. This approach - Meta Agent Search - progressively discovers novel agents that outperform state-of-the-art, hand-designed agents.

2
25
154

DeepSeek's R1-Zero is significant because it achieves strong reasoning performance *without* human-labeled data (SFT). It only relies on Reinforcement Learning (RL). This overcomes the friction of human data bottlenecks. 2/4.
1
9
150
We're looking for a creative Unity game developer to help us create fun and challenging mini-games. This is a contract position for a remote game development role. Required Skills:.* Strong Unity Editor and C# programming.* 2 years of game development experience.* Strong

13
25
147
[Paper] Current high-scoring team member @bayesilicon shares an ARC-AGI training task generator. More examples ". should enable a wide range of experiments that may be important stepping stones towards making leaps on the benchmark .".

3
14
143
ARC-AGI-2 has been added to @huggingface's Lighteval. As you evaluate your models with Lighteval, ARC-AGI-2 will now be featured as an output.

🔥 Evaluating LLMs? You need Lighteval — the fastest, most flexible toolkit for benchmarking models, built by @huggingface. Now with:.✅ Plug & play custom model inference (evaluate any backend).📈 Tasks like AIME, GPQA:diamond, SimpleQA, and hundreds more. Details below 🧵👇.
8
18
141
ARC Prize 2024 is now closed for code submissions! 🏁. Thank you to everyone who participated. We made incredible progress on ARC-AGI. Next: paper deadline Tuesday + a review period where the Kaggle & ARC Prize teams will verify winning solutions. Winners announced Dec. 6.

3
12
135
Compositional Reasoning. AI reasoning systems struggle with tasks requiring simultaneous application of rules, or application of multiple rules that interact with each other. In contrast, if a task only has one, or very few, global rules, we found these systems can consistently

2
6
135
.@LiaoIsaac91893 has open sourced his "ARC-AGI Without Pretraining" notebook on Kaggle. You can use it today and enter ARC Prize 2025. It currently scores 4.17% on ARC-AGI-2 (5th place). Amazing mid-year sharing and contribution. Thank you Isaac.
Introducing *ARC‑AGI Without Pretraining* – ❌ No pretraining. ❌ No datasets. Just pure inference-time gradient descent on the target ARC-AGI puzzle itself, solving 20% of the evaluation set. 🧵 1/4
2
8
130
[Paper] ARC-AGI remains unsolved despite its seemingly simple content and evaluation methods. To overcome the limitations of result-oriented analyses, this study embraces the Language of Thought Hypothesis (LoTH).



3
17
113
"Spatially-aware tokenization scheme" is a concept @fchollet has been speaking about on our university tour. Transformers aren't just for sequences - they can be made to work with any kind of data structure, including grids.

We trained a Vision Transformer to solve ONE single task from @fchollet and @mikeknoop’s @arcprize. Unexpectedly, it failed to produce the test output, even when using 1 MILLION examples! Why is this the case? 🤔
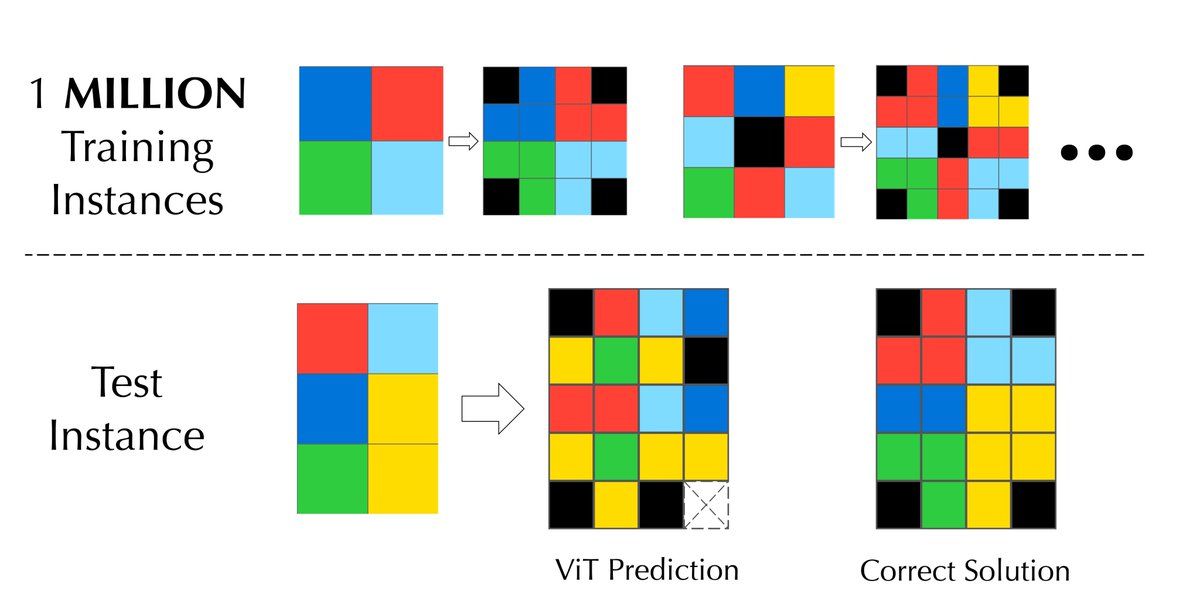
2
10
124
"Inference as Training.". Reasoning systems can generate high-quality data during inference, which can then be used to further train and improve the model. This creates a powerful feedback loop and a potential runaway effect for companies with large user bases. 3/4.
1
8
125
We've also begun early design work on ARC-AGI-3 to endure 3+ years, launching in 2026. We're exploring ARC-like games to formally codify efficiency, require new capabilities like goal orientation, massively raise the bar for on-the-fly skill acquisition, and resist large-scale
4
8
116

Key finding #1: Early responses showed higher accuracy. We noticed that tasks which the model returned sooner had higher accuracy. Those that took longer, either in duration or token usage, were more likely to fail. This signals that the model comes to conclusion or has higher

2
3
118
ARC Prize 2025 ($1M, open-source required) is designed to drive progress on this specific gap. Last year's competition had over 1.5K teams participate and 40 research papers published.
1
6
115
The Rise of Fluid Intelligence. "@fchollet is on a quest to make AI a bit more human". A thorough article by @matteo_wong explaining ARC-AGI and @arcprize
7
18
111
[Paper] This approach performs program synthesis using grid descriptions rather than transformation sequences. It scores decently well on the ARC-AGI public eval set without a handcrafted DSL.
4
14
103
After launching ARC-AGI-2, the community quickly pointed out some inaccuracies in our public eval sets. We're grateful for this helpful feedback, it makes our benchmark stronger and more reliable for everyone involved. In response, we performed a thorough internal and external.
0
4
107
Paper submissions (due today by 11:59pm UTC) are flowing in!. We're excited to share these intriguing approaches from top universities, AI labs, and Fortune 500 companies soon. Review paper + winners announcement coming Dec. 6.
7
9
103
[Paper] ARC-AGI is hard: a vast action space, hard-to-reach goals, a variety of tasks. ARCLE is an environment for reinforcement learning research on ARC that shows agents can learn via proximal policy optimization.

1
11
93

Thank you to @rishab_partha for helping with this analysis. The purpose of the 100 Semi-Private Tasks is to provide a secondary hold out test set score. The 400 Public Eval tasks were published in 2019. They have been widely studied and included in other model training data.
1
2
100
[Paper] Test-Time Training (TTT) layers show an ability to dynamically adapt & learn during test time, which is essential for the diverse & novel problems in ARC-AGI. This approach outperforms Transformers & RNNs in long-context tasks.

1
12
97
Contextual Rule Application. AI reasoning systems struggle with tasks where rules must be applied differently based on context. Systems tend to fixate on superficial patterns rather than understanding the underlying selection principles.

1
4
100
We’re working on more OpenAI model analysis that we’ll share soon. Stay tuned….
4
5
97
Key findings from SnakeBench:. 1. Reasoning models dominated - o3-mini and DeepSeek won 78% of their matches. 2. Context is crucial - Models still needed extensive board data and clear coordinate systems to play effectively

3
5
99
This year, we've over 2X’d compute, strengthened open-source requirements, and adjusted scoring to incentivize conceptual breakthroughs, not just leaderboard climbing. The prize categories are simple:.* Most Significant Conceptual Contribution ($75K).* Highest Score ($50K). The.
1
2
98
During testing, both o3 and o4-mini frequently failed to return outputs when run at “high” reasoning. The partial results we did receive are in the blog post. However, these reasoning efforts were excluded from the leaderboard due to insufficient coverage.
3
3
96
Key finding #2: Higher reasoning can be inefficient. When comparing o3-medium and o3-high on the same tasks, we found that o3-high consistently used more tokens to arrive at the same answers. While this isn’t surprising, it highlights a key tradeoff: o3-high can offer no accuracy

1
3
97