

Aston Zhang
@astonzhangAZ
Followers
9K
Following
418
Media
43
Statuses
205
Long context lead of Llama. Author of https://t.co/y8d6EugdO5.
Joined December 2018
Our Llama 3.1 405B is now openly available! After a year of dedicated effort, from project planning to launch reviews, we are thrilled to open-source the Llama 3 herd of models and share our findings through the paper:. 🔹Llama 3.1 405B, continuously trained with a 128K context

132
591
3K
Llama 3 has been my focus since joining the Llama team last summer. Together, we've been tackling challenges across pre-training and human data, pre-training scaling, long context, post-training, and evaluations. It's been a rigorous yet thrilling journey:. 🔹Our largest models


131
234
2K
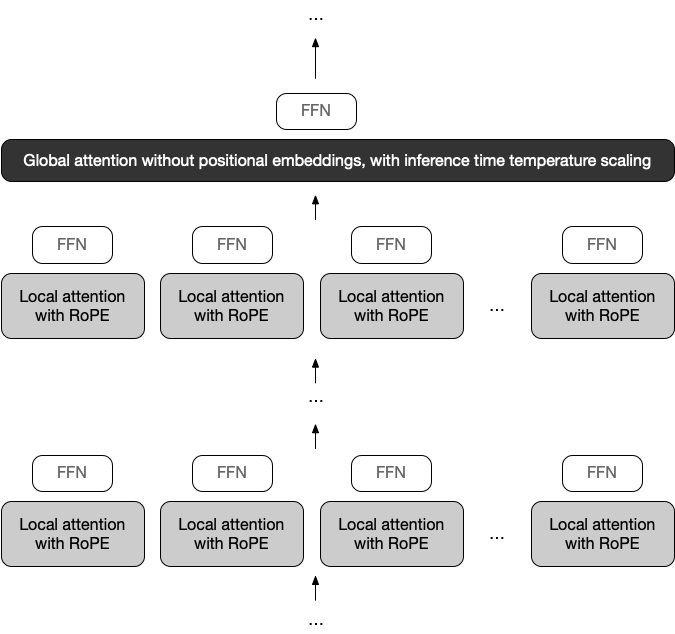
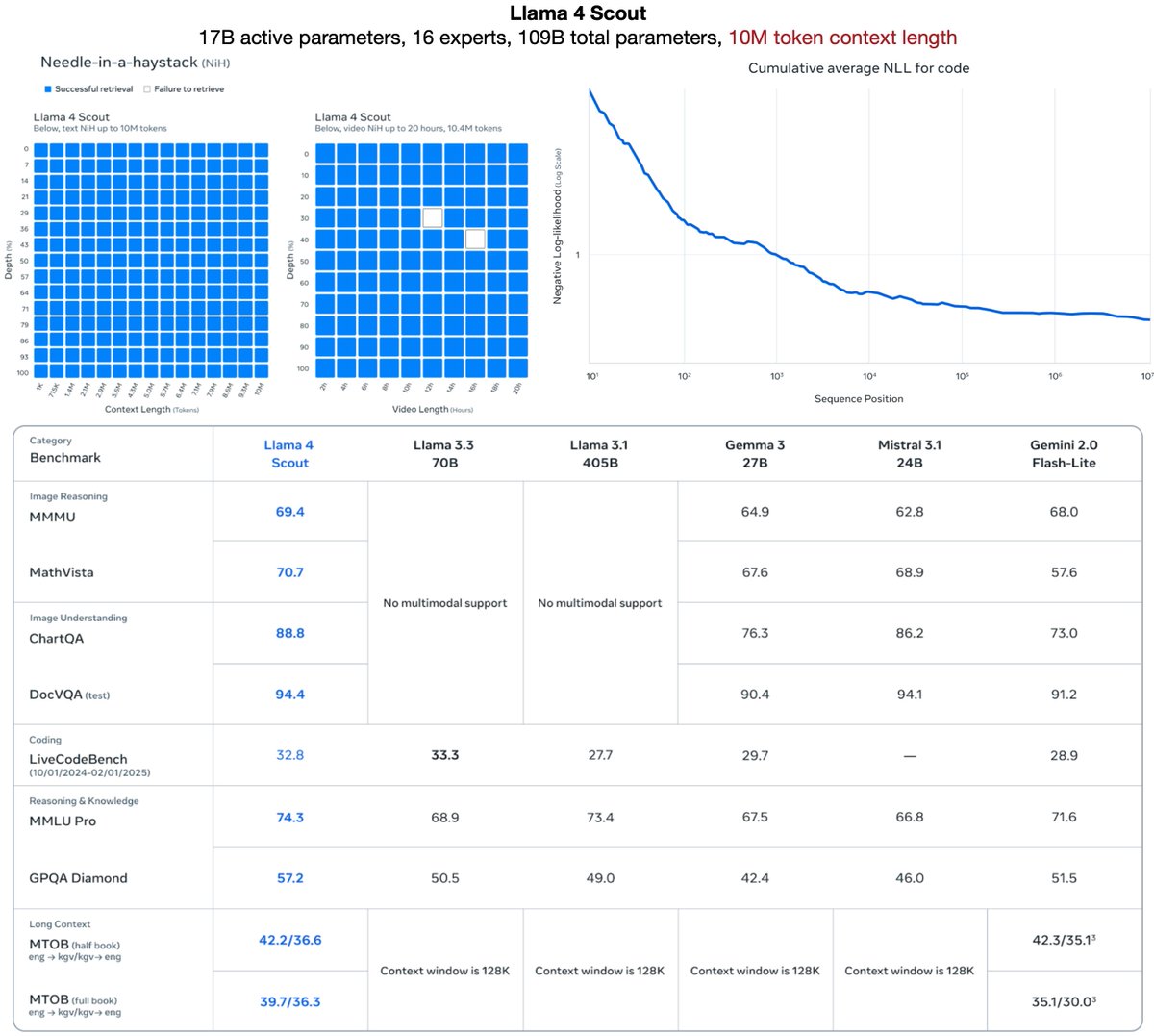
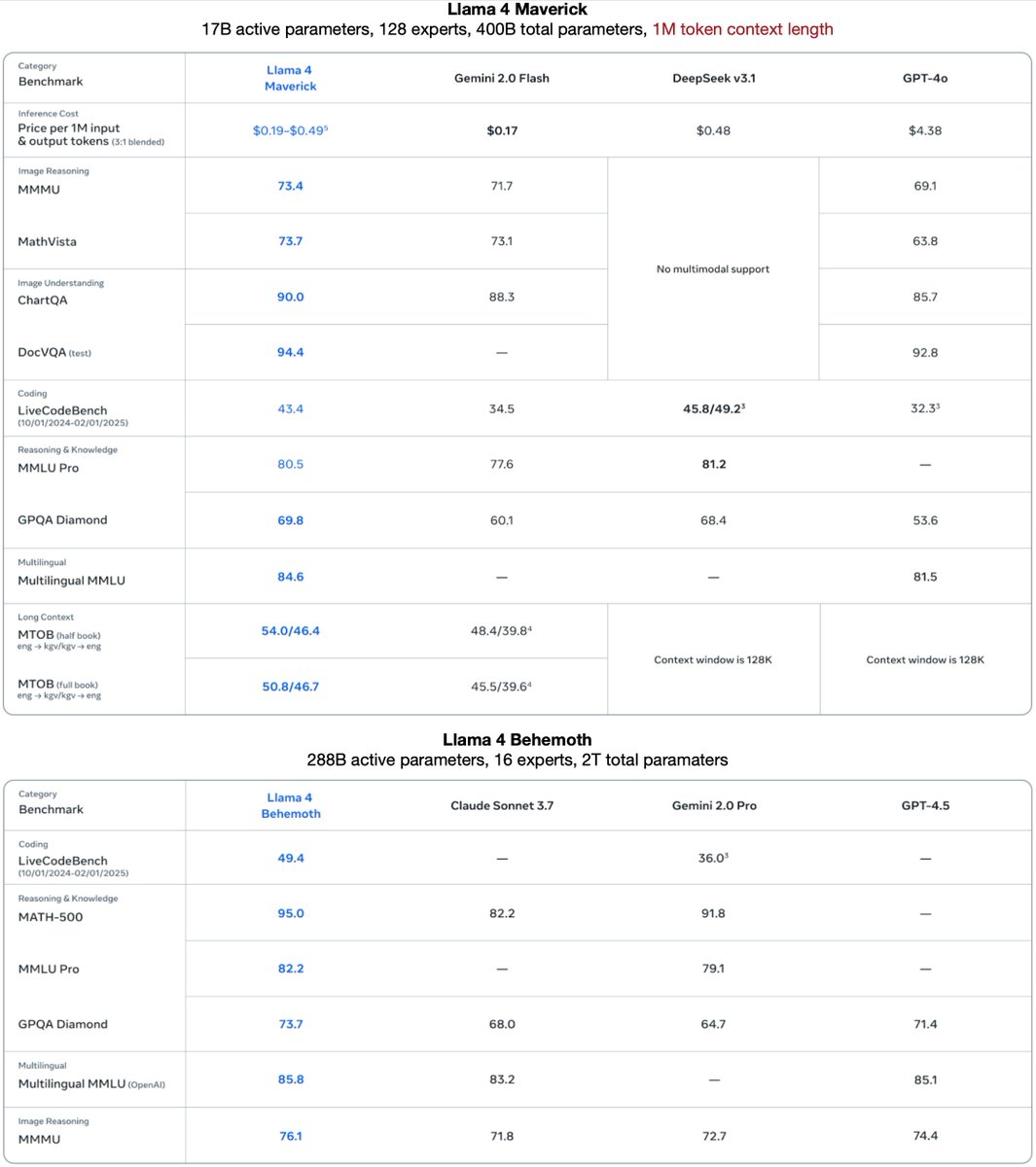
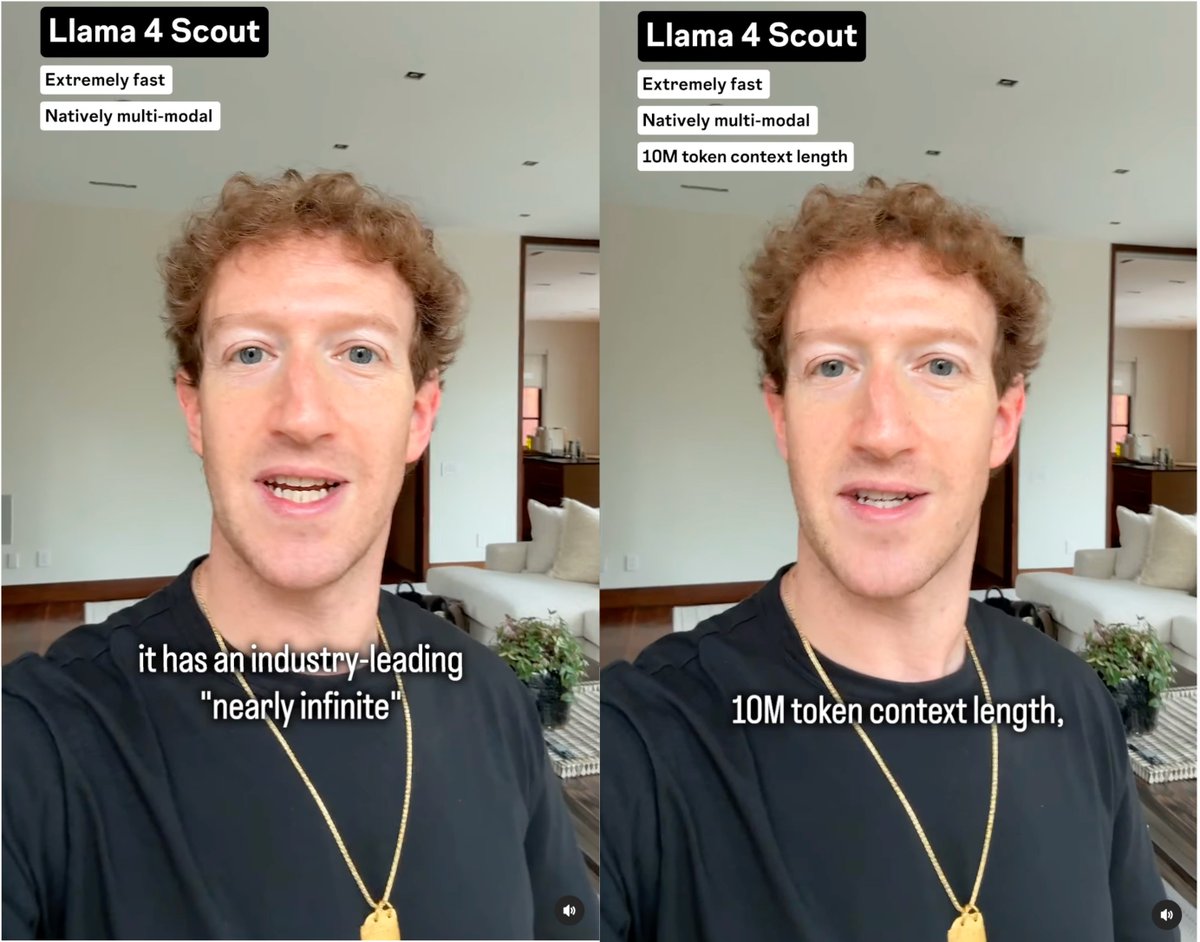
Our Llama 4’s industry leading 10M+ multimodal context length (20+ hours of video) has been a wild ride. The iRoPE architecture I’d been working on helped a bit with the long-term infinite context goal toward AGI. Huge thanks to my incredible teammates!. 🚀Llama 4 Scout.🔹17B
75
136
1K
Our deep learning book goes 1.0 beta🎉. 📕Forthcoming on Cambridge Univ Press (w @PyTorch).🆕JAX implementation.🆕Reinforcement Learning.🆕Gaussian Processes.🆕Hyperparameter Optimization. - Thank 500 contributors & 400 univs for choosing!.- Free at (1/5)


11
130
684
"Imagine learning a textbook with no figures.". Multimodal chain-of-thought (Multimodal-CoT) in Language Models. - Outperform GPT-3.5 by 16% (75%->91%) and surpass human performance on ScienceQA.- Less than 1B params (so you can train more easily).- Code & model released. [1/6]

10
113
520
Thrilled that our 'Dive into Deep Learning' book, now published by Cambridge University Press, is the Top New Release on Amazon!. To ensure accessibility and affordability, we, the authors, have waived our royalties. Plus, it's always available for free at

17
71
393
🚀 Exciting internship opportunity! . Join the Llama team @AIatMeta and help redefine what's possible with large language models—from pre-training to post-training. Be part of our 2025 research internship and help shape the future of LLMs. Feel free to email or DM me 📩. Learn.
6
21
223
Cheer AI up with "let's think step by step"? More plz. Let’s think not just step by step, but also one by one. We can use more cheers & diversity to SAVE huge manual efforts in chain of thought prompt design, matching or even exceeding performance of manual design on GPT-3 .[1/7]

1
24
210
🚀 New paper from our Llama team @AIatMeta! We discuss "cross capabilities" and "Law of the Weakest Link" of large language models (LLMs):. 🔹 Cross capabilities: the intersection of multiple distinct capabilities across different types of expertise necessary to address complex,

7
22
148
Don't assign the SAME parameter-efficient fine-tuning strategy to DIFFERENT layers. New tips:.- Group layers, SPINDLE pattern (e.g, 4-8-8-4 layers).- Allocate params to layers uniformly.- Tune all groups.- Adjust tuning strategies for diff groups. @AmazonScience @stanfordnlp[1/4]

1
11
105
#ICML Long Oral! @AmazonScience . Out-of-Distribution (OOD) Detection in Long-Tailed Recognition. 📉 Existing OOD detection fails when training data is long-tail distributed.📈 Ours: SOTA on long-tailed ImageNet. Paper: Code: 1/

4
11
85
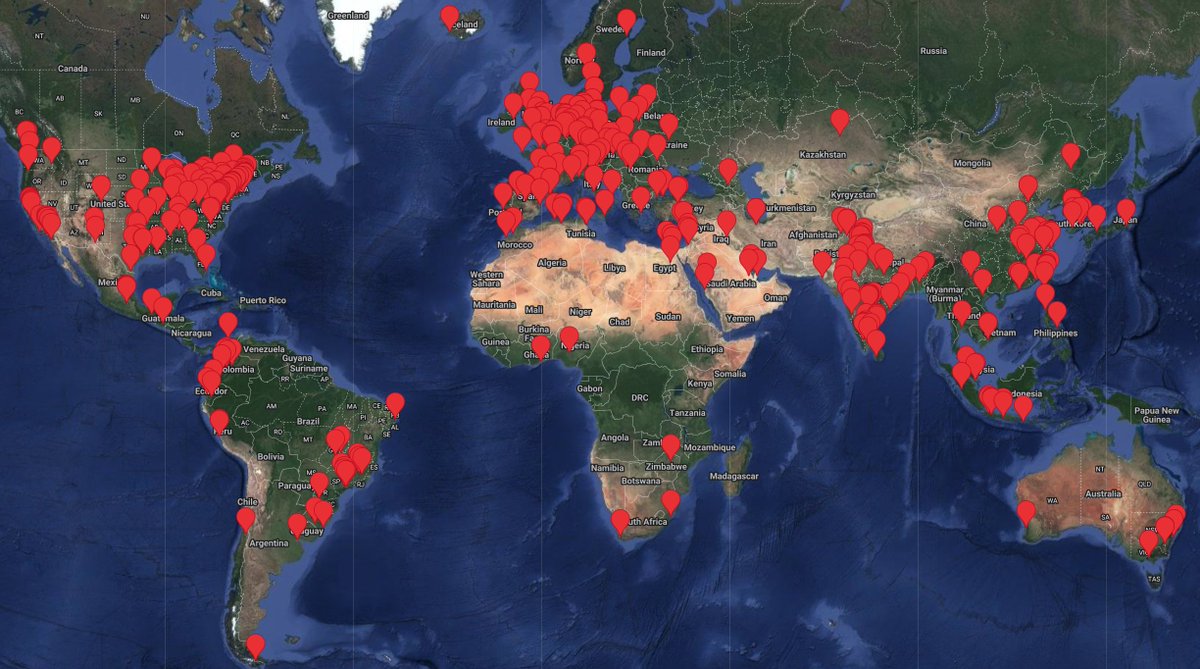
Although our book is free online, many readers have been requesting hard copies for tired eyes. So excited to announce:.✅ English publication agreement with @CambridgeUP was signed @AmazonScience .✅ Chinese 2nd edition was sent to print. Both in @PyTorch

5
11
75
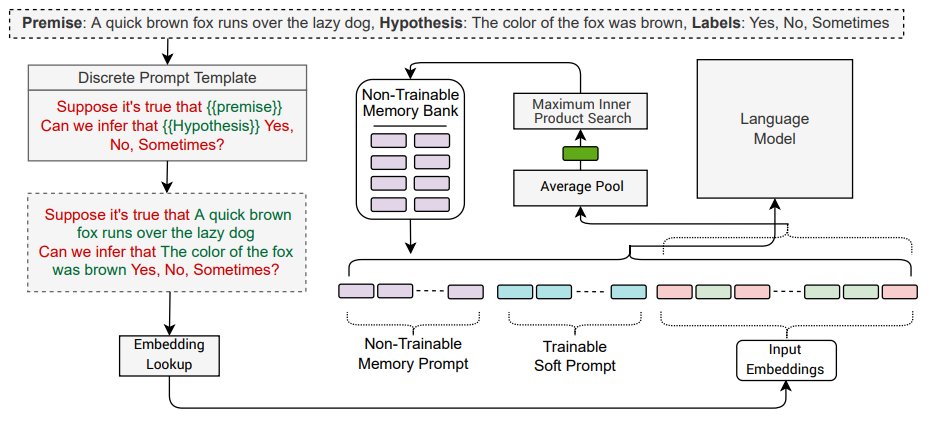
If your prompt tuning can't converge easily, make it semi-parametric. 🆕Memory prompt: input-adaptive but no need memory prompt tuning.✅Full fine-tuning on 31 tasks -> zero-shot generalization.✅Parameter-efficient fine-tuning on GLUE -> task transferability on SuperGLUE. [1/4]
1
18
61
Multimodal Chain-of-Thought Reasoning in Language Models. Code & model:. Thank @lupantech for providing model info on ScienceQA!.[6/6].
7
13
63
Thanks @AIatMeta for having me on the Llama for Developers podcast! Tokenizers play a crucial role in LLMs, impacting data handling, pre-training, post-training, and inference:. 🔹With a larger vocabulary, domain-specific words are more likely to be single tokens, preserving.

New video out today! Understanding the Meta Llama 3 Tokenizer with @astonzhangAZ from the Llama research team. This conversation dives into the change from SentencePiece to Tiktoken and what that enables for our latest models. Watch the full video ➡️
1
10
47
"Perform a task on smart phones? Train an agent using screenshots". You Only Look at Screens: Multimodal Chain-of-Action Agents. - New state of the art: 90% action type prediction accuracy and 74% overall action success rate on AITW.- No OCR or API calls.- Code released. [1/5]

3
5
39
Proud of what the team have been achieving together! Besides Llama 3, do check out our product launches

It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs. Key highlights. • 8B and 70B parameter openly available pre-trained and fine-tuned models. • Trained on more
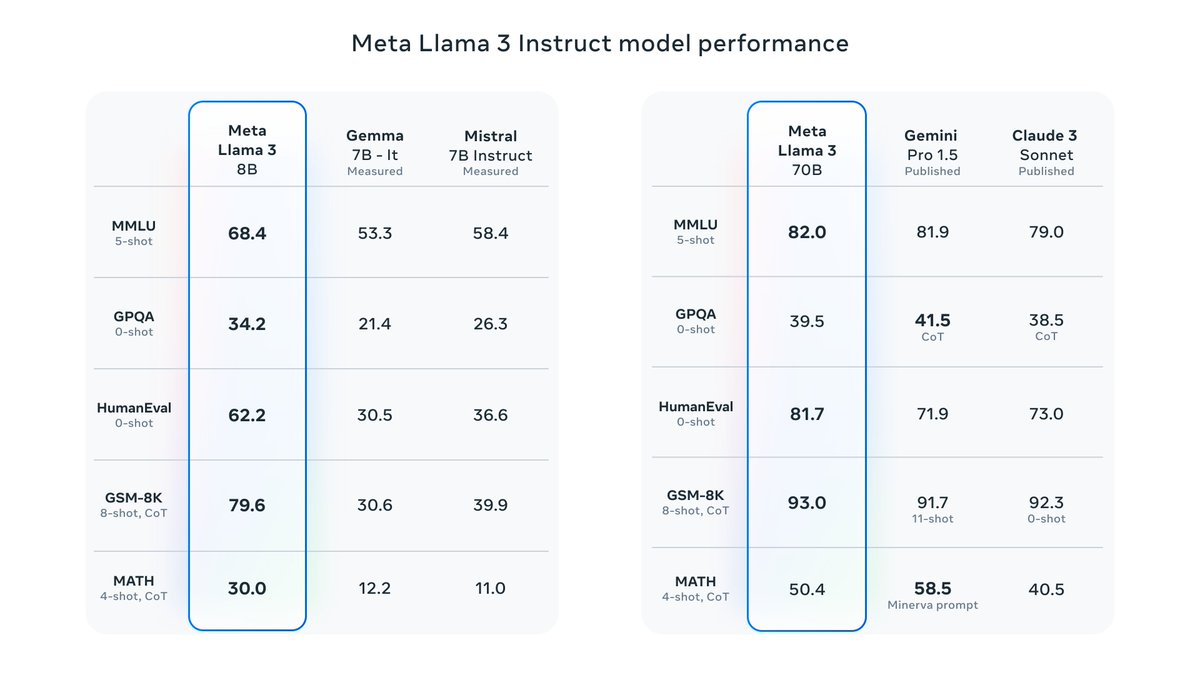
5
0
37
With growing discussions of Multimodal-CoT on Reddit, I just posted there explaining our thoughts behind this work (opinions are my own):.


"Imagine learning a textbook with no figures.". Multimodal chain-of-thought (Multimodal-CoT) in Language Models. - Outperform GPT-3.5 by 16% (75%->91%) and surpass human performance on ScienceQA.- Less than 1B params (so you can train more easily).- Code & model released. [1/6]
2
2
28
Thanks Lex! Llama is thrilled to support developers as an open-source model. With the exciting upgrades in this Llama 3 release, we're excited to see how video podcasts can empower developers to quickly build amazing things together.

@astonzhangAZ Congrats! Video podcasts is a great idea. Looking forward to learning more details.
0
0
27
Nice to hear that our "Beyond Fully-Connected Layers with Quaternions" paper received Outstanding Paper Award at this year's ICLR! Thanks teammates, reviewers, and committee members @iclr_conf.

We are thrilled to announce the #ICLR2021 Outstanding Paper Awards! Out of 860 excellent papers, the award committee identified 8 that are especially noteworthy: . Congratulations to the authors!!. @shakir_za @iatitov @aliceoh @NailaMurray @katjahofmann.
6
2
24
D2L is the first deep learning textbook that offers #JAX implementation + it's FREE (as far as we know). Get started with "import jax" at Thank @gollum_here from @AmazonScience!. (2/5)

1
0
24
Riveting read! High-stakes decision-making demands reliable evaluations. Understanding evaluation failure modes is crucial. Post-training evaluations, which are closer to human interactions, pose more challenges than pre-training ones.

New blog post where I discuss what makes an language model evaluation successful, and the "seven sins" that make hinder an eval from gaining traction in the community: Had fun presenting this at Stanford's NLP Seminar yesterday!

1
3
19
Our 25-page paper has much more info: Our code is available at: We'll release more code soon. This work was done with @zhangzhuosheng (my intern) @mli65 @smolix from @AmazonScience and @sjtu1896 .Happy to answer questions!.[7/7].
3
3
22
@adiletech Our new tokenizer will process more text with fewer tokens. Conservatively it will improve 15% token efficiency compared to the Llama 2 tokenizer. Grouped query attention counterbalances the slightly increased inference efficiency due to vocab increase.
3
1
20
@stochasticchasm At all local layers, tokens only attend to past within the same chunk. Global attention layers will aggregate local info.
1
0
20
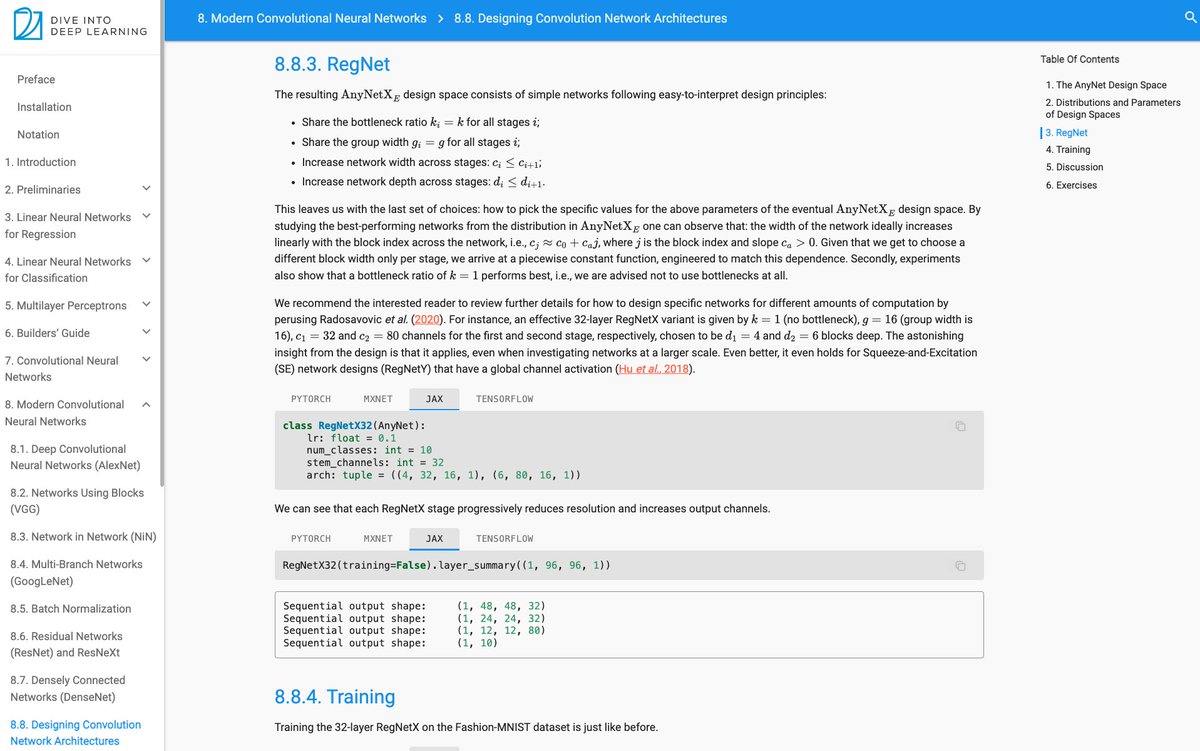
While ConvNeXt (2022) further sparks the debate between CNNs and transformers for vision, added a CNN design section covering ResNeXt-itication @sainingxie et al, RegNets Radosavovic et al, ConvNeXt @liuzhuang1234 et al. Preview at:

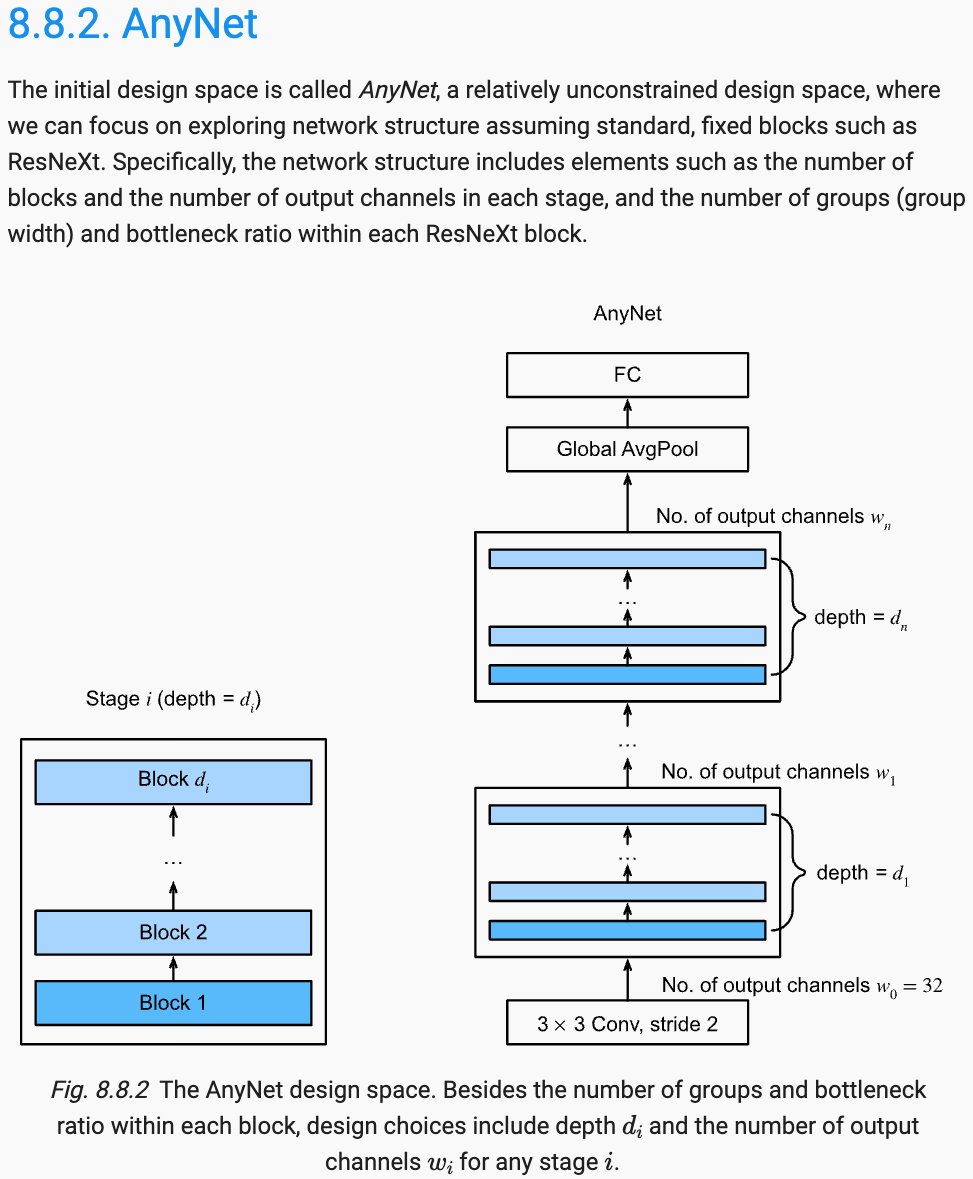
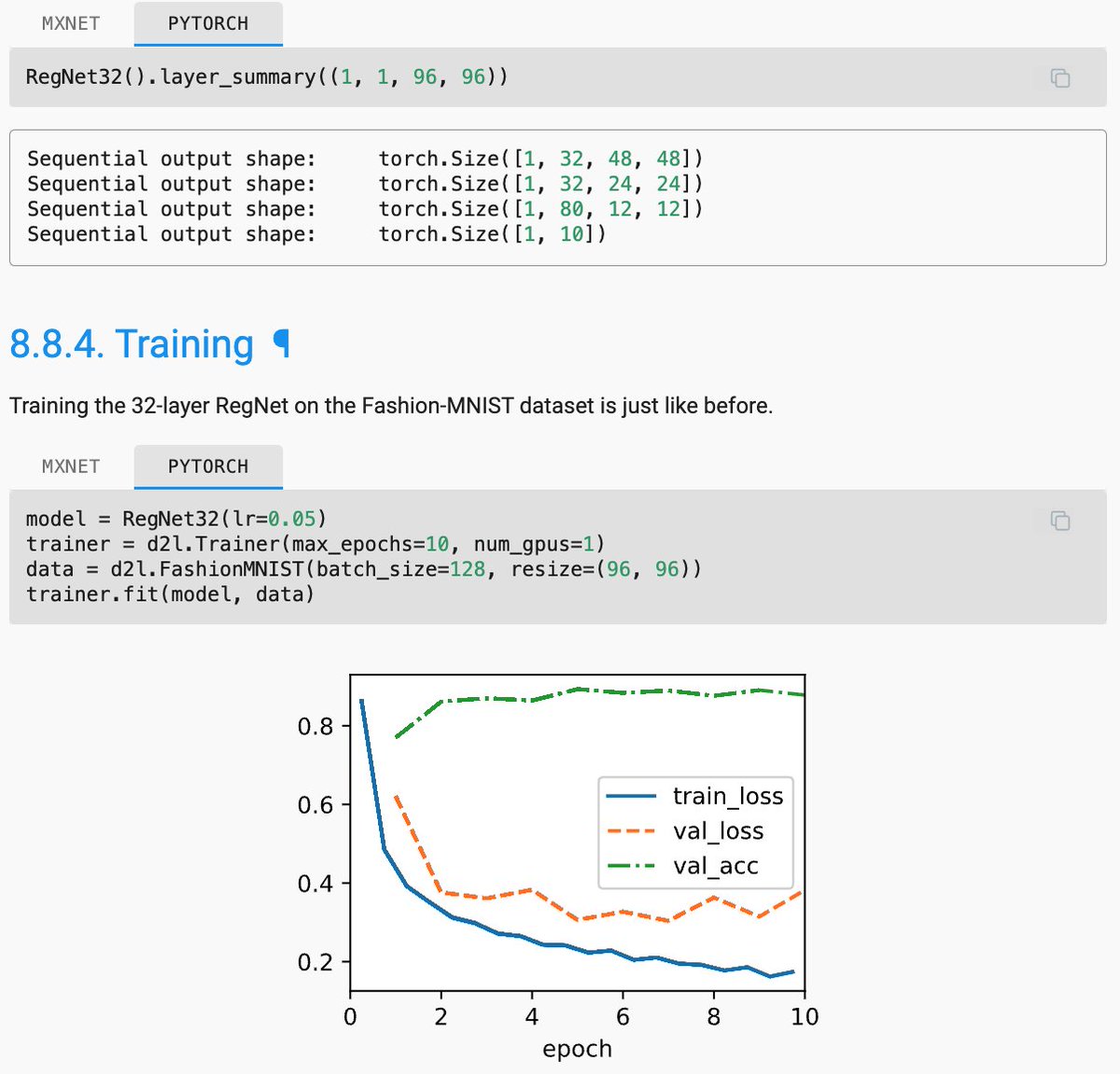

0
6
18
Multimodal-CoT *under 1 billion parameters* outperforms the previous state-of-the-art LLM (GPT-3.5) by 16% (75.17%→91.68%) and even surpasses human performance on the ScienceQA benchmark. [5/6]

3
1
18
A heartfelt thank you to my incredibly talented co-authors @zacharylipton, @mli65, @smolix from @AmazonScience, and the amazing 700+ open-source contributors. Your dedication and expertise have been instrumental in making our book a valuable resource for everyone!.
1
5
14
Existing studies related to CoT reasoning are largely isolated in the language modality. Given inputs in different modalities, Multimodal-CoT decomposes multi-step problems into intermediate reasoning steps (rationale) and then infers the answer. [2/6]

2
0
16
“Everything is a special case of a Gaussian process.” Gaussian processes and deep neural networks are highly complementary and can be combined to great effect:. Thank @andrewgwils from @nyuniversity!. (4/5)


1
0
15
Our biggest update so far. New discussions on ResNeXt, RegNet, ConvNeXt, Vision Transformer, Swin Transformer, T5, GPT-1/2/3, zero/one/few-shot, Gato, Imagen, Minerva, and Parti. Thanks our 265 contributors 🙏.

v1.0-alpha🎉. 📚New topics on transformers for vision and large-scale pretraining, CNN design, generalization, etc.⚡️New API inspired by @PyTorchLightnin to streamline the presentation.🦥"Lazy" layers to simplify @PyTorch code.🈶zh/pt/tr/vi/ko/ja ongoing.

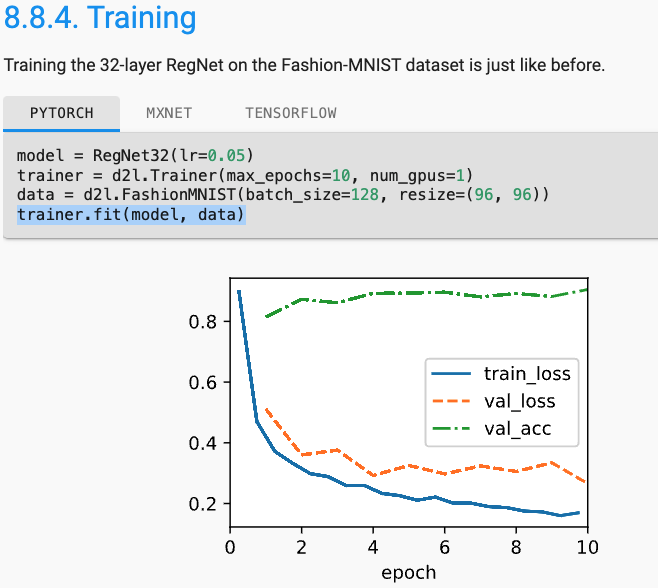

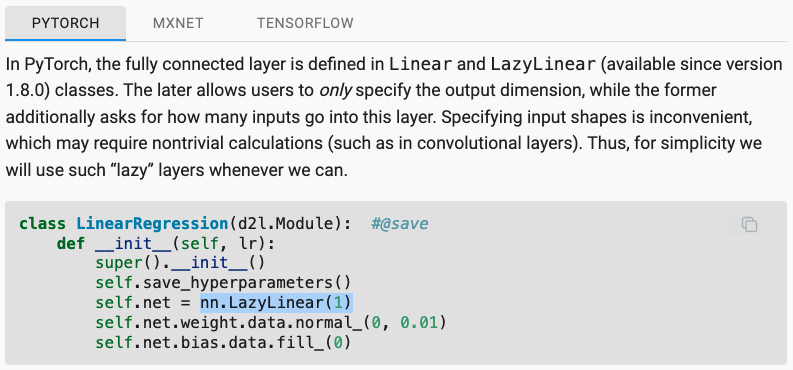
0
2
14
The superior perf of manual chain of thought (Manual-CoT) prompting to using a cheer (Zero-Shot-CoT) hinges on the hand-crafting of demos one by one. We can save such manual efforts with the “Let’s think step by step” prompt to generate reasoning chains for demos one by one.[2/7]

1
0
15
#ICML spotlight talk! @AmazonScience . Removing ✂️Batch Normalization (BN)✂️ Boosts📈 Adversarial Training (AT). 💪 AT makes models robust. 🤒 However, BN struggles to model different statistics of clean and AT samples. 💡 Just remove BN layers in AT!. 1/

2
3
14
Tired of setting hyperparameters in a trial-and-error manner? You may wish to check out the systematic hyperparameter optimization approach:. Thank @kleiaaro Matthias Seeger @cedapprox from @AmazonScience!. (5/5)


0
2
13
Just let us know if you are using D2L in your course and any feedback is welcome. We won't rest until D2L looks good. GitHub:
0
3
12
More to come!.
Dive into Deep Learning now supports @PyTorch. The first 8 chapters are ready with more on their way. Thanks to DSG IIT Roorkee @dsg_iitr, particularly @gollum_here who adapted the code into PyTorch. More at @mli65 @smolix @zacharylipton @astonzhangAZ

0
0
11
Try out our open sourced Llama 3 at .

Llama 3 has arrived! Taaa-daaam!
5
0
11
Our paper: .Parameter-Efficient Fine-Tuning Design Spaces Our code: .[4/4].
2
1
12
With the advent of #ChatGPT (sibling model to InstructGPT fine-tuned using reinforcement learning), you may get curious about how to enable ML to take decisions sequentially:. Thank @pratikac from @Penn, @rasoolfa @AsadiKavosh from @AmazonScience!. (3/5)


1
2
10
With GPT-3 on ten public tasks of arithmetic/commonsense/symbolic reasoning, Auto-CoT consistently matches or exceeds the performance of Manual-CoT that requires manual designs. This indicates that LLMs can perform CoT reasoning by automatically constructing demonstrations. [6/7]

1
0
11
However, simple solutions fail. E.g., given a test question of a dataset, retrieving similar questions and invoking Zero-Shot-CoT to generate reasoning chains will FAIL. Why? Large language models (LLMs) are not perfect: there can be mistakes in reasoning chains.[3/7] ⬇️

1
0
10
Diversity mitigates misleading by similarity. How Auto-CoT fixes it:.1. Partition questions of a given dataset into clusters.2. Select a representative question from each cluster and generate its reasoning chain using Zero-Shot-CoT with heuristics. No gradients, just cheers.[5/7]

1
0
9
@stochasticchasm Besides, this also forces long context modeling to 100% take place at global layers for better length extrapolation since local chunked attention can only model short context, e.g., <= 8k.
1
0
9
@waseem_s Wow that’s fast! One thing you can play with is different choices of temp scaling functions in iRoPE :).
1
0
9
Why Multimodal-CoT?. Vision input is a wealth of information that was not fully exploited for CoT reasoning in the past. See an example where the baseline (without using vision features) fails to predict the right answer due to the misleading by hallucinated rationales. [3/6]

1
0
8
I'd nominate Diffusion-LM by @XiangLisaLi2 et al.: non-autoregressive text generation with plug-and-play control based on 80M-param Transformers.
What directions do you think are out there that can be done without having to scale up the language model?.
1
1
8
How Multimodal-CoT works:. (i) Feed the model with language and vision inputs to generate rationales.(ii) Append the original language input with this generated rationale. Feed the updated language input with the original vision input to the model to infer the answer. [4/6]

1
0
7
@HoskinsAllen @AmazonScience @zhangzhuosheng @mli65 @karypis @smolix Because our goal is to enable CoT reasoning on multimodal benchmarks, rather than proposing yet another CoT for language only benchmarks. On the same multi-modal benchmark we compared with GPT-3.5 w/CoT (Lu et al. 2022a) in Table 4. Takeaway: vision input can't be ignored for CoT.
0
0
7
After similar questions to a test question are retrieved, wrong demos caused by Zero-Shot-CoT may mislead the same LLM to reason similarly with a wrong answer for the test question.---Misleading by Similarity. See how calculating "the rest" is mistaken as "the total" in fig.[4/7]

2
0
7
See more results & analysis (e.g., prompt distributions) in our paper: . SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning. w/ @sbmaruf (my awesome intern @AmazonScience), Shuai Zheng, Xingjian Shi, @yizhu59, @JotyShafiq, @mli65. [4/4]🔝.
1
2
7
@ThomasViehmann Nice explanation! Nonparametric methods tend to have a level of complexity that grows as data increases. @D2L_ai recently added a new section on Generalization in DL, which can be previewed at
0
0
5
Presenting our embarrassingly simple joint data augmentation for vision-language representation learning: MixGen. TL;DR: Just interpolate the two images and concatenate two text sequences to generate a new image-text pair.


2
2
6
Our focus is on how to apply (deep) representation learning of languages to addressing natural language processing problems.
We have re-organized Chapter: NLP pretraining ( and Chapter: NLP applications (, and added sections of BERT (model, data, pretraining, fine-tuning, application) and natural language inference (data, model).

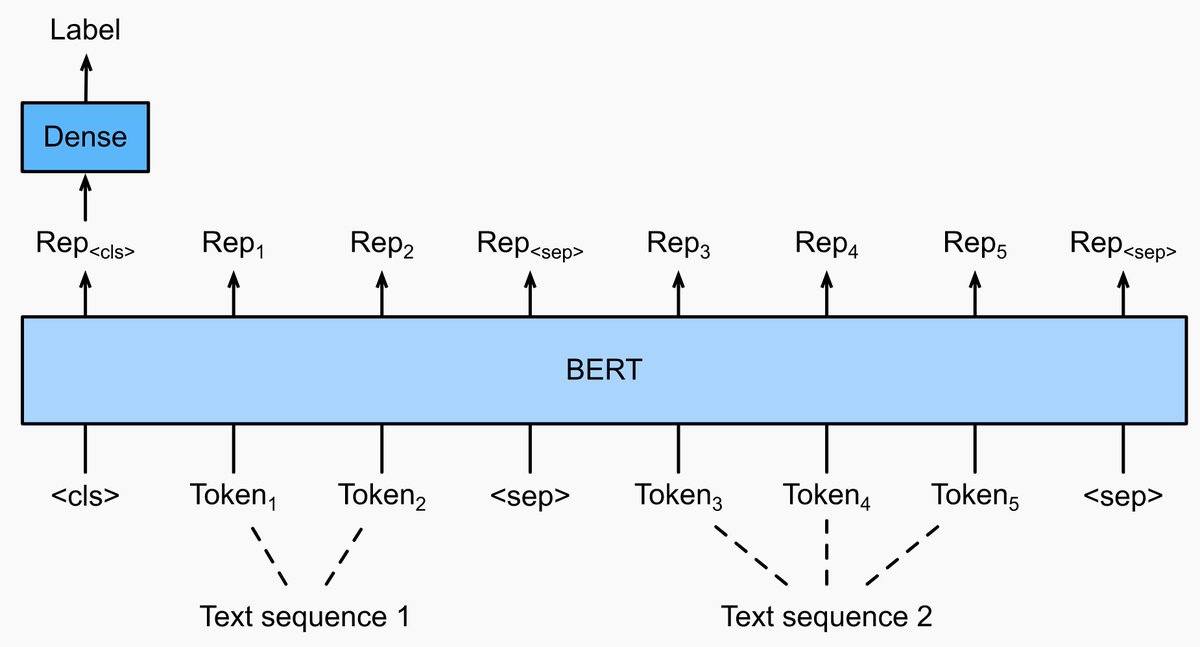
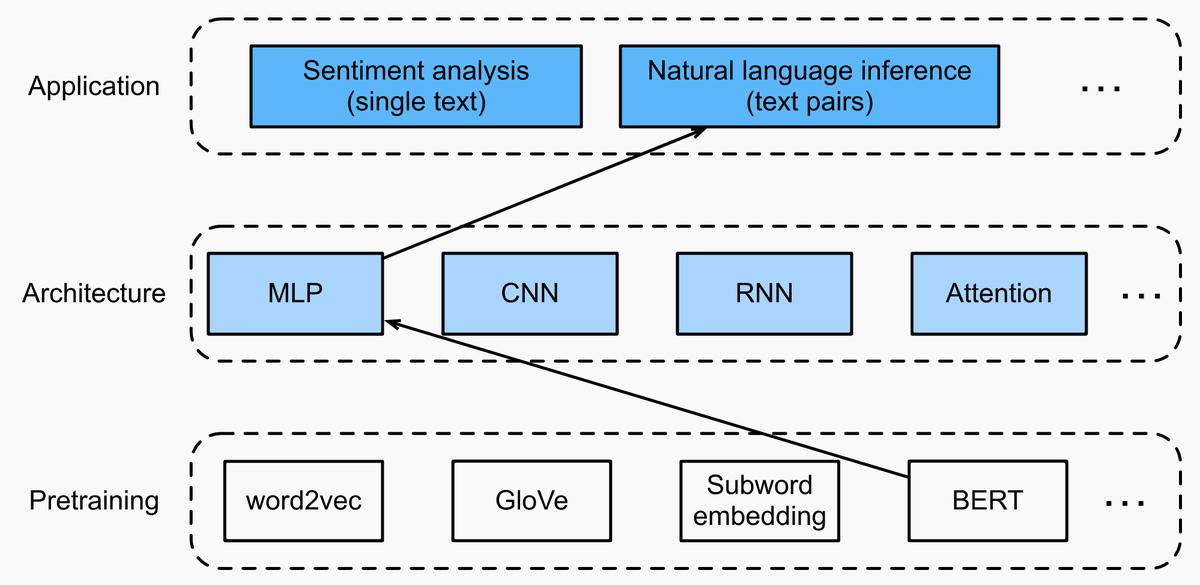
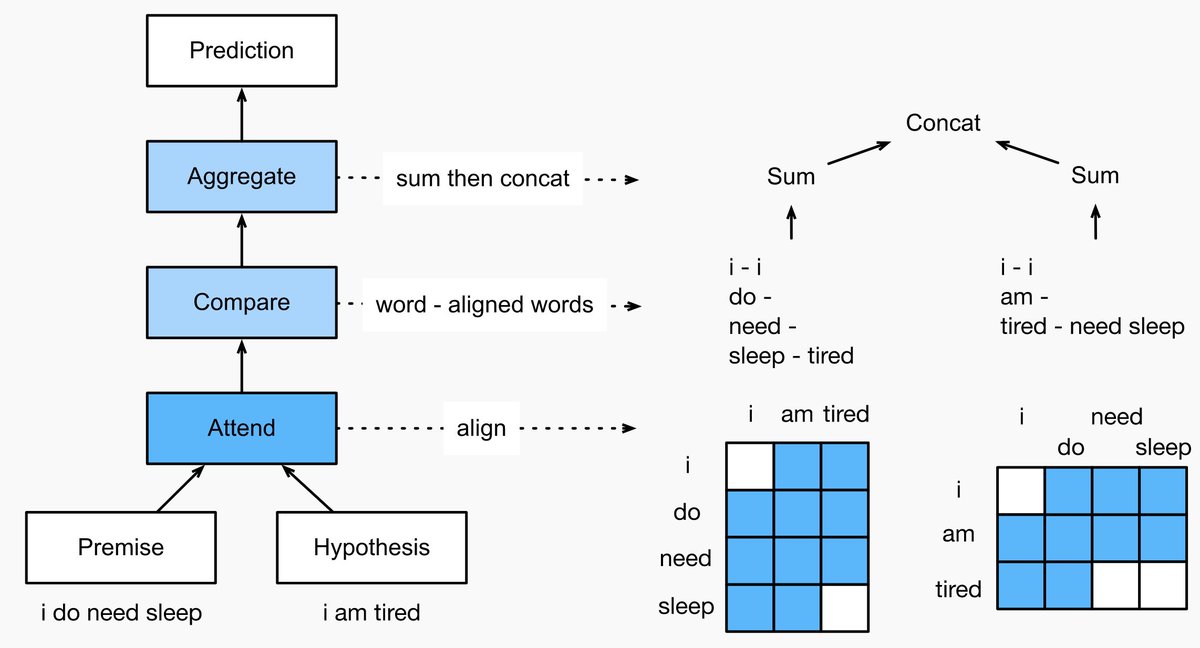
0
2
6

One release closer to v1.0!.
Dive into Deep Learning v0.15.0 is released! More chapters are in PyTorch and TensorFlow. More chapters are close to v1.0. Adopted at 140 universities: if you use D2L to teach, apply for free computing resources by Nov 22. Check out



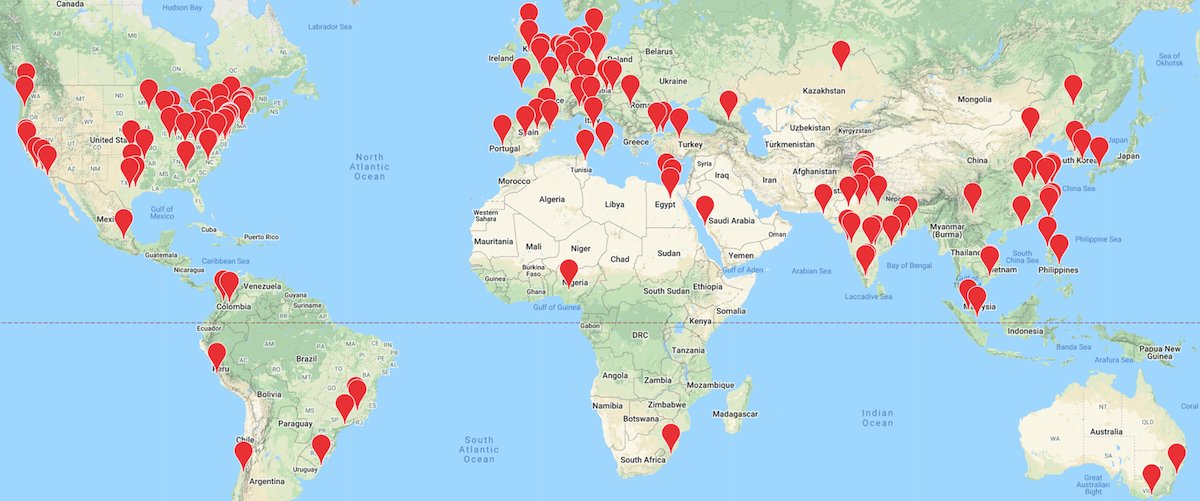
0
1
5
@purshow04 Thanks! We look forward to exchanging thoughts with the community to make AGI, together!.
2
0
6
@zacharylipton I probably know why you are asking this question. On Page 1 of "In this paper, we will focus on an efficient deep neural network . in conjunction with the famous “we need to go deeper” internet meme [1].".
0
1
6
A stop sign got recognized as a speed-limit sign due to backdoor samples? . Hard to unlearn backdoor behavior from the network?. Why unlearn? We can *bait and trap* backdoors in a small subnetwork, then *replace* it #NeurIPS2022.

Our #NeurIPS2022 paper proposes a decrease-and-conquer strategy for backdoor defense. The major finding: A simple image reconstruction loss can successfully trap backdoors into a small subnetwork while preserving the rest of the network largely uncontaminated (see Fig. 2).


0
0
5
D2L has an official Twitter account now!.
The best way to understand deep learning is learning by doing. Dive into Deep Learning ( is an interactive deep learning book on Jupyter notebooks, using the NumPy interface. Check it out:
0
2
5
@imrahulmaddy Starting with shorter sequences makes sense. Only when training seq len > local attn window size will extrapolation happen.
0
0
3
@BramVanroy The 400B model is still evolving. If you use 8B and 70B, yes you can build with them now.
0
1
5
@andrewgwils @Meta Thank you so much Andrew! We believe that the open approach will benefit the community and we handle it very carefully. Check out .
0
0
3
@zwhe99 The increased vocab size has a diminishing influence when model size increases. Grouped query attention helps to lower the inference cost. Given the benefit of token efficiency and benchmark eval boost, it's worth the upgrade.
0
0
3
@nazneenrajani @emnlpmeeting Show the timeline in the unit of weeks next time 😆 What does ✅ mean?.
0
0
4
@teortaxesTex You are referring to Llama 3 right? Increasing vocab size leads to slightly lower training wps and inference efficiency, but a more efficient tokenizer gives you more text for the same number of tokens. GQA also counter-balances inference efficiency.
1
0
3
@YiTayML @BalajiAI @PyTorch @zacharylipton @mli65 @smolix @rasoolfa @andrewgwils @kleiaaro @cedapprox @DavenCheung @BrentWerness Haha, of course. You’ll find something familiar in the references. Keep up all the amazing work!.
0
0
4
@JohnBlackburn75 @zhangzhuosheng @mli65 @smolix @AmazonScience @sjtu1896 @kojima_tks @shaneguML A human operator can simply invoke Auto-CoT as a function😀 I'd lean for being optimistic about future LLM-x's capabilities per comprehensive empirical evidences analyzed by @_jasonwei @YiTayML et al. in this must-read
0
0
4
AITW is a large-scale benchmark for UI control, which contains natural language instructions, screenshots, and actions. There are 30K unique instructions covering multi-step tasks such as app operation, web search, and web shopping. Auto-UI obtains new overall SOTA. [4/5]

1
0
3
In the parameter-efficient fine-tuning setting, we pretrain SPT on GLUE datasets and evaluate their fine-tuning performance on SuperGLUE datasets:. - SPT has better task transferability, even than full fine-tuning: SPT is cheaper & better. [3/4]

1
1
3
@JohnBlackburn75 @zhangzhuosheng @mli65 @smolix @AmazonScience @sjtu1896 Thanks John. @kojima_tks @shaneguML et al. have already found that GPT-3 is a decent zero-shot reasoner with just a light-weight "Let's think step by step" prompt. Check out their amazing work at
1
0
3
@smolix @D2L_ai @PyTorch @ApacheMXNet @gollum_here @mli65 @zacharylipton @AstonZhang Ah that's a wrong tweeter handle of me :).
0
0
3
@SubhankarGSH @MoeinShariatnia @zacharylipton @smolix @mli65 @gollum_here @TerryTangYuan Since the recent 1.0-alpha release, @PyTorch has become the default framework of our Dive into Deep Learning book 😃 Check it out:
2
0
3
To make machine learning more accessible, we worked with the SageMaker Studio Lab team to allow product users to benefit from open-source contributions to Our team @awscloud is hiring research interns and full-time (email to az at


0
1
3
@neptunewurld @D2L_ai @PyTorch @zacharylipton @mli65 @smolix @rasoolfa @andrewgwils @kleiaaro @cedapprox @DavenCheung @YiTayML @BrentWerness Coming soon with Cambridge University Press 😀.
1
0
3
@abdallah_fayed @rasoolfa @pratikac @AsadiKavosh @smolix @zacharylipton @mli65 More topics in this RL chapter are coming soon:.

Checkout new version of D2L book. It covers RL now! .@pratikac, @AsadiKavosh, and I authored the RL chapter. Please let us know your feedback!. Also, huge thanks to @smolix, @astonzhangAZ, @zacharylipton, @mli65 for their guidance and help. Stay tuned for more topics in RL!.
1
0
2
Thanks David @hardmaru.

Dive into Deep Learning: An interactive deep learning book with code, math, and discussions, based on the NumPy interface. I really like the format of the textbook!

1
2
2
@thegautamkamath @unsorsodicorda @zacharylipton @mli65 @smolix Yes, the 0.16.6 release for this version.
0
0
2
We fine-tune full LMs with SPT (semi-parametric prompt tuning) on 31 different tasks from 8 different domains and evaluate zero-shot generalization on 9 held-out datasets under 5 NLP task categories. Zero-shot generalization can scale up. [2/4]

1
0
2
0
0
2