

Zhuohan Li
@zhuohan123
Followers
3,271
Following
706
Media
9
Statuses
98
CS PhD 👨🏻💻 @ UC Berkeley 🌁 🤖️ Machine Learning Systems Building @vllm_project
Berkeley, CA
Joined January 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
WE ARE!
• 2100593 Tweets
GLAY
• 149127 Tweets
ロックの日
• 121152 Tweets
#光る君へ
• 108112 Tweets
#ModiCabinet
• 85503 Tweets
ムビナナ1周年
• 62061 Tweets
連続テレビ小説
• 30957 Tweets
JAM X ONE31
• 27177 Tweets
GenG
• 26351 Tweets
#アンチヒーロー
• 21812 Tweets
KALKI TRAILER OUT TOMORROW
• 21716 Tweets
IG PPNARAVIT 3M100K
• 17857 Tweets
Rashtrapati Bhavan
• 17130 Tweets
レイちゃん
• 13297 Tweets
うさぎさん
• 11582 Tweets
#だれかtoなかい
• 11439 Tweets
ONLYBOO LOVE AND DREAM
• 11082 Tweets





















Unlock the full potential of model parallelism with AlpaServe 🚀: Besides scaling models beyond one GPU, our new paper shows that model parallelism can process NN serving requests 10x faster even if the models fit into 1 GPU!
Paper:
👇 [1/8]

3
20
150
We are excited to announce the first vLLM Bay Area meetup at 6pm on 10/5 (Thu)! Please find the event details and RSVP at: .
The vLLM team will give a deep dive of vLLM and show the future roadmap. We will also have vLLM users and contributors share their

3
14
117
Excited to see vLLM being the default inference engine for the Microsoft Azure AI model catalog!
> Our default choice for serving models is vLLM, which provides high throughput and efficient memory management with continuous batching and Paged Attention.
Learn more in the blog
0
5
92
Deeply honored to be the first cohort of the program and a big shout-out to
@a16z
for setting up the grant and recognizing vLLM! Let's go, open source!

[New program] a16z Open Source AI Grants
Hackers & independent devs are massively important to the AI ecosystem.
We're starting a grant funding program so they can continue their work without pressure to generate financial returns.
71
269
1K
8
3
89
🔥 The core of vLLM is PagedAttention, a novel attention algorithm that brings the classic idea of paging in OS’s virtual memory to LLM serving. Without modifying the model, PagedAttention can batch 5x more sequences together, increasing GPU utilization and thus the throughput.
4
10
82
Excited to have first-hand official support of the Mixtral MoE model in vLLM from
@MistralAI
! Getting started with Mixtral with the latest vLLM now: . Be sure to check their announcing blog:
Joint with
@woosuk_k
@PierreStock

Very excited to release our second model, Mixtral 8x7B, an open weight mixture of experts model.
Mixtral matches or outperforms Llama 2 70B and GPT3.5 on most benchmarks, and has the inference speed of a 12B dense model. It supports a context length of 32k tokens. (1/n)



85
603
4K
0
5
73
PagedAttention's paper is out! Check it out to learn more!

Exciting news! 🎉Our PagedAttention paper is now up on arXiv! Dive in to learn why it's an indispensable technique for all major LLM serving frameworks.
@zhuohan123
and I will present it at
@sospconf
next month.
Blog post:
Paper:
2
34
188
2
4
49
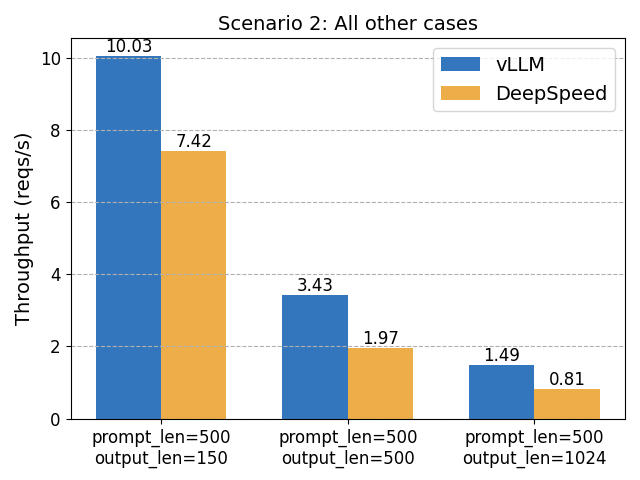
We've published a detailed blog post comparing vLLM with DeepSpeed-FastGen. Proud to highlight the unique strengths of vLLM, demonstrating better performance in various scenarios. Blog:
We’ve just released a new blog post comparing vLLM with DeepSpeed-FastGen. While we are happy to see the open-source technology advancements from the DeepSpeed team, we’ve got different results with more extensive performance benchmarks. vLLM is actually faster than DeepSpeed in
3
30
209
0
2
39
AMD + vLLM = 🚀🚀🚀

Update: Let's look at some new inference performance data on AMD Instinct MI300X
8
50
250
0
3
38
🦸 vLLM has been the unsung hero behind
@lmsysorg
Chatbot Arena and Vicuna Demo since April, handling peak traffic & serving popular models with high efficiency. It has cut the number of GPUs used at LMSYS by half while serving an average of 30K conversations daily.

1
3
36
Come and join the third vLLM bay area meetup!

The vLLM Team is excited to announce our Third vLLM Meetup in San Carlos on April 2nd (Tuesday). We will be discussing feature updates and hear from you! We thank
@Roblox
for hosting the event!
0
7
26
0
4
29

Check out this great blog from anyscale that shows the great performance of vLLM!

I wrote about a 23x improvement (!) in LLM live-inference throughput, measured on OPT-13B on A100. There are 2 new innovations which make this possible: Continuous batching & PagedAttention. Short thread below; see writeup, experiments, and results at

2
51
245
0
5
28
This is a joint work of
@woosuk_k
,
@zhuohan123
,
@zsy9509
,
@ying11231
,
@lm_zheng
,
@CodyHaoYu
,
@profjoeyg
,
@haozhangml
, Ion Stoica.
Check out our blog post and GitHub repo to start using vLLM now!
Paper coming soon.
1
3
26
Enojyed
#ICML2022
and met lots of new and old friends! Gave a tutorial on large models with
@haozhangml
@lm_zheng
and Ion on Monday (Learn more: ). Will still be around tomorrow and happy to chat!


0
2
25
Checkout this great blogpost from
@skypilot_org
: SkyPilot + vLLM = fastest and cheapest LLM serving on any cloud!

UC Berkeley's vLLM + SkyPilot speeds up LLM serving by 24x 🤩
Our user blog post on how SkyPilot combated GPU availability for
#vLLM
, allowing them to focus on AI and not infra.
(Also includes a 1-click guide to run it on your own cloud account!)
1
18
80
1
4
22
Excited to see Lepton
@jiayq
go beta! Lepton AI has first-class support for vLLM. Launching vLLM with one line on lepton:

We transparently support PyTorch, HuggingFace Transformer, and other common AI libraries at the base. We also work closely with awesome open source libraries like vLLM - in fact, launching vLLM has never been easier.
1
1
17
0
2
21
It was a super exciting and rewarding experience to see the community grow! We will continue to grow the community. Come and join the project to make LLM available to everyone!

We are doubling our committer base for vLLM to ensure it is best-in-class and a truly community effort. This is just a start. Let's welcome
@KaichaoYou
,
@pcmoritz
,
@nickhill33
,
@rogerw0108
,
@cdnamz
,
@robertshaw21
as committers and thank you for your great work! 👏

2
4
32
0
0
20
Check out our new work Alpa: one-line code change to model parallel deep learning!

Alpa is a framework that uses just one line of code to easily automate the complex model parallelism process for large
#DeepLearning
models. Learn more and check out the code.
6
99
372
0
0
19
Great work from
@anyscalecompute
!

Recently, we’ve contributed chunked prefill to
@vllm_project
, leading to up to 2x speedup for higher QPS regimes!
In vLLM, prefilling, which fills the KV cache, and decoding, which outputs new tokens, can interfere with each other, resulting in latency degradation. 1/n

4
23
96
1
1
17
Check out our latest Vicuna! Try the demo to see how well it works!

Introducing Vicuna, an open-source chatbot impressing GPT-4!
🚀 Vicuna reaches 90%* quality of ChatGPT/Bard while significantly outperforming other baselines, according to GPT-4's assessment.
Blog:
Demo:
58
548
2K
1
0
16
@haozhangml
@tianle_cai
Probably because most data cleaning pipeline is designed for English?
0
0
17
Join us in SF on June 11!
We are holding the 4th vLLM meetup at
@Cloudflare
with
@bentomlai
on June 11. Join us to discuss what's next in production LLM serving! Register at
0
8
23
0
0
16
Check our latest work! We show that accelerate BERT and MT training & inference by _increasing_ model size and stopping early!
Blog:
Paper:
w/
@Eric_Wallace_
,
@shengs1123
,
@nlpkevinl
, Kurt Keutzer, Dan Klein,
@mejoeyg


Not everyone can afford to train huge neural models. So, we typically *reduce* model size to train/test faster.
However, you should actually *increase* model size to speed up training and inference for transformers.
Why? [1/6] 👇


16
369
1K
0
1
14
Our new work! Paper can be found at
Codes and pretrained models can be found at


Happy to introduce my new work joint working with
@zhuohan123
Understanding the neural network as an ODE, we interpret Transformer in NLP as a multi-particle system. Every word in the sentence is a particle and a numerical scheme splits the convection and diffusion term is used


0
0
12
0
3
13
@woosuk_k
and I will give a talk at the Ray Summit this year about vLLM. Come and talk to us!

Ray Summit this month will be 🔥🔥
🤯 ChatGPT creator
@johnschulman2
🧙♀️
@bhorowitz
on the AI landscape
🦹♂️
@hwchase17
on LangChain
🧑🚀
@jerryjliu0
on LlamaIndex
👨🎤
@zhuohan123
and
@woosuk_k
on vLLM
🧜
@zongheng_yang
on SkyPilot
🧑🔧
@MetaAI
on Llama-2
🧚♂️
@Adobe
on Generative AI in
8
45
207
0
1
11
We are also organizing an
#ICML22
tutorial on how to train huge neural networks next Monday in Baltimore. Come and learn more about how to scale your fancy neural networks!

2
2
9
Please come and join us in SF to talk about the exciting future of vLLM!
We are hosting The Second vLLM Meetup in downtown SF on Jan 31st (Wed). Come to chat with vLLM maintainers about LLMs in production and inference optimizations! Thanks
@IBM
for hosting us.
3
9
37
0
0
11
@k3nnethfrancis
@woosuk_k
@lmsysorg
It works for both remote and local models! Will add this into the doc.
2
1
9
Check our paper for more! We will release the code in the alpa project repo soon.
Paper:
Github:
With
@lm_zheng
, Yinmin Zhong, Vincent Liu,
@ying11231
, Xin Jin,
@bignamehyp
, Zhifeng Chen,
@haozhangml
,
@profjoeyg
, Ion Stoica [8/8]
0
2
7
@HamelHusain
Great results! Have you considered running throughput benchmarks as well? The current benchmarks focus on latency, which is not vLLM's most optimizations are focusing on :)
0
0
6
With model parallelism, both GPUs can hold parts of both models. Bursty requests to one model can be processed by both GPUs together. [5/8]

1
0
5
A serving system often needs to serve multiple models at once. Models often receive bursty requests up to 50x the average. [2/8]

1
0
3
In AlpaServe, we use model parallelism to handle these bursty requests. In the following example of serving 2 models on 2 GPUs, with naive placement, each GPU can only fit 1 model. Bursty requests to one model can only be handled by 1 GPU. The other GPU will be idle. [4/8]

1
0
3
Model parallelism partitions a single deep learning model into multiple parts and executes it on distributed devices. It is originally developed to scale large models beyond the memory limits of a single device. [3/8]

1
0
3
We test AlpaServe with production workloads on a 64-GPU cluster. AlpaServe can increase the request processing rate of smaller models by 10×, and larger models at chatGPT scale by 8x. [7/8]
2
0
3
Introducing model parallelism in serving leads to a complex design trade-off space. In AlpaServe, we thoroughly study the space and design novel algorithms to generate efficient model-parallel schedules. [6/8]
1
0
2


@Ozan__Caglayan
@Eric_Wallace_
Check this repo if you want to crawl and do some basic preprocessing for bookcorpus:
0
0
2
@winglian
There should be nothing preventing you from doing this. What is the issue you meet when you try to run such a long sequence?
1
0
1