
Woosuk Kwon
@woosuk_k
Followers
4K
Following
2K
Media
2
Statuses
259
PhD student at @Berkeley_EECS building @vllm_project
Joined April 2023
As one of the fastest-growing OSS projects, vLLM inevitably accumulated some technical debts. We noticed it, and re-architected vLLM's core with careful engineering. Enjoy simpler code & higher performance with vLLM V1!.

🚀 With the v0.7.0 release today, we are excited to announce the alpha release of vLLM V1: A major architectural upgrade with 1.7x speedup! .Clean code, optimized execution loop, zero-overhead prefix caching, enhanced multimodal support, and more.

2
17
210
RT @zhuohan123: I’ve been fortunate to lead the infra and inference work that brings gpt-oss to life. A year ago, I joined OpenAI after bui….
0
144
0
Here's the blog post on vLLM's integration:
blog.vllm.ai
We’re thrilled to announce that vLLM now supports gpt-oss on NVIDIA Blackwell and Hopper GPUs, as well as AMD MI300x and MI355x GPUs. In this blog post, we’ll explore the efficient model architecture...
Thank you @OpenAI for open-sourcing these great models! 🙌.We’re proud to be the official launch partner for gpt-oss (20B & 120B) – now supported in vLLM 🎉.⚡ MXFP4 quant = fast & efficient.🌀 Hybrid attention (sliding + full).🤖 Strong agentic abilities.🚀 Easy deployment.👉🏻.
0
9
73
RT @vllm_project: Thank you @OpenAI for open-sourcing these great models! 🙌.We’re proud to be the official launch partner for gpt-oss (20B….
0
63
0
RT @vllm_project: The model is supported in vLLM, welcome to try this powerful model on your own🚀.
0
11
0
RT @vllm_project: vLLM has just reached 50K github stars! Huge thanks to the community!🚀.Together let's bring easy, fast, and cheap LLM ser….
0
21
0
RT @AurickQ: Excited to share our work on Speculative Decoding @Snowflake AI Research!. 🚀 4x faster LLM inference for coding agents like Op….
0
38
0
RT @JustinLin610: Thanks for the quick merge and instant support for our models! Users of vllm and Qwen, feel free to try it out to see whe….
0
12
0
RT @OpenAIDevs: Announcing the first Codex open source fund grant recipients:. ⬩vLLM - inference serving engine @vllm_project.⬩OWASP Nettac….
0
149
0
RT @vllm_project: perf update: we are continuing to see benefits with vLLM V1 engine’s highly performant design. on 8xH200, vLLM leads in t….
0
42
0
RT @vllm_project: vLLM🤝🤗! You can now deploy any @huggingface language model with vLLM's speed. This integration makes it possible for one….

blog.vllm.ai
The Hugging Face Transformers library offers a flexible, unified interface to a vast ecosystem of model architectures. From research to fine-tuning on custom dataset, transformers is the go-to...
0
127
0
RT @vllm_project: 🙏 @deepseek_ai's highly performant inference engine is built on top of vLLM. Now they are open-sourcing the engine the ri….

github.com
Production-tested AI infrastructure tools for efficient AGI development and community-driven innovation - deepseek-ai/open-infra-index
0
349
0

RT @hmellor_: Another month, another open-source milestone for the @vllm_project 🎉. now has 1000 contributors 🚀 htt….
0
4
0
RT @Agentica_: Introducing DeepCoder-14B-Preview - our fully open-sourced reasoning model reaching o1 and o3-mini level on coding and math.….
0
210
0
RT @yi_xin_dong: XGrammar is accepted to MLSys 2025🎉🎉🎉.It is a widely adopted library for structured generation with LLMs—output clean JSON….
0
18
0
RT @vllm_project: vLLM v0.8.3 now supports @AIatMeta's latest Llama 4 Scout and Maverick. We see these open source models as a major step f….
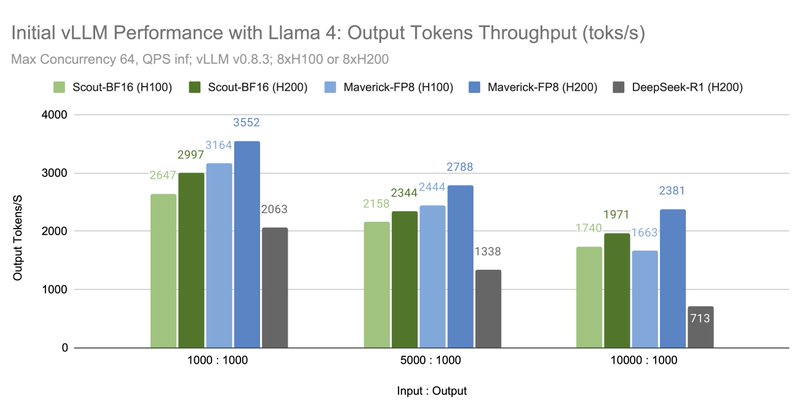
blog.vllm.ai
We’re excited to announce that vLLM now supports the Llama 4 herd of models: Scout (17B-16E) and Maverick (17B-128E). You can run these powerful long-context, natively multi-modal (up to 8-10 images...
0
37
0
RT @Ahmad_Al_Dahle: Introducing our first set of Llama 4 models!. We’ve been hard at work doing a complete re-design of the Llama series. I….
0
934
0
RT @robertnishihara: If you're using vLLM + Ray for batch inference or online serving, check this out. We're investing heavily in making th….
0
1
0
