
Mor Geva
@megamor2
Followers
2K
Following
3K
Media
53
Statuses
534
Assistant Professor at @TelAvivUni and Research Scientist at @GoogleResearch; previously postdoc at @GoogleDeepMind and @allen_ai
Joined April 2017
The Azrieli International Postdoc Fellowship is now open!.Email me if you're interested in joining my group next year in vibrant Tel Aviv for AI interpretability research 💫.
2
6
39
RT @ayeletkatzir10: משרד החינוך הסיר פרקים על דמוקרטיה ליברלית מהבגרות באזרחות. מדובר ברפורמה שקטה. שר החינוך לא יכריז עליה בטקס חגיגי, כי….
0
192
0

More parameters and inference-time compute is NOT always better.In @soheeyang_’s #EMNLP2025 Findings paper, we show that larger reasoning models struggle more to recover from injected unhelpful thoughts 💉 this fragility extends to jailbreak attacks 🦹♂️.

🚨 New Paper 🧵.How effectively do reasoning models reevaluate their thought? We find that:.- Models excel at identifying unhelpful thoughts but struggle to recover from them.- Smaller models can be more robust.- Self-reevaluation ability is far from true meta-cognitive awareness

0
1
25
Finally went for a run today after 7 years off. Damn that was good.
3
0
37
גם אני תרמתי, תמשיך להצליח!.

לצורך מימון אבטחה והרחבת הפעילות כבר בימים הקרובים לעוד ערים חרדיות - אנחנו זקוקים לתרומה שלכם. יש סיבה שהפעולה שלנו לקידום מדע והשכלה כל כך מפחידה אותם. היא עובדת.

0
0
5
Removing certain knowledge from LLMs is hard. Our lab has been tackling this problem at the level of model parameters. Excited to have two papers on this topic accepted at #EMNLP2025 main conf:.⭐️Precise In-Parameter Concept Erasure in Large Language Models.
1
10
106
RT @TomerWolfson: Many factual QA benchmarks have become saturated, yet factuality still poses a very real issue!. ✨We present MoNaCo, an A….
0
14
0
RT @mariusmosbach: @ChrisGPotts Thanks a lot for sharing this! To add to your 4th point: we made an attempt to quantify this impact in our….

arxiv.org
Interpretability and analysis (IA) research is a growing subfield within NLP with the goal of developing a deeper understanding of the behavior or inner workings of NLP systems and methods....
0
2
0
@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro @dhgottesman @DanaRamati @GurYoav @IdoC0hen @RGiryes @AmitElhelo 📍2025-07-31 REALM workshop spotlight, Room 1.61-62.@ohavba will present an approach for improving multi-agent collaboration that relies on monitoring and interventions + a cool modular environment called WhoDunIt. @OriYoran.

"One bad apple can spoil the bunch 🍎", and that's doubly true for language agents!.Our new paper shows how monitoring and intervention can prevent agents from going rogue, boosting performance by up to 20%. We're also releasing a new multi-agent environment 🕵️♂️
0
1
9
@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro @dhgottesman @DanaRamati @GurYoav @IdoC0hen @RGiryes 📍2025-07-30 9:00 - 10:30 Room 1.85.@AmitElhelo will introduce MAPS, a general framework for inferring the functionality of attention heads in LLMs directly from their parameters.
What's in an attention head? 🤯. We present an efficient framework – MAPS – for inferring the functionality of attention heads in LLMs ✨directly from their parameters✨. A new preprint with @AmitElhelo 🧵 (1/10)

1
2
9
@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro @dhgottesman @DanaRamati @GurYoav 📍2025-07-29 10:30 - 12:00 Hall 4/5.@IdoC0hen will show a critical gap in knowledge recall performance of VLMs across modalities.@dhgottesman @RGiryes.

A Vision-Language Model can answer questions about Robin Williams. It can also recognize him in a photo. So why does it FAIL when asked the same questions using his photo instead of his name?. A thread on our new #acl2025 paper that explores this puzzle 🧵
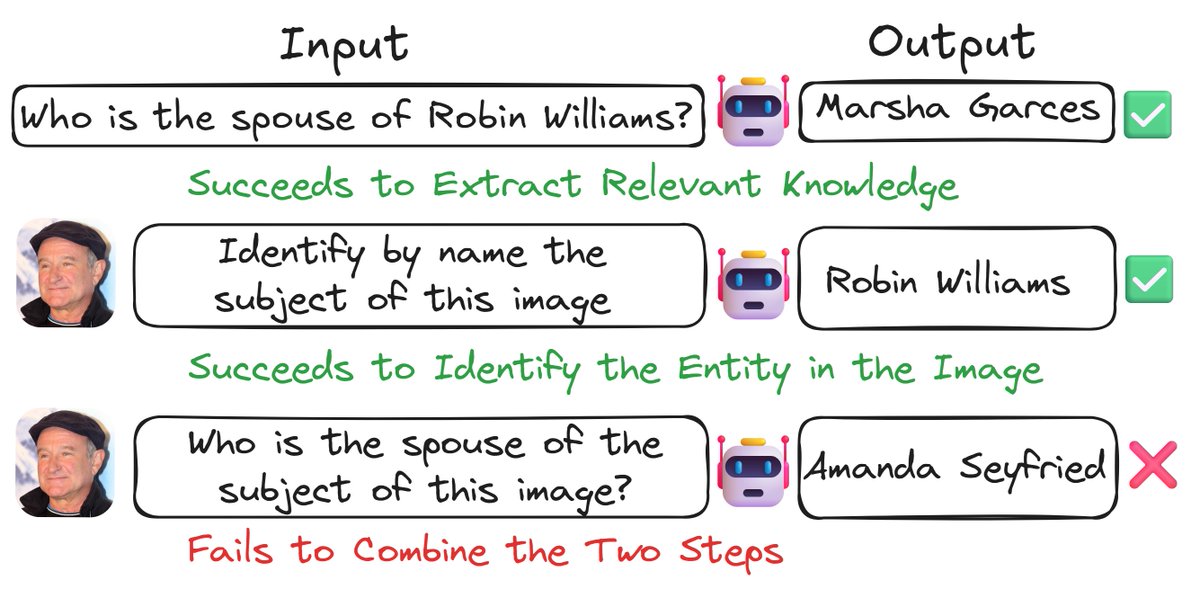
1
1
5
@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro @dhgottesman @DanaRamati 📍2025-07-29 10:30 - 12:00 Hall 4/5.@GurYoav will talk about interpreting features in LLMs, arguing that only looking at activating inputs gives a partial view and introducing output-centric methods that effectively explain the feature's causal effect.
How can we interpret LLM features at scale? 🤔.Current pipelines use activating inputs, which is costly and ignores how features causally affect model outputs!.We propose efficient output-centric methods that better predict how steering a feature will affect model outputs. New
1
1
7
@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro 📍2025-07-28 18:00 - 19:30 Virtual.@dhgottesman will present InSPEcT — a causal method that interprets continuous prompts by eliciting descriptions from their internal representations during model inference. @DanaRamati.

Can continuous prompts be understood?. In our latest paper, with @megamor2 and @dhgottesman , we introduced InSPEcT — a method that interprets continuous prompts by eliciting descriptions from their internal representations during model inference. Paper:

1
0
3