

Volodymyr Kuleshov 🇺🇦
@volokuleshov
Followers
9K
Following
2K
Media
456
Statuses
3K
Co-Founder @InceptionAILabs | Prof @Cornell & @Cornell_Tech | PhD @Stanford
Joined July 2013
Excited to announce the first commercial-scale diffusion language model---Mercury Coder. Mercury runs at 1000 tokens/sec on Nvidia hardware while matching the performance of existing speed-optimized LLMs. Mercury introduces a new approach to language generation inspired by image.

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.
31
34
390
This wild. Take MNIST, feed it pixel by pixel to an LLM, followed by the label (“x1=5, x2=9, …, y=3”). Fine tune on this dataset. This reaches 99% accuracy. Also works on other small datasets.

29
106
1K
Did you ever want to learn more about machine learning in 2021? I'm excited to share the lecture videos and materials from my Applied Machine Learning course at @Cornell_Tech! We have 20+ lectures on ML algorithms and how to use them in practice. [1/5]
20
282
1K
It's crazy how many modern generative models are 15-year old Aapo Hyvarinen papers. Noise contrastive estimation => GANs.Score matching => diffusion.Ratio matching => discrete diffusion. If I were a student today, I'd carefully read Aapo's papers, they’re a gold mine of ideas.

10
110
1K
Do you know what's cooler than running LLMs on consumer GPUs? Finetuning large 65B+ LLMs on consumer GPUs! 🤖. Check out my new side project: LLMTune. It can finetune 30B/65B LLAMA models on 24Gb/48Gb GPUs.

16
160
738
Compressing MNIST into 10 synthetic images that give almost the same performance as the full dataset. Cool paper!

7
167
648
Ok, I'm sorry, but this is just brilliant. Folks argue that AI can't make art, but look: (1) DALLE2 distills the essence of NY in a stunning & abstract way (2) each pic has unique visual language (bridge-loops in #1!?) (3) it *builds* (not copies) something new on top of Picasso!.




23
84
626
Excited to announce the newest update to the Cornell Open Applied ML course!. We are releasing 16 chapters of open online lecture notes covering topics across ML: neural networks, SVMs, gradient boosting, generative models, and much more.
9
130
613
We are publishing online the notes for the Probabilistic Graphical Models course at Stanford (work in progress!)

5
179
522
The award for the most clearly understandable poster goes to… this person!

9
24
520
Mamba? DeltaNet? RWKV? RetNet? Here is a nice chart in which they’re all variants of the same formula.

5
37
417
Here is an experiment: using ChatGPT to emulate a Jupyter notebook. You can even get it to run GPT inside ChatGPT. And you can also train neural networks from scratch inside ChatGPT.🤯. Here's walkthrough of how it works.

9
54
407
ICLR decisions are now public, and it's confirmed that the recent (pretty high-profile) Mamba paper didn't get in. It's useful to read OpenReview to see how subjective the peer review process can be. The moral is: don't stress if your paper doesn't get in from the first try!

7
37
337
Christopher Bishop is publishing a new textbook!
2
113
321
If you're at #AAAI2025, try to catch Cornell PhD student @yingheng_wang, who just presented a poster on Diffusion Variational Inference. The main idea is to use a diffusion model as a flexible variational posterior in variational inference (e.g., as the q(z|x) in a VAE) [1/3]

3
22
332
Two-bit and three-bit LLMs are almost here! . QuiP yields the first usable two-bit LLMs and further reduces the costs of running LLMs on just one GPU. [1/4]. paper: code:

4
84
315
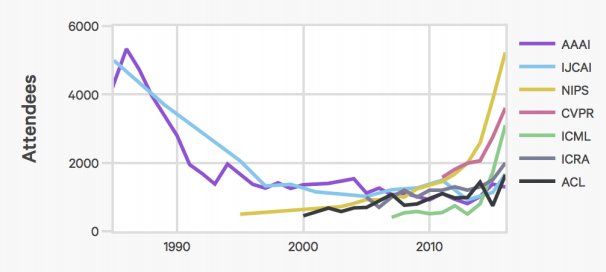
I love this chart from the AI index report. You clearly see the peak of 80's AI hype and its slow drop-off. We seem to have just matched the conference attendance numbers from back then.
8
156
280
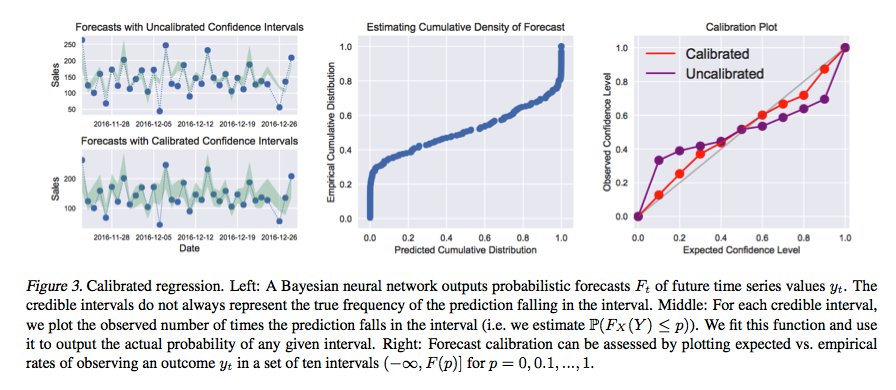
Imagine you build an ML model with 80% accuracy. There are many things you can try next: collect data, create new features, increase dropout, tune the optimizer. How do you decide what to try next in a principled way?

2
55
271
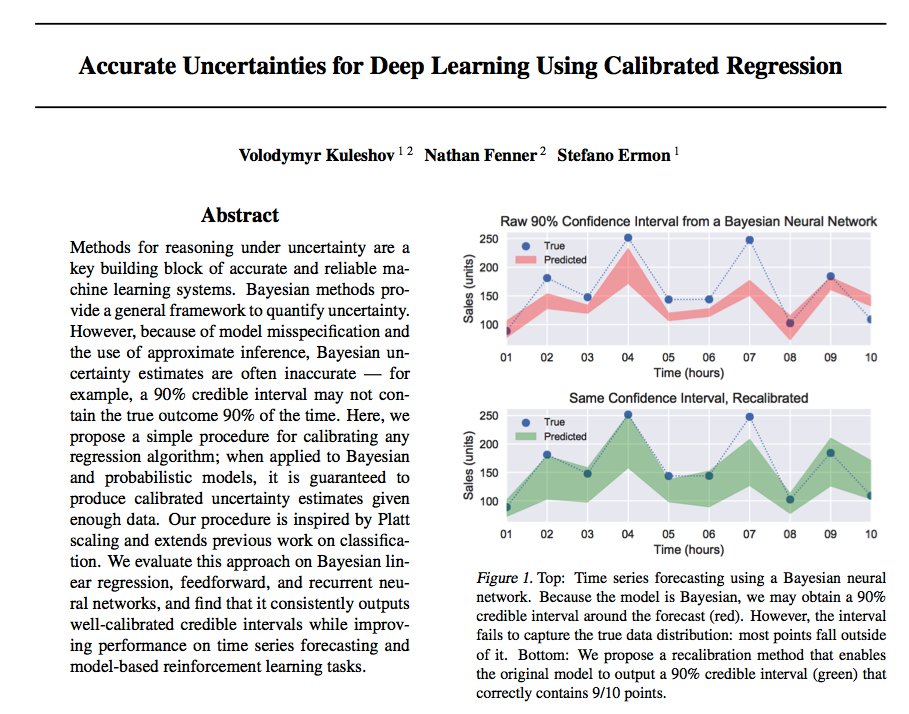
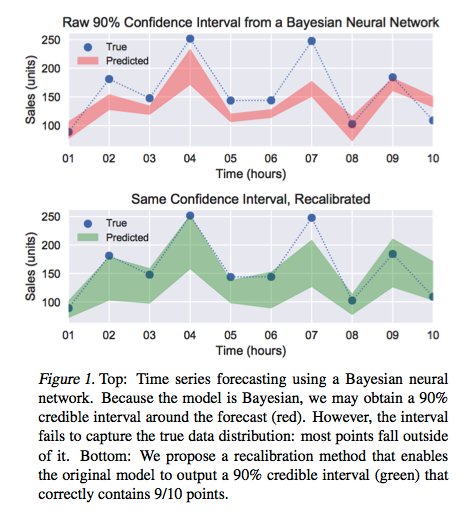

My weekend side project: MiniLLM, a minimal system for running modern LLMs on consumer GPUs✨. 🐦 Supports multiple LLMs (LLAMA, BLOOM, OPT).⚙️ Supports NVIDIA GPUs, not just Apple Silicon.🧚♀️ Tiny, easy-to-use codebase in Python (<500 LOC).

9
48
260
Excited to finally release our open course on deep generative models! This material has been taught at Stanford/Cornell/UCLA since 2019. It includes .🎥 20 hours of video lectures.✨ 17 sets of slides.📖 Lecture notes. Youtube: Site:

9
51
260
Neat and simple NeurIPS paper: take a pre-trained BERT and generate from it auto-regressively (sequentially unmasking the last token in context window). This does surprisingly well on benchmarks.

4
16
253
As promised, here is a summary of @cornell_tech Applied ML 2021 Lecture 1: "What is ML?". The main idea is that machine learning is a form of programming, where you create software by specifying data and a learning algorithm instead of writing traditional code.

2
34
235
Super resolution for audio. Our expanded paper is now on ArXiv + implementation + companion website:


2
84
228
What are the benefits of using deep learning in causal inference? Thoughts based on Monday morning's ICML tutorial on causality + my own opinions. 👇. Slides are from the tutorial (link is below).

5
26
226
Loved this nice and simple idea for better data selection in LMs. First, use high level features to describe high-value data (eg textbook chunks). Then use importance sampling to prioritize similar data in a large dataset. @sangmichaelxie

2
29
228
📢 Announcing the newest edition of the Cornell Tech open machine learning course!.- 📺 30+ hours of lecture videos.- 📕 Lecture notes, slides, and code for 20+ lectures.- 🌎 A brand new website. Check it out here:

4
67
213
Introducing test-time compute scaling for discrete diffusion LLMs! This almost matches AR LLM sample quality using diffusion. In traditional masked diffusion, once a token is unmasked, it can never be edited again, even if it contains an error. Our new remasking diffusion allows


We are excited to present ReMasking Diffusion Models (ReMDM), a simple and general framework for improved sampling with masked discrete diffusion models that can benefit from scaled inference-time compute. Without any further training, ReMDM is able to enhance the sample quality
4
23
200
✨Simple masked diffusion language models (MDLM) match autoregressive transformer performance within 15% at GPT2 scale for the first time!. 📘Paper: 💻Code: 🤖Model: 🌎Blog: [1/n]👇
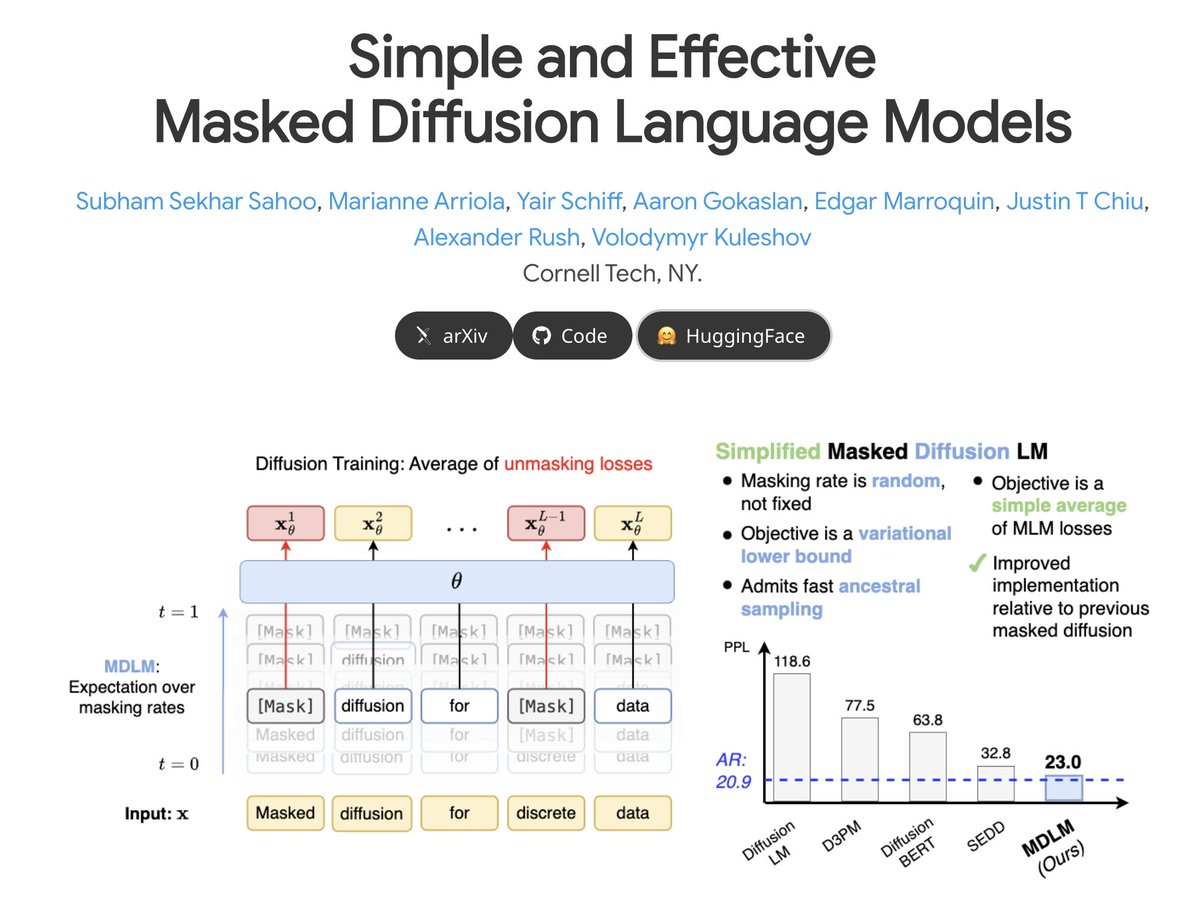
4
38
194
Another SOTA multi-task NLP result from MSFT. What is it about the Transformer architecture that is making these advances possible? Why have we not seen the same results with LSTM-based methods like Dai and Le (2015)?.
1
38
180
The slides and lectures notes that accompany my videos from the Applied Machine Learning course at Cornell are now available on Github! . I'm sharing 20+ Jupyter notebooks that you can compile into HTML, PDF, or execute directly.

2
47
171
They claim that replacing the final softmax layer in a nn speeds up training by 33% on SOTA cifar-10 and ImageNet:
3
56
170
Slides from my talk at the @uai2018 workshop on uncertainty in deep learning. Thanks again to the organizers for inviting me!




3
40
165
Last April, we released libraries for 3-bit and 4-bit LLM inferencing & finetuning. We've had a lot of interest in our code (including 1k+ stars on Github), and we're now officially releasing the underlying algorithm: ModuLoRA. ModuLoRA is the first method to finetune 3-bit LLMs!

6
31
164
It's surprising how little core ML innovation was needed to create Sora. As with GPT, the OAI team took a proven architecture (latent diffusion), and scaled it to massive data, with incredible results. Still, it's interesting to look at the details that OAI chose to reveal 1/👇

3
15
159
New paper on black-box learning of undirected models using neural variational inference. Also speeds up sampling and helps estimate the partition function. Our #nips2017 paper is online here:


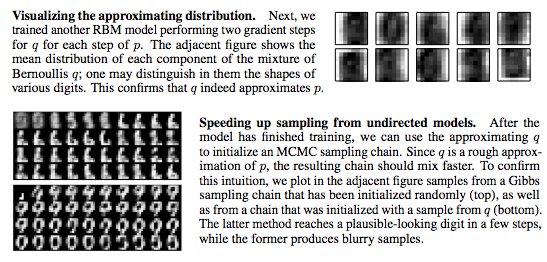
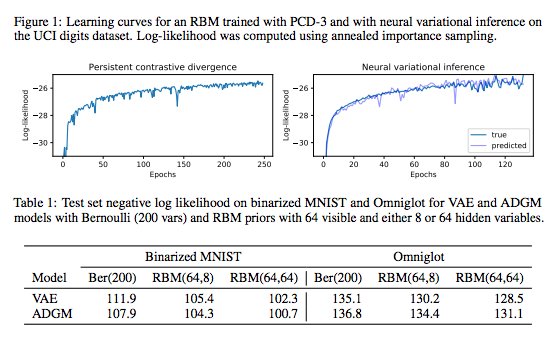
2
46
153
Update on my fall 2021 @cornell_tech applied ML course. Each week, I will be releasing all the slides, lecture notes, and course materials on Github, and I also plan to post summaries of each lecture on Twitter. Everybody is welcome to follow along!.
1
23
135
New update from the world of LLM quantization: QuIP will appear at NeurIPS2023, and our updated paper is now on the ArXiv. QuIP is the first method that gets useful results out of LLMs quantized using as little as 2 bits/weight. Camera-ready:

8
24
133
And the prize for the most technologically sophisticated poster goes to… this author! Two built-in tablets—first time I see this at a conference.

4
13
124
I really enjoyed the ICML tutorial on causality and fairness by Elias Bareinboim and Drago Plecko. My summary and some thoughts below 👇

1
17
121
✨Introducing diffusion with learned adaptive noise, a new state-of-the-art model for density estimation✨. Our key idea is to learn the diffusion process from data (instead of it being fixed). This yields a tighter ELBO, faster training, and more!. Paper:

2
29
117
If you’re at #iclr2025, you should catch Cornell PhD student @SchiffYair—check out his new paper that derives classifier-based and classifier-free guidance for discrete diffusion models.
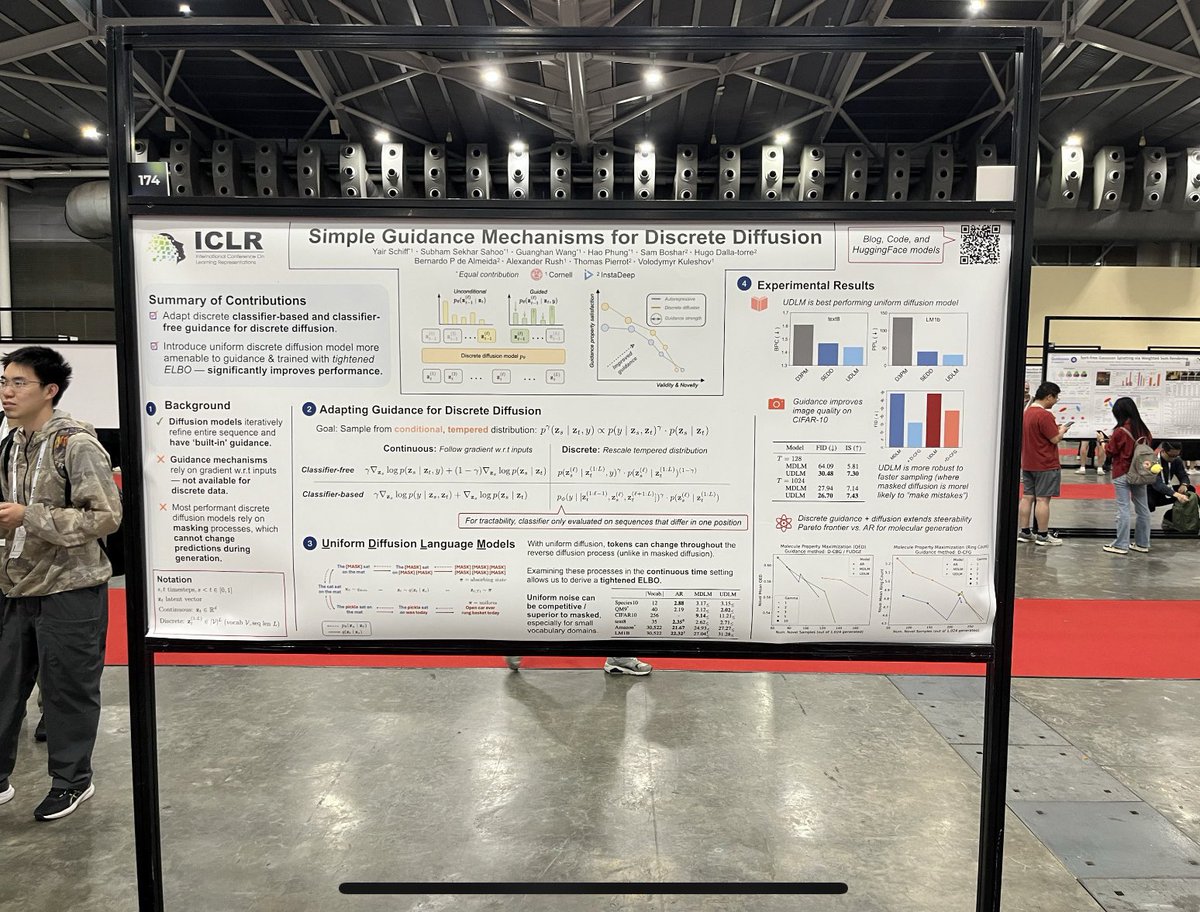

Diffusion models produce high quality outputs and have powerful guidance mechanisms. Recently, discrete diffusion has shown strong language modeling. ❓Can we adapt guidance mechanisms for discrete diffusion models to enable more controllable discrete generation? . 1/13 🧵
0
10
121
This is absolutely mind-blowing. Finding these kinds of disentangled representations has been a goal of generative modeling research for years. The fact that style-based GANs do it so well in a purely unsupervised way and without a strong inductive bias is just crazy.

An exciting property of style-based generators is that they have learned to do 3D viewpoint rotations around objects like cars. These kinds of meaningful latent interpolations show that the model has learned about the structure of the world.
3
26
113
I’d like to share a little update on what I’ve been up to in the past two years. 🙂.
3
22
114
Cool work on semantic manipulations in diffusion models:

2
13
105
Masked diffusion language modeling to appear at #NeurIPS2024. MDLM matches the quality of autoregressive transformers using diffusion! 🔥. Also featuring new improvements since this summer: connections to score estimation, pre-trained model, full codebase 👇.
✨Simple masked diffusion language models (MDLM) match autoregressive transformer performance within 15% at GPT2 scale for the first time!. 📘Paper: 💻Code: 🤖Model: 🌎Blog: [1/n]👇
1
16
107
New paper out in @NatureComms! GWASkb is a machine-compiled knowledge base of genetic studies that approaches the quality of human curation for the first time. With @ajratner @bradenjhancock @HazyResearch @yang_i_li et al. Last paper from the PhD years.
2
13
88
"A Guide to Deep Learning in Healthcare" out in @NatureMedicine this week! Joint work with amazing team of collaborators @AndreEsteva @AlexandreRbcqt @rbhar90 @SebastianThrun @JeffDean M DePristo, C. Cui, K. Chou, G. Corrado. Paper:
1
33
86
2-bit LLaMAs are here! 🦙✨. The new QuIP# ("quip-sharp") algorithm enables running the largest 70B models on consumer-level 24Gb GPUs with a only minimal drop in accuracy. Amazing work led by Cornell students @tsengalb99 @CheeJerry + colleagues @qingyao_sun @chrismdesa . [1/n].
2
20
81
Model weights can be quantized into a small # of bits during inference. If we're a bit clever, we can also directly train quantized weights! Experiments should be *much* faster. Or fit many quantized models, then fine-tune best one at full precision.


0
27
83
Wow, this year's Burning Man theme is Artificial Intelligence! The description talks about automation, loss of jobs, safety, etc. A mix of valid concerns and hype. In any case, it should be a lot fun.

4
23
80
At #icml2018 in Stockholm this week! Come check our poster on improved uncertainty estimation for Bayesian models and deep neural networks on Thursday.

1
23
83
Official results from @ArtificialAnlys benchmarking the speeds of Mercury Coder diffusion LLMs at >1,000 tok/sec on Nvidia GPUs. This is a big deal for LLMs: previously, achieving these speeds required specialized hardware. Diffusion is a "software" approach that gets to the.

Inception Labs has launched the first production-ready Diffusion LLMs. Mercury Coder Mini achieves >1,000 output tokens/s on coding tasks while running on NVIDIA H100s - over 5x faster than competitive autoregressive LLMs on similar hardware. Inception’s Diffusion LLMs (“dLLMs”)

8
6
77
Love to see my machine learning lectures being shared online. Also, please stay tuned—I will be announcing a major new update to my online class in the next few days.

Applied Machine Learning - Cornell CS5785. "Starting from the very basics, covering all of the most important ML algorithms and how to apply them in practice. Executable Jupyter notebooks (and as slides)". 80 videos. Videos: Code:

2
12
75
We're hosting a generative AI hackathon at @cornell_tech on 4/23! Join us to meet fellow researchers & hackers, listen to interesting talks, access models like GPT4, and build cool things. Sponsors: @openai @LererHippeau @AnthropicAI @BloombergBeta.RSVP
5
13
74
After a summer break, I’m getting back to tweeting again. This Fall, I’m teaching Applied ML at @cornell_tech in this huge room (and this time in person). Stay tuned for updates as I’ll be sharing a lot of the lecture videos and materials over the next few months!


2
1
73

If you didn't get an invite to the Elon Musk / Tesla party tonight, come check out our poster on Neural Variational Inference in Undirected Graphical Models at board #108 :)

0
10
73
Benchmarking all the sklearn classifiers against each other. Gradient boosting comes out on top (confirming general wisdom)

Our preprint on a comprehensive benchmark of #sklearn is out. Some interesting findings! #MachineLearning #dataviz.
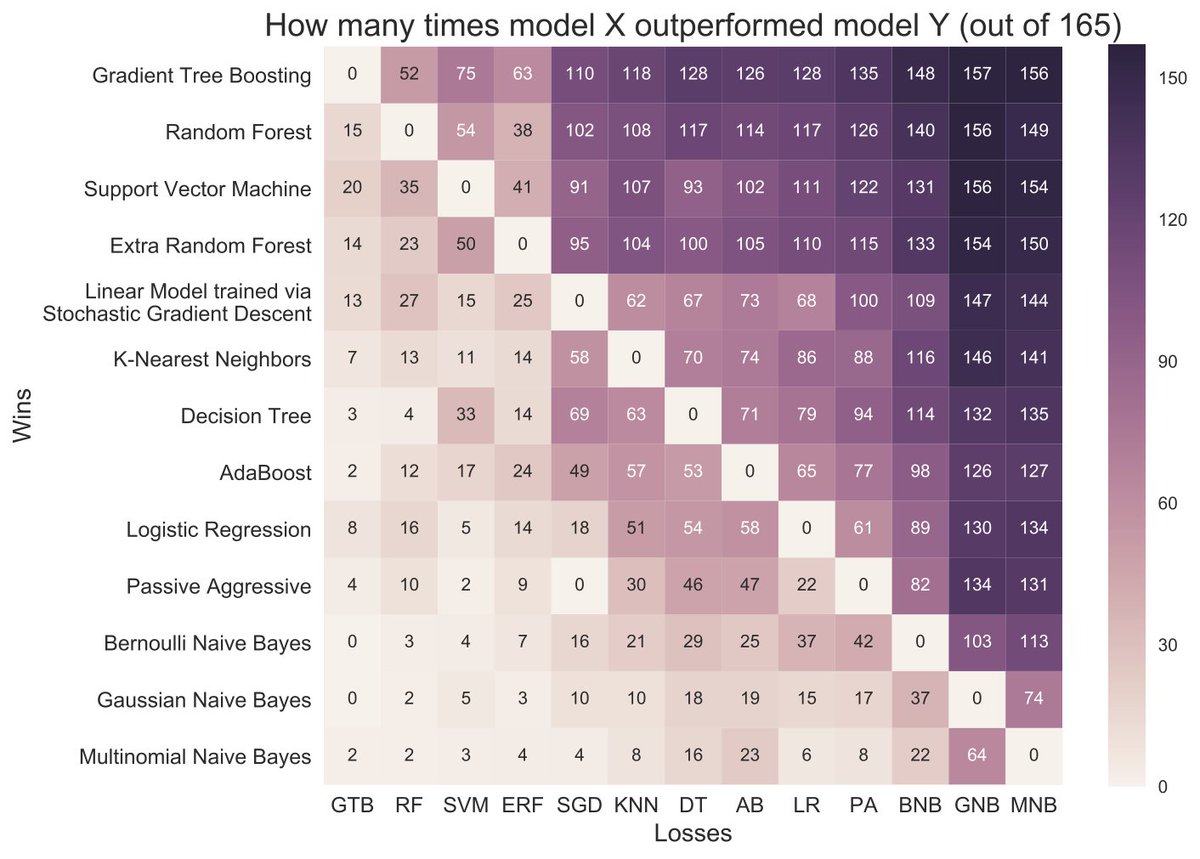
1
19
68
Finally read this excellent paper. It shows problems where grads are the same for different models, hence GD fails

0
15
67
One weird trick to scale your diffusion models to high resolution images: tune the noise schedule (and sprinkle in a bit of Google-level compute). High res diffusion without latent diffusion.

2
7
65
Stanford researchers announced new 500TB Medical ImageNet dataset at #gtc. The project webpage is already up:
0
33
63
#Neurips2022 is now over---here is what I found exciting this year. Interesting trends include creative ML, diffusion models, language models, LLMs + RL, and some interesting theoretical work on conformal prediction, optimization, and more.

1
4
65
First legitimate looking replication of the Meissner effect in LK-99. What a great day for science!

0
13
62
How can deep learning be useful in causal inference? . In our #NeurIPS2022 paper, we argue that causal effect estimation can benefit from large amounts of unstructured "dark" data (images, sensor data) that can be leveraged via deep generative models to account for confounders.

1
4
61
@NandoDF @ilyasut @icmlconf @iclr2019 Don't the benefits of increased reproducibility and rigor on the part of the authors greatly outweigh any potential misuses of their work, at least for the vast majority of ICML/ICLR papers? I think the current shift towards empirical work puts a greater need on releasing code.
4
1
57
Cool reddit thread on beautiful ML papers. but why are they all DL papers?? :) How about Wainwright and Jordan? Or the online learning stuff by Shalev-Schwartz? DL is awesome but, come on, that's not all there is to ML :) My vote goes to this paper:

This reddit thread on beautiful papers in machine learning is pretty great:
2
4
56
I thought the NIPS tutorial on deep learning on graphs was quite interesting. Uses spectral representations of graphs, which are really fascinating in themselves. Lots of potential scientific applications. I'd like to learn more about generative techniques.
1
11
58
Question to the panel—what are the open problems in diffusion generative models? Top answer—generalizing to discrete sequences and coming up with good corruption processes for that domain.

2
5
55
A paper describing the DenseNet idea in 1988. Another example of researchers (independently) reinventing an idea from the last AI summer.

Densenet from 1988. Found during skip connections lit review for my thesis, courtesy Faustino Gomez. Please cite if you use Densenets (1/2)

1
26
55
The ICLR paper decisions haven’t even been made yet, yet text-to-3d models are already been deployed into a commercial app by Luma. What a crazy year! Shootout to @poolio for the original work on DreamFusion.

✨ Introducing Imagine 3D: a new way to create 3D with text!.Our mission is to build the next generation of 3D and Imagine will be a big part of it. Today Imagine is in early access and as we improve we will bring it to everyone
1
4
54
It’s awesome to be back at @cornell_tech! Kicking off the fall semester with some stunning views of NYC.



2
1
52
My take on Wasserstein GANs: slower training, convergence metric works, not always more stable. TF/Keras code here:
1
13
54
As far as I can tell (and I might be wrong), Google Research was just renamed Google AI. What about all the work in systems, crypto, econ. ? It just seems wrong to call all of Google's CS research "AI".
5
9
48
This talk at the NIPS creative ML workshop was amazing. One of the best results on music generation with RNNs that I've seen so far.

1
9
51
Here are 9 predictions for AI in 2024 🎉🎊. 1️⃣ Planning will take a greater role in generative modeling. Models will increasingly “think” at inference time, trading off compute for output quality. In many applications (“generate a good molecule”), this will make a ton of sense.
4
7
50
This blew my mind. GAN-style models for identifying causal mutations in a GWAS with adjustment for population-based confounders.

Dave Blei and I are excited to share “Implicit causal models for genome-wide association studies”
0
12
46
Rally in support of Ukraine now in Times Square and for the next several hours. Another one starts at 2pm in Greenwich village. One show your support.

0
13
46
Earlier this month at #icml2019, we presented new work which examines the question of what uncertainties are needed in model-based RL. Taking inspiration from early work on scoring rules in statistics, we argue that uncertainties in RL must be *calibrated*. [1/10]

1
8
49



War in Ukraine, Day 2 (Feb 25). I will be summarizing key events of the day based on what I hear from friends on the ground and based on reports from western and Ukrainian media.

1
3
44
📢 One of my students, Phil Si, is applying for PhD programs in this cycle. Phil's ICLR paper on quantile flows is an exciting improvement over neural autoregressive flows, which makes them applicable to not just to density estimation, but also to generation. A short thread 🧵

1
6
41
After Google and Baidu, Facebook is also publishing a neural text-to-speech system. Like Deep Speech 3 (and Lyrebird's unpublished demo), it quickly generalizes to new speakers. This research area is really interesting.


0
14
45

Check out our new blog post on on finetuning LLMs quantized in 2-bits using Modulora. Unlike QLoRA, Modulora works with any modern quantizer like Quip# or OPTQ, and can outperform QLoRA on downstream tasks with 2x smaller models.
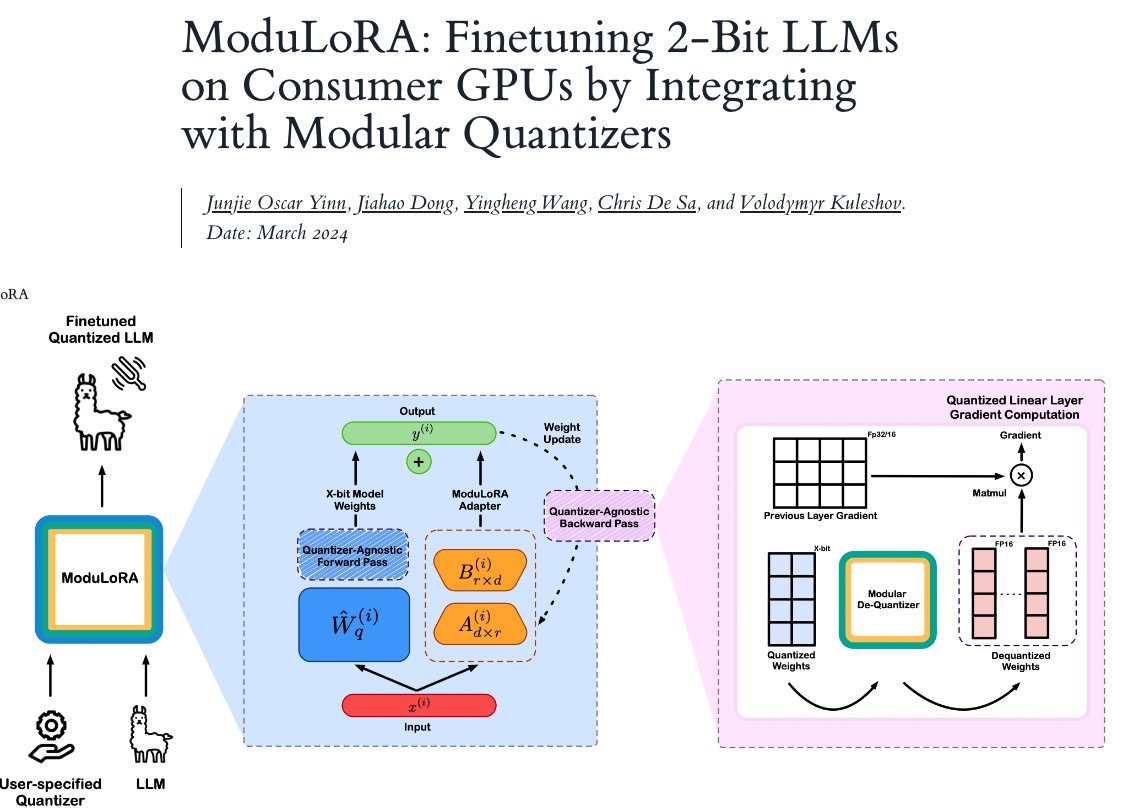
1
16
44
How far can you push LLM quantization without hurting performance on downstream tasks?. We could go pretty far by combining a state-of-the-art quantizer with Modulora finetuning. On some tasks, our carefully finetuned 2-bit LLMs outperform existing 8-bit LLMs. A short thread 👇

1
13
42
Explaining some of the behavior of deep neural nets using older results from the 90s developed for boosting, support vector machines, etc. Cool stuff:

1
5
37
And the new world record of information content per character in a tweet goes to. .

Some ways of combining information in two branch of a net A & B: 1) A+B, 2) A*B, 3) concat [A,B], 4) LSTM-style tanh(A) * sigmoid(B), 5) hypernetwork-style convolve A with weights w = f(B), 6) hypernetwork-style batch-norm A with \gamma, \beta = f(B), 7) A soft attend to B, . ?.
0
2
40

Diffusion models produce great samples, but they lack a semantically meaningful latent space like in a VAE or a GAN. We augment diffusion with low-dimensional latents that can be used for image manipulation, interpolation, controlled generation. #ICML2023.

Thrilled to share our latest paper - Infomax #Diffusion! We're pushing the boundaries of standard diffusion models by unsupervised learning of a concise, interpretable latent space. Enjoy fun latent space editing techniques just like GANs/VAEs! Details:

1
5
38
Watch the Mercury diffusion LLM in action 🧑💻. In this video, we vibe code a ViT in PyTorch using VS Code + Continue. The model nearly instantaneously generates big blocks of code based on user instructions.
3
8
38
If you’re at ICLR, you should try to catch Oscar (JHU undergrad), who is presenting his really cool TMLR paper on Modulora, 2bit finetuning of LLMs. Paper:

1
7
38



Did you know that word2vec was rejected at the first ICLR (when it was still a workshop)? Don’t get discouraged by the peer review process: the best ideas ultimately get the recognition they deserve.

Tomas Mikolov, the OG and inventor of word2vec, gives this thoughts on the test of time award, and the current state.of NLP, and chatGPT. 🍿

1
2
32
Excited to share that @afreshai raised another $12M to advance our mission of using AI to reduce waste across the food supply chain. We're always looking for talented folks who are passionate about AI, food, and the environment to join our growing team.
3
3
34
As the generative AI hackathon and post-hackathon events come to an end, I want to again thank everyone who attended! . Incredibly grateful to @davederiso @agihouse_org for organizing the event!. 🙏 to @LererHippeau & the NYC VC community for sponsoring it

2
6
34
Are Technica wrote a short piece about our Mercury diffusion language models
2
4
35


Wow, "Understanding deep learning requires rethinking generalization" got perfect 10.0 reviews at ICLR (best score)!
1
10
33