

Jean de Nyandwi
@Jeande_d
Followers
46K
Following
48K
Media
1K
Statuses
6K
Researcher @LTIatCMU • Multimodal NLP, Post-training, Data, Evals • CMU MS 24. Blog: https://t.co/1BEFLZAqe7 ML: https://t.co/7PkTyDvuri
Planet Earth
Joined March 2017
A NEW ARTICLE 🔥🔥 The first article of Deep Learning Revision Research Blog(introduced recently) is out: "The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture". In the article, we discuss the core mechanics of transformer neural
18
181
674
Great lectures on deep generative modelling, covering a whole bunch of topics, model families, and learning algorithms in generative models space. And applications in vision and natural language processing, and reinforcement learning.
1
1
14
Deep Generative Models Lectures: videos, slides, notes, papers https://t.co/Ssvh86lIze
kuleshov-group.github.io
The site for the Open Deep Generative Models course.
0
0
2
Great lectures on deep generative modelling, covering a whole bunch of topics, model families, and learning algorithms in generative models space. And applications in vision and natural language processing, and reinforcement learning.
1
1
14


Your VLMs/VLAs have hidden potential. Sparse Attention Vectors (SAVs) unlocks few-shot, mechanistically interpretable test-time adaptation—beating LoRA with ~20 heads. 🚀 See you today #ICCV2025 🌺 📍Poster #254 (10/21, Session 1) @berkeley_ai @CMU_Robotics @MITIBMLab Links:
1
2
19

Claude Skills shows performance benefits from leveraging LLM skill catalogs at inference time. Our previous work (linked under thread 5/5) showed the same 6 months ago! 🌟Our new work, STAT, shows that leveraging skills during training can greatly help too‼️, e.g., Qwen can
8
37
187
Applied Machine Learning - Cornell CS5785 "Starting from the very basics, covering all of the most important ML algorithms and how to apply them in practice. Executable Jupyter notebooks (and as slides)". 80 videos. All publicly available.
1
3
14
[New course] Transformers & Large Language Models, CME 295 Stanford Yet another excellent course on transformers and large language models with a consolidated curriculum starting right away from transformers. Topics/lectures: - Intro to transformers - Transformer-based models &
2
2
19
Exactly the same 2 courses I thought seeing the post. There are more across other schools, look at: - advanced NLP at CMU( https://t.co/jvyGAeBvAb) - new inference class of its kind in academia CMU ( https://t.co/kQOfe4s7jw) - LLM systems CMU( https://t.co/dfrfS2ywdB) - large

your honor i object, i dont know about harvard but stanford literally releases SOTA courses
0
9
67
When Karpathy drops a nano repo, X timeline is great again! Everyone is basically happy.

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,
0
0
1
Statistics 110: Probability - Harvard Inarguably, one of the classic/world's best probability courses on the web!!
0
2
18

An excellent technical guide on LLM post-raining covering SFT(supervised finetuning), RL rewards such as RLHF/human preferences, RLAIF/constitutional-AI, RLVR/verifiable outcomes, process-supervised and rubric rewards. Also covers common RL training algorithms from PPO, GRPO, and
2
1
19
Deep learning course by legendary Andrew Ng is public now. New 2025 lectures are out!!
0
0
5
Thanks for writing this piece @johnschulman2. Very insightful and lots of practical findings. https://t.co/fwutv1Tfbj
thinkingmachines.ai
How LoRA matches full training performance more broadly than expected.
0
0
1
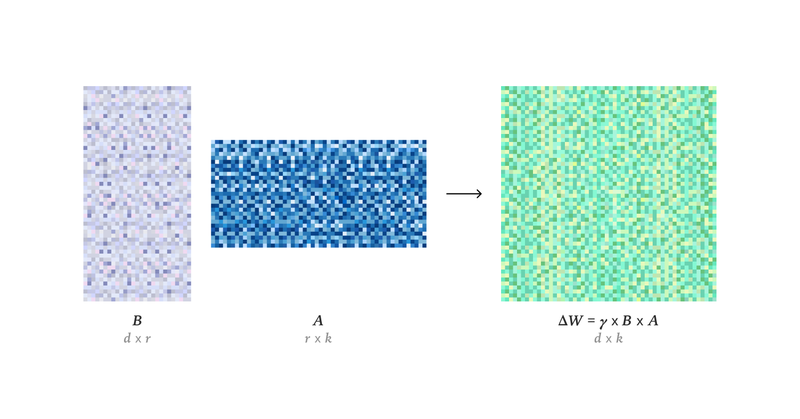
LoRA Without Regret - Recent Blog from Thinking Machines TL/DR: LoRA actually matches full supervised fine-tuning(SFT) when you get the details right. Nearly same sample efficiency, loss(or better), same final performance. Some plain points: - Apply LoRA to ALL layers,
1
0
10
Thanks for using the visual, @ColdFusion_TV. I am a big fan of your tech videos. The amount of work you put into research shows in the videos.
0
0
3