
Dustin Tran
@dustinvtran
Followers
42K
Following
4K
Media
201
Statuses
3K
Research Scientist at Google DeepMind. I lead evaluation at Gemini / Bard.
Joined June 2013
For those keeping track

2023 has already seen more advances in AI than any other year. This velocity will only increase.
24
273
1K
My favorite oxymoron in machine learning: "empirically proven".
28
71
819
I'm so appreciative that ML is at a state where open-source code, freely available conference videos/proceedings, and now even open reviews are becoming the norm. That's not a luxury all research fields have.
12
64
766
"Simple, Distributed, and Accelerated Probabilistic Programming". The #NIPS2018 paper for Edward2. Scaling probabilistic programs to 512 TPUv2 cores and 100+ million parameter models.

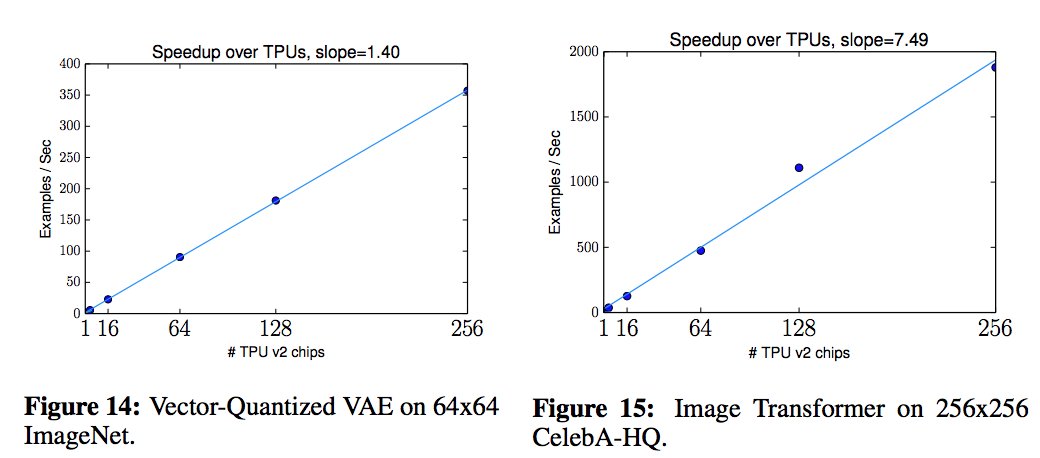
8
208
724
Videos are now available for the 2017 Deep Learning (and RL) Summer Schools in Montreal
2
291
677
Recap of the trendiest conversation topic at NeurIPS in the past 7 years. 2015: Bayes / RL / OpenAI.2016: Deep RL & Autoregressive generative models.2017: "DL is alchemy".2018: Glow & Neural ODEs.2019: Understanding DL.2020: GPT-3.2021: people had conversations. ?.2022: ChatGPT.
9
57
564
Starting today, I am at Google full-time as a Research Scientist. See everyone in the Bay Area!.
33
11
556
Speaking of interesting facts from analyzing conferences: Google is 3-10x the size of any other AI research lab. That's not even including DeepMind which ranks 3rd.
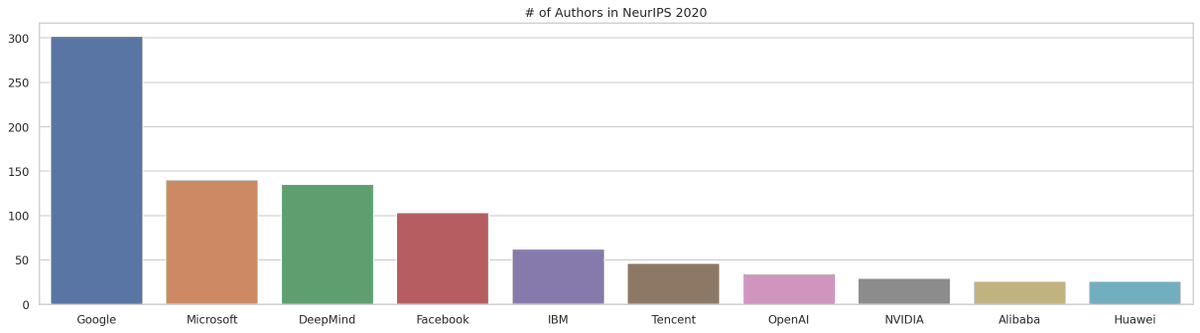
16
89
528
What gripes do you have with LaTeX's default, and what you always add to papers? Here are mine: 1. Cleveref. Don't use "Section \ref{sec:intro}". Use \Cref{sec:intro}. This makes writing less error prone and it makes "Section" part of the hyperlink!
5
93
517
Excited to introduce TensorFlow Probability. Official tools for probabilistic reasoning and statistical analysis in the TF ecosystem.

Introducing TensorFlow Probability: empowering ML researchers and practitioners to build sophisticated models quickly, leveraging state-of-the-art hardware . Read about it on the TensorFlow blog ↓.
6
154
454
It’s surprising that in 2022, there remains little movement away from LaTeX toward a new language. It has some of the most unintuitive designs and syntax you’d expect in a language today.
53
23
433

Excited to release rank-1 Bayesian neural nets, achieving new SOTA on uncertainty & robustness across ImageNet, CIFAR-10/100, and MIMIC. We do extensive ablations to disentangle BNN choices.@dusenberrymw @Ghassen_ML @JasperSnoek @kat_heller @balajiln et al


3
88
406
I got into the field by watching The MLSS videos are all excellent (my favorite is Cambridge 2009 . For a deeper dive, you should dive into textbooks. I recommend Bayesian Data Analysis and ML: A Probabilistic Perspective.
6
67
410
0 papers at NeurIPS and suddenly 12 publications at NeurIPS 2021🤔This may be the most pervasive cheating scandal I've seen in academia.

machine learning researchers learn to optimise their own best paper rate through collusion and other unregulated mechanisms.
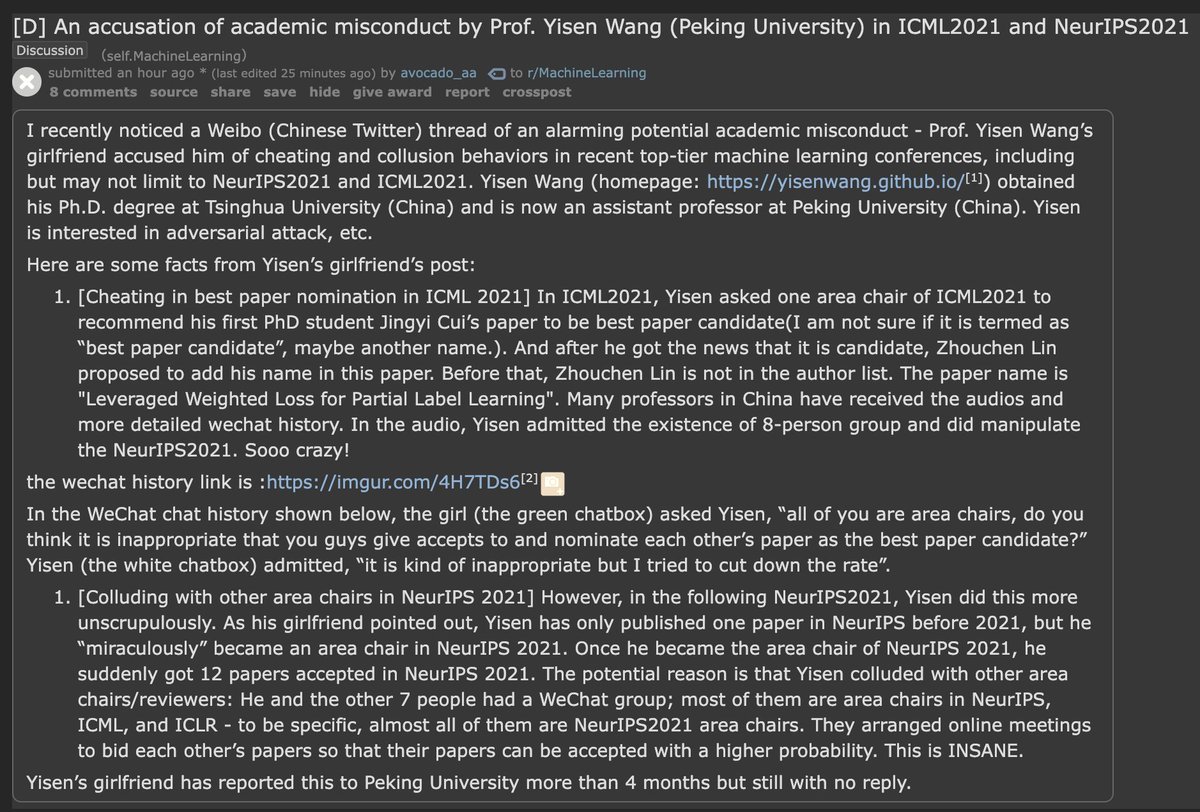
15
50
395
Interesting in quickly experimenting with BNNs, GPs, and flows? Check out Bayesian Layers, a simple layer API for designing and scaling up architectures. #NeurIPS2018 Bayesian Deep Learning, Happening now.

11
99
396
Syllabus for my qualifying exam. It involves 29 papers representing the state of the art in Bayesian deep learning
13
105
404
Excited to be at Google for rest of this year. Aside from basic ML research, expect Edward officially merging into @tensorflow (contrib).
12
64
394
Just an appreciation tweet for the normalization of arXiv and freely available conference papers in CS. I'm trying to read science papers in Cog Sci and Psychology, and it's a nightmare to access.
12
19
384
Tomorrow @latentjasper @balajiln and I present a #NeurIPS2020 tutorial on "Practical Uncertainty Estimation and Out-of-Distribution Robustness in Deep Learning". Whether you're new to the area or an expert, there is critically useful info! 8-10:30a PT
8
48
365
In our work "Plex", we propose a framework for reliability in AI. We also introduce new models (ViT-Plex & T5-Plex) for reliable decision-making across a broad array of scenarios. Blog: Paper: Code:
10
71
362
It's 2021, and we're still debugging functions by manually checking Tensor/np.ndarray shapes. Why aren't type systems for array dimensions a common standard yet?.
21
18
333
I'm awarded a Google PhD fellowship in Machine Learning, for work in Bayesian deep learning. Thanks @googleresearch!
21
25
328

Rajesh Ranganath, Dave Blei and I released "Deep and Hierarchical Implicit Models" on arXiv


2
132
313


Wow, they finally did it. You can now render LaTeX equations in Markdown. all with MathJax under the hood
5
45
298
One thing I find fascinating is that Parti is another data point suggesting that the key to large models is not diffusion, GANs, contrastive training, autoregressivity, or other more complex methods. What matters most is scale.

"A photo of the back of a wombat wearing a backpack and holding a walking stick. It is next to a waterfall and is staring at a distant mountain." #parti.

9
23
298
How do we specify priors for Bayesian neural networks? Check out our work on Noise Contrastive Priors at the ICML Deep Generative Models workshop 11:40am+. @danijarh, @alexirpan, Timothy Lillicrap, James Davidson

4
78
286
"A Research to Engineering Workflow". An outline of how I personally learn and do basic research.
3
78
282
Excited to be joining @OpenAI today. (I am on leave from Columbia for the rest of this year.) also: shout out to those in the Bay Area!.
19
13
281
Snippet 1 from the #NeurIPS2020 tutorial: @balajiln What do we mean by uncertainty and out-of-distribution robustness?


3
68
276
Talks for the Probabilistic Programming conference #PROBPROG2018 are now available! Includes, e.g., Zoubin Ghahramani @djsyclik Dave Blei @roydanroy @tom_rainforth @migorinova Stuart Russell, Josh Tenenbaum, and many others.
1
78
272
Yann is wrong that the issue is in autoregressive generation. In fact, you can make an autoregressive model generate a full sequence and refine through inverse CDF-like tricks. The result is exactly the same. 1/3.

I have claimed that Auto-Regressive LLMs are exponentially diverging diffusion processes. Here is the argument:.Let e be the probability that any generated token exits the tree of "correct" answers. Then the probability that an answer of length n is correct is (1-e)^n.1/

11
23
262
Highly recommend this augmentation, infrastructure, and human-centric perspective on "AI" by Mike Jordan

6
68
254
Official Bard announcement! Team has been hard at work (myself humbly included). Excited to release and share more details soon.

1/ In 2021, we shared next-gen language + conversation capabilities powered by our Language Model for Dialogue Applications (LaMDA). Coming soon: Bard, a new experimental conversational #GoogleAI service powered by LaMDA.
12
8
248
Check out Discrete Flows, a simple way to build flexible discrete disctributions. @keyonV @kumarkagrawal @poolio @laurent_dinh Our poster's at the Generative Models for Structured Data workshop! Room R02, today 3:15p #iclr2019

2
46
244
PyMC4 announces to base on @TensorFlow and TensorFlow Probability. This is exciting news for consolidating open source efforts for machine learning!

Big announcement on #PyMC4 (it will be based on #TensorFlow probability) as well as #PyMC3 (we will take over #Theano maintenance)
1
67
233
I'm against GPT-4chan's unrestricted deployment. However, a condemnation letter against a single independent researcher smells of unnecessary pitchfork behavior. Surely there are more civil and actionable approaches. I'd love to hear what steps were taken leading up to this.

There are legitimate and scientifically valuable reasons to train a language model on toxic text, but the deployment of GPT-4chan lacks them. AI researchers: please look at this statement and see what you think:
15
9
228
With all the new ML frameworks lately and the short lifespan of old ones, I sometimes wonder if we'd all better if we had just stuck with Theano.
15
15
217
“Deep Probabilistic Programming” now on arXiv. Foundations of with deep learning apps
3
107
223
"The shift from AI being a research domain to it increasingly becoming a research + engineering domain, is a strong signal that we're not in a bubble this time." +100. Systems research advances science and is immediately useful :)
3
68
211
TensorFlow Distributions. For researchers: learn about all its features, PPL: learn how DL apps leads to new designs




1
71
201
There are three types of researchers: 1. those that only look at the paper's methods and ideas; 2. those that only look at experiments; and 3. those that no longer read papers.
7
10
199
"Bayesian Layers: A Module for Neural Network Uncertainty" on arXiv: With @dusenberrymw, @markvanderwilk, @danijarh.
Interesting in quickly experimenting with BNNs, GPs, and flows? Check out Bayesian Layers, a simple layer API for designing and scaling up architectures. #NeurIPS2018 Bayesian Deep Learning, Happening now.
2
61
207
I love how LaTeX font size names are so arbitrary. small, normalsize, large, Large, LARGE.
13
4
196
See the arXiv version at It includes character-level results (1.38 bpc on PTB; 1.23 bpc on text8) with a RealNVP-like flow model that's 100-1000x faster at generation than state-of-the-art autoregressive baselines.
Check out Discrete Flows, a simple way to build flexible discrete disctributions. @keyonV @kumarkagrawal @poolio @laurent_dinh Our poster's at the Generative Models for Structured Data workshop! Room R02, today 3:15p #iclr2019
4
60
194
Thanks for the opportunity to give a tutorial on "Practical Uncertainty Estimation and Out-of-Distribution Robustness in Deep Learning"! With @latentjasper and @balajiln. Look forward to it. :-).

Thanks to everyone who submitted tutorial proposals for this year's @NeurIPSConf. It was amazing to see all the great work that went in to putting together these proposals. We are happy to announce this year's tutorials at #neurips2020
3
16
193
Dave Blei and I are excited to share “Implicit causal models for genome-wide association studies”
8
61
189
Presenting "Why Aren't You Using Probabilistic Programming?" tomorrow. 8:05-8:30 at Hall C #NIPS2017

5
44
190
Every time I use matplotlib, I'm confused whether to use set_xticks, set_xticks_labels, or xticks. Why pyplot and the object-oriented API are inconsistent, and why matplotlib even supports two ways to do the same thing, is beyond me.
17
2
186
"Google and Others Are Building AI Systems That Doubt Themselves" by @willknight Edward, Pyro, and prob programming
6
70
182
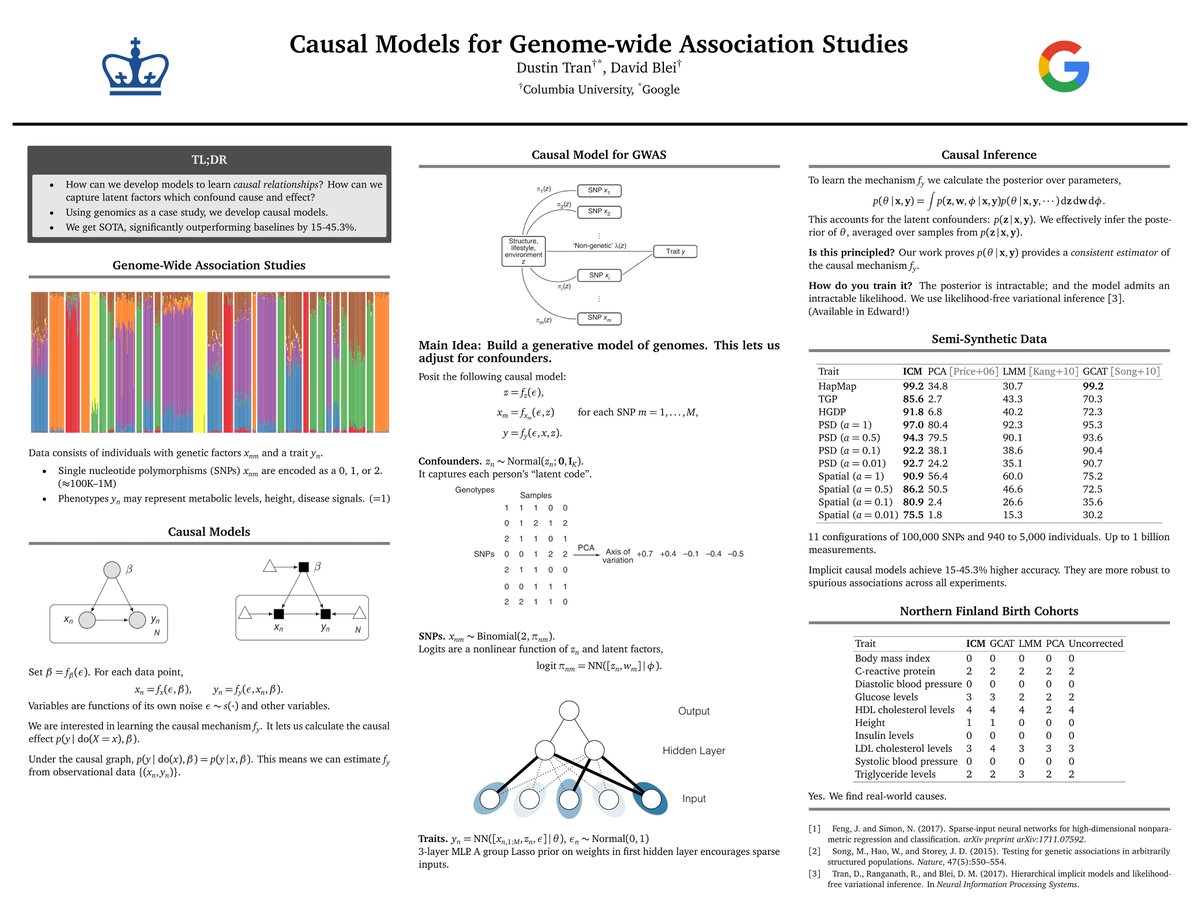
Interesting to observe that over the years, the cost and people involved to make AI research papers is probably closer to that of a film production than a novel.
6
12
181
TensorFlow v1.3.0, including first official release of the `tf.distributions` library
6
62
184
was recomm. to me by @ChrLouizos. It explains generalization _very_ well from persp. of information & probability.
0
54
179
Great response to "Why Probability Theory Should be Thrown Under the Bus"by @tdietterich (can read indep of article)
4
50
174
Not so controversial take: I don’t think anyone seriously believes doing exact Bayes on a network tuned for SGD and not tuning the prior (or likelihood) will be actually lead to better predictive results.
4
25
168
Check out the @Entropy_MDPI Special Issue on Probabilistic Methods for Deep Learning. w/ @eric_nalisnick. Submission deadline: October 1. It's a timely venue if you're looking to publish, say, a summer research project or a previous conference submission.
2
23
166
Theano stops development. Thanks for all the amazing, innovative work!
0
100
165
Spicy take against their take: This is the classic resistance whenever there's a paradigm shift in the field. The air in the room is the same as in 2013-14 when deep learning was on the rise.
'I don't really trust papers out of "Top Labs" anymore' .
9
6
170
Reviewers have fragile egos. Successful rebuttals are not only about who’s right but also about diplomacy.
6
5
164
"Theoretical Impediments to Machine Learning With Seven Sparks from the Causal Revolution" by Judea Pearl
3
71
162

Why probabilistic generative models? A great, concise description. (Found by stalking @DavidDuvenaud's courses. :)

2
81
155
Come check out our poster on "Deep Probabilistic Programming" today at 10:30-12:30p, C3. #ICLR2017

2
42
154
Thanks @lawrennd for inviting me to GPSS! My slides on "Probabilistic Programming with GPs":




3
36
148
The Chambers Statistical Software Award at #JSM2018 was graciously given to Edward. Check out the talk on Monday (10:30am). Will also be at the evening mixer—reach out if you're around!
9
18
151
Yordan Zaykov at #PROBPROG: "is now open-source." That's incredible news for the probabilistic programming community!
1
51
144
Finally had time to watch this insightful talk on "AI impact on jobs" by Michael Osborne. Highly recommend it.
3
28
143
Tutorial on “Deep Probabilistic Programming: TensorFlow Distributions and Edward” w/ Rif Saurous, 2pm #POPL2018
2
35
141


“The Algorithms Behind Probabilistic Programming.” Great description of Bayesian inf, NUTS, ADVI by @FastForwardLabs
1
65
138
Check out our work analyzing (non)autoregressive models for NMT! Nonautoregressive latent variable models can achieve higher likelihood (lower perplexity) than autoregressive models.

“On the Discrepancy between Density Estimation and Sequence Generation”. Seq2seq models are optimized w.r.t log-likelihood. We investigate the correlation btw. LL and generation quality on machine translation. w/ @dustinvtran, @orf_bnw, @kchonyc. (1/n).
2
17
133
Check out our Hyperparameter Ensembles, #NeurIPS2020 camera-ready at Hyper-deep ensembles expand on random init diversity by integrating over a larger space of hparams. Hyper-batch ensembles expand on efficient methods. @flwenz @RJenatton @latentjasper


4
29
136
I agree with this post about the TensorFlow user experience. Here's my response regarding the unfortunate lack of success in specifically getting Bayesian neural networks to work.
5
10
130
Our ADVI journal paper has been published. Available in Stan and PyMC3; partially in Edward and WebPPL.


0
39
121
@AlexGDimakis I actually argue one of deep learning's biggest flaws is the lack of modularity. Imagine a system where changing one component affects every other component. This is "end-to-end learning": an engineering nightmare of leaky abstractions that we're somehow OK with in modern ML.
7
9
116
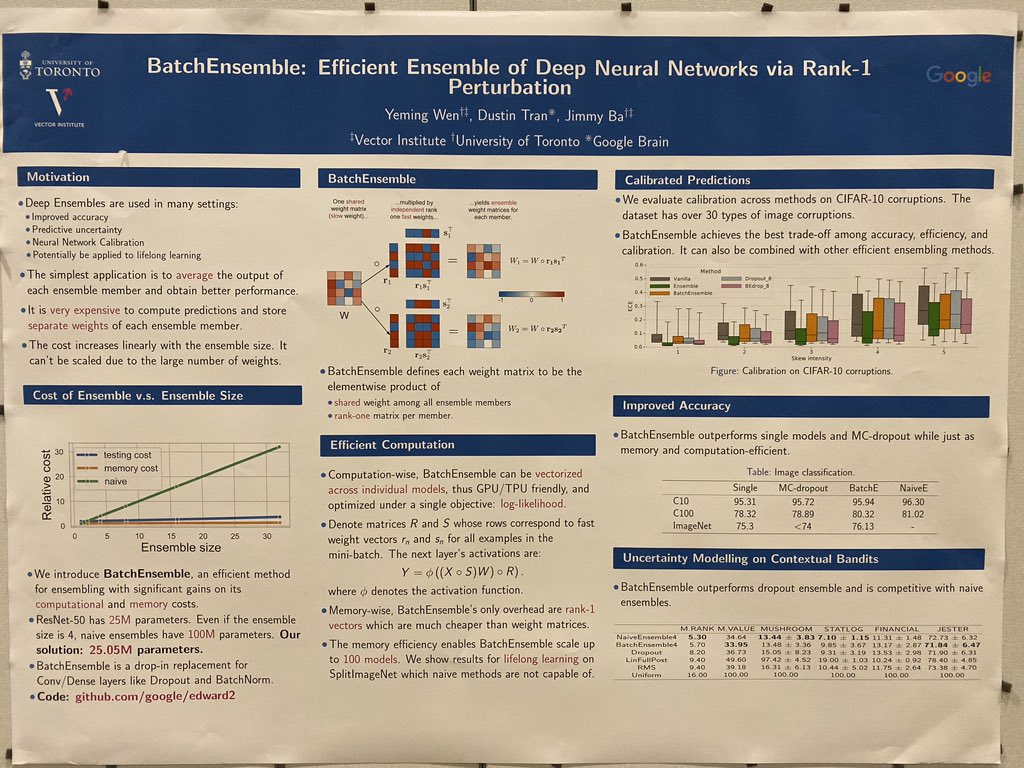
We released the ICLR paper! BatchEnsemble includes SOTA on efficient lifelong learning across splitCIFAR and splitImageNet, improved accuracy+uncertainty across CIFAR and contextual bandits, WMT, and diversity analysis. Lead by Yeming Wen and w/ Jimmy Ba.
Check out BatchEnsemble: Efficient Ensembling with Rank 1 Perturbations at the #NeurIPS2019 Bayesian DL workshop. Better accuracies and uncertainty than dropout and competitive with ensembles across a wide range of tasks. 1/-
4
23
123
Excellent recorded talks from Cognitive Computional Neuroscience 2017. (thanks @skrish_13 for pointing me to it)
2
27
119
The team says hi again.

Woah, huge news again from Chatbot Arena🔥. @GoogleDeepMind’s just released Gemini (Exp 1121) is back stronger (+20 points), tied #1🏅Overall with the latest GPT-4o-1120 in Arena!. Ranking gains since Gemini-Exp-1114:. - Overall #3 → #1.- Overall (StyleCtrl): #5 -> #2.- Hard

8
4
123
A key idea for merging probabilistic programming with deep learning: Conditional independence from Vikash Mansinghka #NIPS2017 tutorial

2
20
116
My comments on "Zhusuan: A Library for Bayesian Deep Learning"
2
31
120
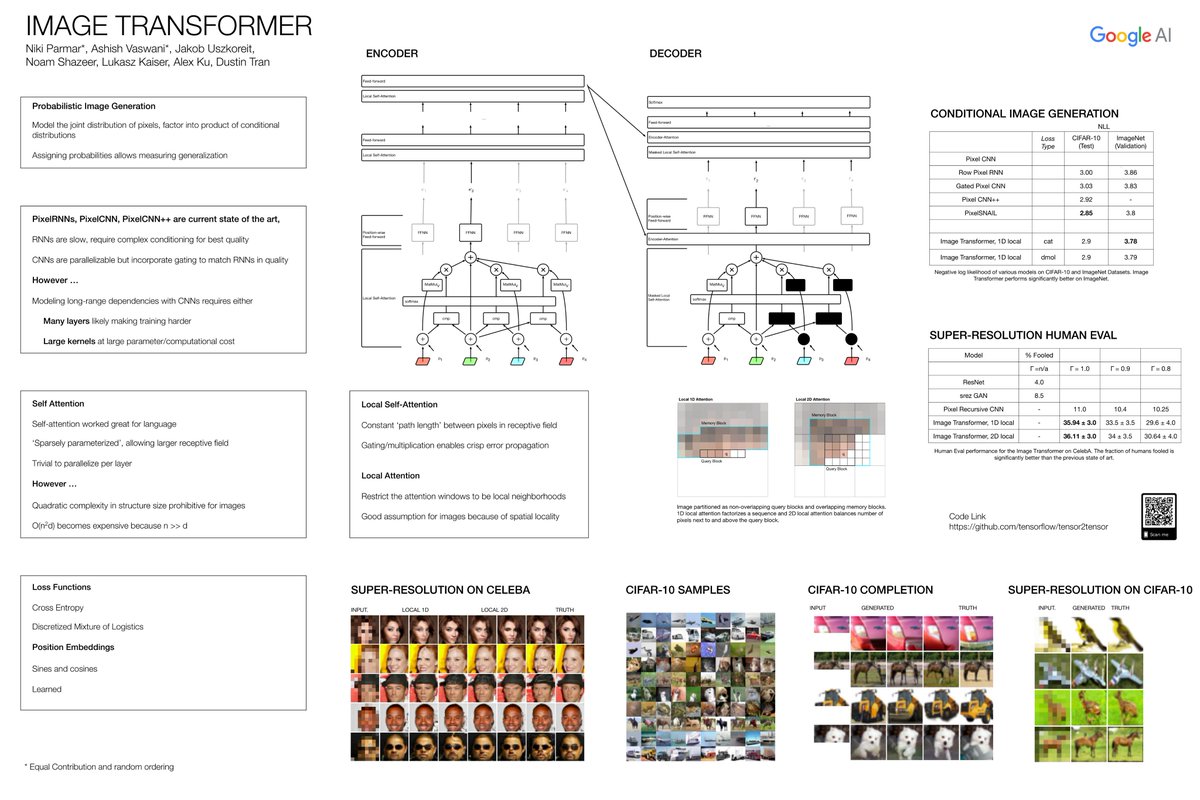
Check out the Image Transformer by @nikiparmar09 @ashVaswani others and me. Talk at 3:20p @ Victoria (Deep Learning). Visit our poster at 6:15-9:00p @ Hall B #217!
0
31
119
Interesting work from UberAI labs. Probabilistic programming in PyTorch led by Noah Goodman, Eli Bingham, and others.

Like Bayesian Inference and #pytorch? Try our PPL, Pyro.
3
35
118
I think the more we learn about neural nets, the more statements such as "uninterpretable", "data inefficient", or "noncausal" are wrong.
7
27
116
TensorFlow Dataset API (. A cleaner and streamlined input pipeline
0
37
116
Interesting paper. "Variational Gaussian Dropout is not Bayesian" by Jiri Hron, @alexggmatthews, Zoubin Ghahramani
4
31
112
Recorded talks & panels are available for the NIPS 2016 Workshop on Advances in Approximate Bayesian Inference
2
45
113
Presenting "Why Aren't You Using Probabilistic Programming?" tomorrow. 8:05-8:30 at Hall C #NIPS2017
0
33
116
Highly recommend Emti's "Deep Learning with Bayesian Principles" tutorial. Emti has some unique perspectives on Bayesian analysis from optimization to structured inference.

Excited for the tutorial tomorrow (Dec 9) at 9am at #NeurIPS2019 If you are at the conference and would to chat, please send me an email (also, if you are interested in a post-doc position in our group at Tokyo).
2
14
115
An excellent intro to normalizing flows by @ericjang11—for density estimation, variational inference, and RL.

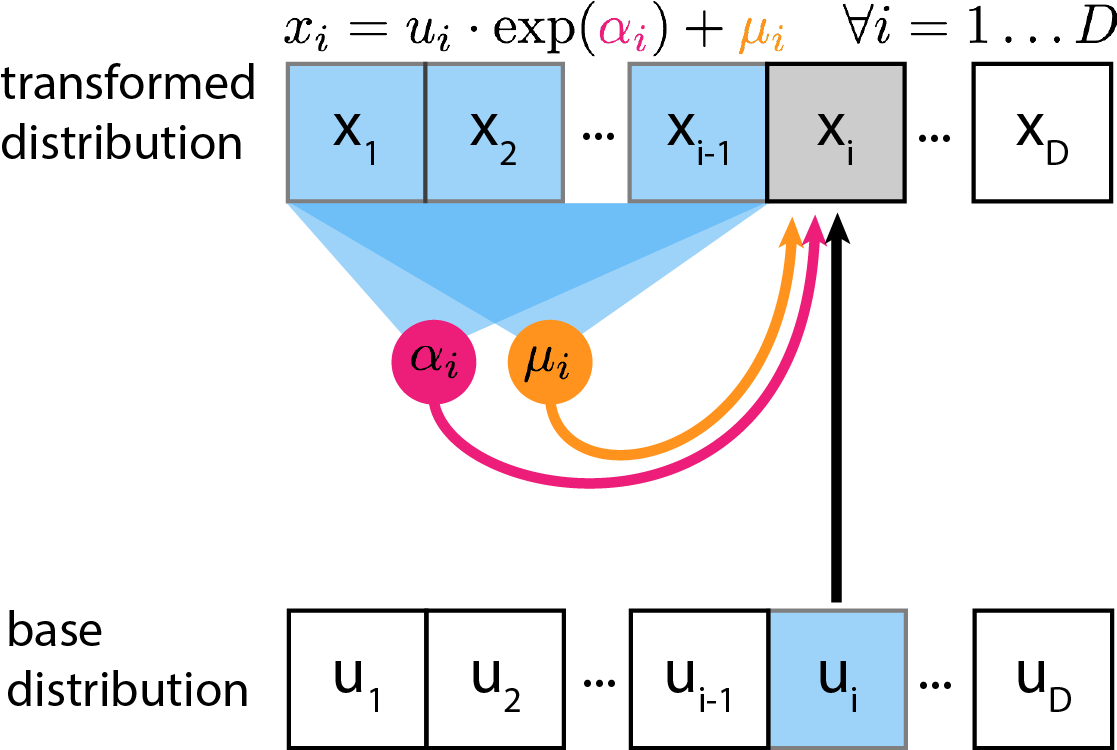
I finally learned what a determinant was and wrote a blog post on it. Check out this 2-part tutorial on Normalizing Flows! .
0
23
111
"Formulating [RL] as inference provides a number of other appealing tools: a natural exploration strategy based on entropy maximization, effective tools for inverse reinforcement learning, and the ability to deploy powerful approximate inference algorithms to solve RL problems."

If you want to know how probabilistic inference can be tied to optimal control, I just put up a new tutorial on control as inference: This expands on the control as inference lecture in my class:
0
17
110

#NIPS2016 tutorial for Variational Inference slides now online! by dave blei, @shakir_za, rajesh ranganath
1
54
111
Gemini is #1 overall on both text and vision arena, and Gemini is #1 on a staggering total of 20 out of 22 leaderboard categories. It's been a journey attaining such a powerful posttrained model. Proud to have co-lead the team!.
Exciting News from Chatbot Arena!. @GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes. For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive

10
8
112