
Steph Cabral
@stephcabral_
Followers
225
Following
568
Media
5
Statuses
69
PCCM Fellow @HarvardPulm | @BIDMC_IM
Boston, MA
Joined October 2020
Excited to share our work evaluating an LLM (GPT-4) vs. physicians at clinical reasoning across four stages of data acquisition. Who do you think was superior? Many thanks to my awesome co-authors @AdamRodmanMD @DrDanRestrepo @zahirkanjee @philipvvilson @BageLeMage @byrondcrowe

How good is #AI at clinical reasoning? An early, simulated assessment https://t.co/5fXdgwBXRJ “An LLM was better than physicians in processing medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”
5
6
48
Exciting updates!! (1) I just opened my lab at Boston Children’s Hospital (Harvard-affiliated) (2) I’m hiring a postdoc focused on integrating GWAS and functional genomic data. Reach out if you’re interested or connect at ASHG next week! (3) Learn more at
3
37
234
My husband is starting his lab in statistical genetics at @Bos_CHIP this fall! Very proud of him—reach out if you’re looking to join his group (I can attest he’s great!)

I'm excited to share I'll be starting a faculty position at Boston Children's Hospital in the Computational Health Informatics Program (@Bos_CHIP ) this October!!
0
0
4
There is a lot of buzz about our new paper in Nature Medicine on the effects of LLMs (GPT-4) on physician management reasoning! I had TONS of fun working on this -- but what it MEANS requires some unpacking. A 🧵⬇️ https://t.co/yLZJw1U5IE
A randomized trial of GPT-4 vs 92 physicians with or without this #AI LLM for performance on patient care tasks. AI improved physician performance, on par with AI alone (based on 5 clinical vignettes) https://t.co/c7b82kQLi8
@NatureMedicine @AdamRodmanMD @jonc101x
8
94
282
Excited to kick off 2025 with our latest publication! We've developed TGFM, a new statistical method for identifying the causal tissue and gene underlying GWAS disease loci—providing new insights into the biology behind GWAS signals. https://t.co/Qx5WLtMmjc
2
19
63

We're so proud to congratulate our senior residents on graduation! They have been a truly outstanding class and it has been an honor to watch them care for patients. As you head to fellowships or faculty roles near and far, we can't wait to see your bright futures unfold! 🌟🎓🩺
1
13
57
Thanks @Anacapa17 and @jonc101x for the fantastic talks on machine learning and LLMs in medicine! Lots of great discussion but more importantly some wild magic 🪄🪄🪄 (@jonc101x is a magician if you can believe it)

We are INCREDIBLY excited to host (real magician) @jonc101x and @BIDMC_IM alum @Anacapa17 to talk about their research in AI in medicine. Anyone at @BIDMC_IM is welcome -- Deac 312/315 at 6 PM! (not on Zoom -- in person only!)
1
0
12
Our new study in @JAMAInternalMed looking at the reasoning abilities of GPT-4 compared with human physicians just came out. Big picture: AI displays (much) better reasoning than humans, makes diagnoses similarly, but hallucinates considerably more. A 🧵to put in context ⬇️
How good is #AI at clinical reasoning? An early, simulated assessment https://t.co/5fXdgwBXRJ “An LLM was better than physicians in processing medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”
8
76
242

An LLM outperformed human clinicians in the ability to process medical data and display clinical reasoning, raising hopes that LLMs might be able to serve as “copilots” in clinical workflows.
2
5
9

We know LLMs can ace multiple-choice exams. Taking us deeper, an important new study led by @stephcabral_ and @AdamRodmanMD conducts a nuanced evaluation of the clinical reasoning abilities of GPT-4 wrt physicians. Guess who wins? Need more of these!

jamanetwork.com
This cross-sectional study assesses the ability of a large language model to process medical data and display clinical reasoning compared with the ability of attending physicians and residents.
1
11
21
Anxiously awaiting future #AI research that will assess the efficacy of LLMs working with physicians in actual clinical practice! @AdamRodmanMD @arjunmanrai @jonc101x @EricTopol @DrEricStrong
1
0
5
GPT-4, however, had more instances of “incorrect” reasoning in its responses. (For example, it included “ectopic pregnancy” in the ddx of a 71 yr old with abdominal pain). Hence, our need for multifaceted evaluations of LLMs preceding their integration into the clinical workflow.
1
0
1
We found that GPT-4 was superior to both residents and attendings at clinical reasoning using the R-IDEA score. Many other reasoning outcomes were similar — diagnostic accuracy and cannot-miss diagnoses.
1
0
0
We gave clinical encounter data to 21 attendings & 18 residents from 2 hospitals, as well as GPT-4, and asked them to clinically reason and provide their ddx throughout the case. We scored responses using the R-IDEA score, a validated clinical reasoning assessment tool. @vschaye
1
0
0

It is remarkable how routine it has become for careful studies to show that GPT-4 (not trained specifically for medicine) outperforms most doctors in key aspects of diagnosis. That doesn't mean that GPT-4 is reliable in all circumstances, but it still seems like a big deal.
How good is #AI at clinical reasoning? An early, simulated assessment https://t.co/5fXdgwBXRJ “An LLM was better than physicians in processing medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”
10
85
394
How good is #AI at clinical reasoning? An early, simulated assessment https://t.co/5fXdgwBXRJ “An LLM was better than physicians in processing medical data and clinical reasoning using recognizable frameworks as measured by R-IDEA”
3
103
326

On pulm consults with @HarvardPulm @BIDMC_IM, and consulted on a case of platypnea that is still escaping us. In the spirit of a @StaciSaundersMD intern report today on effective med-ed, here's my general approach to the condition and attempt at an infographic! #MedTwitter
3
56
196

🖥️We wrapped up our first Academic Half Day on AI in Medicine! Thanks to all our speakers! We learned more about tools like #GPT-4 and Open Evidence, especially in research and clinical application. We also discussed ethical & future policy implications. #Bioethics #AI #MedEd
0
3
13
SURGE (our unsupervised method to discover context-specific eQTLs without requiring pre-specification of the contexts of interest) is now out in Genome Biology!
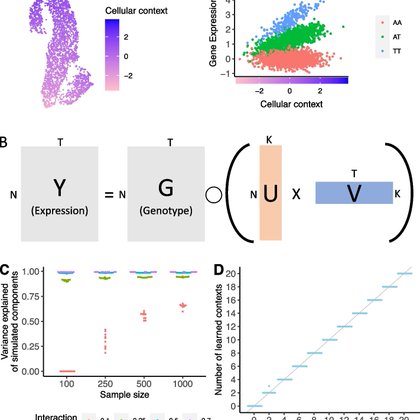
genomebiology.biomedcentral.com
Genetic regulation of gene expression is a complex process, with genetic effects known to vary across cellular contexts such as cell types and environmental conditions. We developed SURGE, a method...
1
16
61