
Shengjia Zhao
@shengjia_zhao
Followers
14K
Following
394
Media
14
Statuses
297
Research Scientist @ OpenAI. Formerly PhD @ Stanford. I like training models. All opinions my own.
Joined November 2016
Excited to bring o1-mini to the world with @ren_hongyu @_kevinlu @Eric_Wallace_ and many others. A cheap model that can achieve 70% AIME and 1650 elo on codeforces.
65
143
1K
Excited to train o3-mini with @ren_hongyu @_kevinlu and others, a blindingly fast model with amazing reasoning / code / math performance.

11
44
423
We are also hiring top researchers/engineers to keep breaking the data wall and find out ways to pretrain both frontier models & extremely cost/performance efficient models. If you are interested in working on this, apply & drop me an email.
Excited to train o3-mini with @ren_hongyu @_kevinlu and others, a blindingly fast model with amazing reasoning / code / math performance.
16
32
407
We must be living in a simulation that glitched. The madness is unbelievable.
23
5
305
Found this amazing and comprehensive summary of variance reduction methods (chapter 8,9,10). Also happy to share the cheetsheet I made comparing several major methods (not guaranteed correct).

5
86
319
It's amazing what a small team with limited GPUs can do in such a short amount of time. Congrats!.

Introducing Pika 1.0, the idea-to-video platform that brings your creativity to life. Create and edit your videos with AI. Rolling out to new users on web and discord, starting today. Sign up at
7
13
268
It won't be perfect, it won't be good for everything, but the potential feels unlimited once more. Feeling the AGI again.
6
11
177
@simonw @OpenAIDevs @OpenAINewsroom You're exactly correct here! o1-preview is a preview of the upcoming o1 model, while o1-mini is not a preview of a future model. o1-mini might get updated in the near future as well but there is no guarantee.
4
17
154
And we are hiring! Come work with us on pushing the frontiers of both model capability and efficiency.
Excited to bring o1-mini to the world with @ren_hongyu @_kevinlu @Eric_Wallace_ and many others. A cheap model that can achieve 70% AIME and 1650 elo on codeforces.
4
6
141
❤️.

i love the openai team so much.
5
9
131
🚨[New Paper] Should you trust calibrated predictions for high-stakes decisions? Check out to see what calibration actually means for decision-making, and a new decision-tailored calibration notion. With @mikekimbackward, Roshni, @tengyuma, @StefanoErmon

2
19
118
Breaking news: the board asked my dog to be the inter-rim CEO and it declined.

0
1
94
What a ride! Time to get back to building cool things.

We have reached an agreement in principle for Sam Altman to return to OpenAI as CEO with a new initial board of Bret Taylor (Chair), Larry Summers, and Adam D'Angelo. We are collaborating to figure out the details. Thank you so much for your patience through this.
3
3
97
The new AI challenge should be to come up with an eval that is actually solvable by people/gradable and survives for >1 yr.

o3 represents enormous progress in general-domain reasoning with RL — excited that we were able to announce some results today! Here’s a summary of what we shared about o3 in the livestream (1/n)
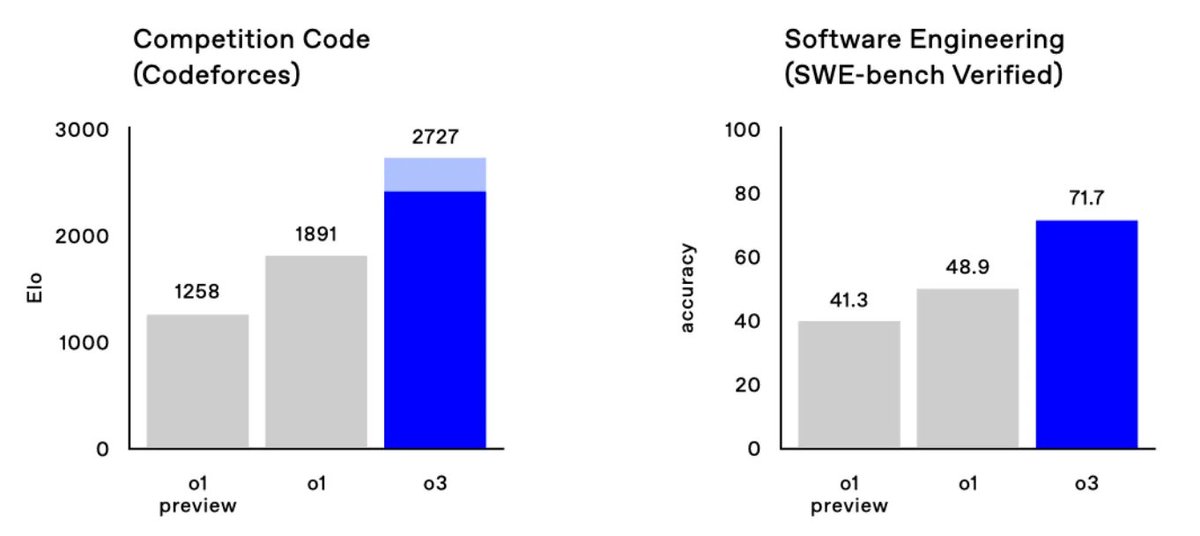
6
3
95
❤️.

OpenAI is nothing without its people.
1
1
78

We are going to build something new & it will be incredible. Initial leadership (more soon): @merettm @sidorszymon @aleks_madry @sama @gdb. The mission continues.
1
1
56
Congrats to the team! This is truly on the next level.
Introducing Sora, our text-to-video model. Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. Prompt: “Beautiful, snowy
1
1
57
AI is becoming 10x cheaper for the same capability every year. Excited to work with @jacobmenick @_kevinlu @Eric_Wallace_ et al on it.

Introducing GPT-4o mini! It’s our most intelligent and affordable small model, available today in the API. GPT-4o mini is significantly smarter and cheaper than GPT-3.5 Turbo.

1
3
54
How can you guarantee the correctness of each individual prediction? New work with @StefanoErmon (AISTATS'21 oral) provides a new perspective on this age-old dilemma based on ideas like insurance and game theory. Blog: Arxiv:

0
10
51
My account was hacked. I do NOT endorse any crypto or web3 project. Thanks to everyone who helped to spot this and prevent damages. The lesson is to turn on 2FA and always have a second thought of "is this phishing" before clicking on anything :(.
30
3
43

@felixchin1 @AIMachineDream @OpenAIDevs Sry for confusion. I just meant o1-mini is currently allowed a higher maximum token because of the lower cost, so can continue to think for questions that o1-preview is cut-off. It doesn't mean o1-mini will necessarily use more tokens for the same question.
1
2
48
Training big models are hard and congrats to the team on the incredible work putting all of this together!.
Today we’re releasing a research preview of GPT-4.5—our largest and best model for chat yet. Rolling out now to all ChatGPT Pro users, followed by Plus and Team users next week, then Enterprise and Edu users the following week.
1
1
44
Individually calibrated forecaster is (almost) impossible to learn from finite datasets, but it's possible if we learn randomized forecasters. We show how to do this in our ICML'2020 paper with @tengyuma @StefanoErmon

0
8
37
@abhagsain @OpenAIDevs Historically prices go down 10x every 1-2 years, the trend will probably continue.
1
0
30
A mixture of Gaussian can achieve much better log likelihood than GAN. @adityagrover_ Maybe log likelihood need modification in the context of GANs? It is interesting to find something gentler on disjoint supports and easy to estimate.

New evaluation metrics are great, but please, please also measure the metrics we already understand, like test log-likelihood!.
1
7
26
🚨 If a provider predicts that a vaccine is 95% effective for you, should you trust the 95% when making decisions? We show how to enable decisions with complete confidence. AISTATS oral happening in 1 hour ..Blog

2
6
25
Really like this paper. Optimizing parameters over a random subspace as a measurement of effective complexity of a task w.r.t. a network architecture. A simple strategy but very effective and lots of good insights! .via @YouTube.
0
8
22

lol that is so funny.

OpenAI is nothing without its bobas and chicken nuggets.
0
0
18




Everything is fine!.
ChatGPT with voice is now available to all free users. Download the app on your phone and tap the headphones icon to start a conversation. Sound on 🔊
0
0
18
Really nice summary of the huge number (20?) of methods to evaluate GANs. Free lunch theorem for GANs: for any new GAN model there is some metric it improves.
0
4
17
@abhagsain @OpenAIDevs For example, the cost per token of GPT-4o mini dropped by 99% since text-davinci-003.
1
0
16
Getting reassured that feeling stupid is at least a good sign XD.

The importance of stupidity in scientific research!. I show this brilliant essay to all my new PhD students. It contains some excellent advice on how to handle – and even learn to love – the feeling of being constantly immersed in the unknown.

0
2
16
Wow this is like finding a treasure box. Amazed at the number of great lectures to be found no where else
3
1
14
@felixchin1 @AIMachineDream @OpenAIDevs There are problems where this is the case, but it is not the only (and likely not the main) reason that o1-mini is better on some prompts. I think the main reason is just o1-mini is specialized to be really good on certain things while o1-preview is more general purpose.
1
1
13
Found this excellent paper on algorithmic information theory. As light a read as ever gets for this topic. Really like the conceptual satisfaction of a beautiful theory defining fundamental meaning of structure and intelligence. (Despite incomputable).
0
5
15
Yes.

I have the growing feeling that the entire OpenAI debacle is going to be much less about four dimensional strategic chess and more about human mistakes, errors, confusion & conflicting motives. As it almost always is.
0
0
12
@MIT_CSAIL @zhaofeng_wu This feels more like an alignment problem than a lack of underlying abilities. It's like showing a person a new language and asking them to immediately do math in it. What if you finetune the model on 1M tokens of the new language?.
4
0
11
The best explanation and summary of normalizing flows I have seen. Highly recommend.
0
3
12
Feels like I just bought tickets for a theme park. There are sooo many pricing options and discount packages, very confusing! What is the best deal you got? #AAAI2019


1
0
10
Really good summary of the contraversy surrounding the nature of probability/randomness .Interesting because the goal of ML is to ``model structure instead of randomness''. But whatever that means is still up to debate. (esp. unsupervised learning).
0
4
9
Evaluation will become the hardest part of LLMs :).

Progress in AI continues to outpace benchmarks. Check out this new plot, inspired by @DynabenchAI, that shows just how quickly it's happening. Read more about it here:

1
0
10
Really insightful paper! Instead of compressing a single image with a VAE, compressing a set of images captures inter-image regularities.
0
2
10
Nice paper capturing meaningful latent structure with graphical models and optimized with GANs
0
2
10
Only reading the first couple chapters changed fundamentally how I view prob and stats. Highly recommended
1
4
9
@alanpog @OpenAIDevs We are working on it. Fresher data is one of the goals for future iterations of the model.
0
0
7
@MingyangJJ @OpenAIDevs It is a highly specialized model. This allow us to focus on just a few capabilities and hence can push them very far.
1
1
9
GPT-4 has finally landed!.
Announcing GPT-4, a large multimodal model, with our best-ever results on capabilities and alignment:
2
0
8
Very enjoyable introduction

Attention Solves Your TSP by W. Kool and M. Welling. This paper has a Kool intro. Paper: .@PyTorch Code:

0
2
8
@brandondataguy @_kevinlu @ren_hongyu @Eric_Wallace_ The preview model is better on reasoning + knowledge, such as gpqa.
1
0
5
I wonder what are the applications of these classical papers in light of modern generative models, which handle complex inputs, but do not assume much more structure other than vector space in latent space.
0
2
5
@TheShubhanshu @ermonste Thanks for the question! MMD does not require reparameterization because it is likelihood free optimization, so q(z|x) need not be a distribution(But it can be).
1
1
5
I'm quite sure that GPT-4 has not degraded over time in the cognitive evals (exams, MMLU, etc). The problem is that they only test prime numbers and not composite numbers. The Mar model always says prime, and the June model always says not prime, but you would get 100% on their.

Many of us practitioners have felt that GPT-4 degrades over time. It's now corroborated by a recent study. But why does GPT-4 degrade, and what can we learn from it?. Here're my thoughts:. ▸ Safety vs helpfulness tradeoff: the paper shows that GPT-4 Jun version is "safer" than
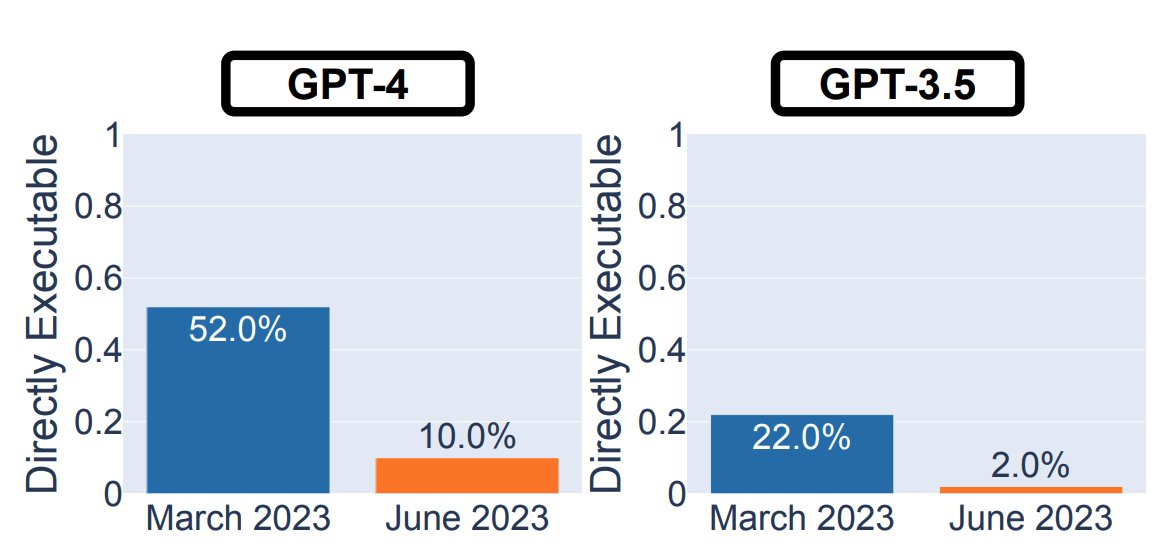
0
0
4
And that is how the universe was born from a bowl of spicy ramen.

Obsessed with the new “make it more” trend on ChatGPT. You generate an image of something, and then keep asking for it to be MORE. For example - spicy ramen getting progressively spicier 🔥 (from u/dulipat)




0
0
4
Amazing work!.

This sentiment is exactly right - and why we've been working to increase sequence length in our lab for the past two years!. From FlashAttention, to S4, H3, Hyena, and more - check out our blog post putting this line of work into context: More below: 1/n.
0
0
3
@hwchung27 Not on the exponential scale? Like so much leverage that outcome = e^effort [adding to the stress lol].
1
0
2
By no-free-lunch all models rely on inductive bias. Current bias of DL are good for some tasks only. Doesn't seem like a fault of DL though.

My quick write-up on the limitations of deep learning: It's meant as an intro to tomorrow's post on the future of DL.
0
0
2
@TheShubhanshu @ermonste @PyTorch Thanks! Added a link to your repo in our post if that is okay. Updated version should appear soon.
1
0
2
Congrats Aditya!.

Thrilled to share that my PhD dissertation won the ACM SIGKDD Dissertation Award for "outstanding work in data science and machine learning". Thanks to everyone involved, especially my advisor @StefanoErmon & @StanfordAILab!.
1
0
2
@poolio Thanks for pointing that out! I guess they have a somewhat different motivation but derived the same model. It would be nice if both papers can mention each other.
0
1
2
Sounds like a probably approximately optimal strategy!

ICLR18 is going to be in Vancouver next year and will now have double blind open reviews (great idea!). CfP here:
0
0
2
@arishabh8 @ermonste Thanks! There is a good exposition in Gretton et al. 2007 referenced in our blog.
0
0
1
@evrenguney I guess I would consider it stratification. Each dimension is partitioned into bins, and each bin contain a fixed number of samples.
0
0
1
Amazing! Congrats on the new adventure!.

Excited to share that I will join @USC as an Asst. Professor of Computer Science in Jan 2024—and I’m recruiting students for my new lab! 📣. Come work at the intersection of machine learning, decision making, generative AI, and AI-for-science. More info:



0
0
1
Maybe this is why GANs work since it is virtually impossible to model the distribution of natural image. E.g. Chaotic patterns.

Dunno how many times I can say this - GANs aren't really learning the distribution of data - just making pretty pictures.
0
0
1