
Brandon Amos
@brandondamos
Followers
19K
Following
10K
Media
446
Statuses
4K
research scientist @MetaAI (FAIR) | optimization, machine learning, control, transport | PhD from @SCSatCMU
Joined January 2014
Many standard probability distributions can be obtained by solving a maximum-entropy optimization problem over distributions. For example, the Gaussian maximizes the entropy subject to mean and covariance constraints. Jax source code: More resources: 🧵
5
137
826
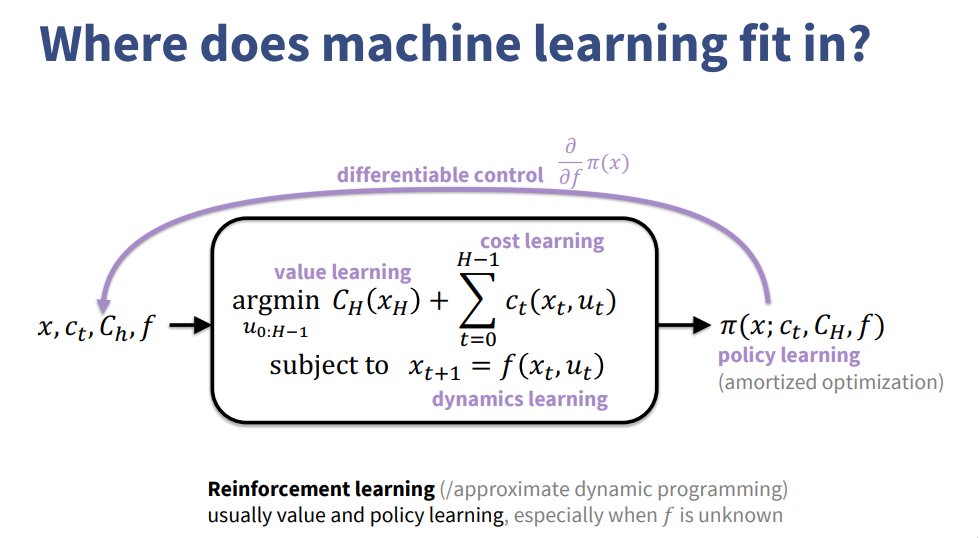
I just posted a new tutorial on amortized optimization! It covers foundations for learning to optimize and how they are key ingredients for VAEs, RL, meta-learning, and sparse coding with budding applications in DEQs, convex optimization, and beyond. 🧵



9
144
751
📢 Today's my first day at Cornell Tech :). I will continue my full-time position as a scientist at Meta, and am teaching ML here on the side for the semester with @volokuleshov. The course is open source and you can follow everything in this repo:.

35
46
662
I just open-sourced 200+ slides from the major presentations I've given over the past 5 years:.
3
70
586
📚 My mini-book on amortized optimization is officially published! Via the Foundations and Trends® in Machine Learning journal (. Buy a physical copy: Free online version: Source code:

13
108
589
We've released differentiable convex optimization layers for JAX!. Code: Tutorial: NeurIPS paper: Blog post: With @akshaykagrawal, @ShaneBarratt, S. Boyd, S. Diamond, and @zicokolter



5
126
561
📢 My team at Meta is hiring PhD research interns! We study core machine learning, optimization, amortization, flows, and control for modeling and interacting with complex systems (. and we use basic physics. 🙃). Please apply here and message me:. 🧵



15
92
557
A life update. I've dodged all of the attacks and have successfully defended my PhD thesis. Thanks everybody!. My thesis document and slides are available on GitHub.
19
41
518
Tuning Hyperparameters without Grad Students: Scalable and Robust Bayesian Optimisation with Dragonfly.K. Kandasamy et al. Python Library: Docs:

6
128
415
:). (context for the reader: this is a slide from my fundamental differentiable optimization layers talk, which I've been giving since ~2017. @alfcnz has been inspirational on the "soft-argmax" naming for years!!)


I am the only one on #ML twitter who doesn't like the name 'softmax' for exp(x) / sum(exp(x)) , and instead prefers the name 'soft-argmax'? .Softmax is LogSumExp!.
5
52
421
Our new paper on Meta Optimal Transport uses amortized optimization to predict initializations and improve optimal transport solver runtimes by 100x and more. With @CohenSamuel13 @GiuliaLuise1 @IevgenRedko . Paper: JAX source code:
6
58
404
📢 In our new @UncertaintyInAI paper, we do neural optimal transport with costs defined by a Lagrangian (e.g., for physical knowledge, constraints, and geodesics). Paper: JAX Code: (w/ A. Pooladian, C. Domingo-Enrich, @RickyTQChen)
6
63
410
Flows and transport methods are widely used to connect one distribution to another. What about going up one level to transporting between distributions over distributions?. My new talk overviews some methods in this space:. & a quick 🧵 below
1
74
400
A draft of my thesis is now on GitHub. Please let me know if you want to attack me as I'll be defending it next week.


19
43
382
Here's a new lecture I made on learning embeddings with multidimensional scaling and TSNE for our ML course at Cornell Tech (with @volokuleshov). It covers the formulation and goes through some code for a deeper look. Notebook: PDF:
5
56
383
👀. "Amos can improve generalization and accelerate convergence"."Amos consistently outperforms the state-of-the-art"."we analyze the behavior of Amos in an intuitive and heuristic manner".

Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!. New from Google Research. Preprint:

15
16
314
Attention Solves Your TSP by W. Kool and M. Welling. This paper has a Kool intro. Paper: .@PyTorch Code:

1
80
312
& here are some of my favorite papers on the unification of flows and diffusion. What a decade!!. (From my presentation here:


How Diffusion unification went:. > score based model.> then DDPM came along.> we have two formalism, DDPM & SBM.> SDE came to unify them.> now we have Score, DDPM & SDE.> Then came flow matching to unify them.> now we have Score, DDPM, SDE & Flow Models.> Then consistency models.
4
42
317
Stoked to release our milestone #ICML2021 paper on Riemannian Convex Potential Maps! With @CohenSamuel13 and @lipmanya. Paper: JAX Code: Slides: 🧵


3
60
296
Stoked to share a milestone project for all of us! #NeurIPS2019 paper with @akshaykagrawal, @ShaneBarratt, S. Boyd, S. Diamond, @zicokolter:. Differentiable Convex Optimization Layers. Paper: Blog Post: Repo:

CVXPY is now differentiable. Try our PyTorch and TensorFlow layers using our package, cvxpylayers: (& see our NeurIPS paper for details .
4
83
302
Excited to share my first paper with @facebookai:. The Differentiable Cross-Entropy Method.with @denisyarats. Paper: Videos:

2
52
295
[2017] The Consciousness Prior: [2018] Learning Awareness Models: [2021] A Theory of Consciousness from Theoretical Computer Science & the Conscious Turing Machine: [2022] Learning Consciousness Models
4
43
285
Our new paper - OptNet: Differentiable Optimization as a Layer in Neural Nets. Paper: Code:

4
93
275
Coloring math in your papers, not just in your presentations and posters, is a great idea and helps readability if done correctly. Like in the 2011 PILCO paper:

6
61
272
📢 My team at Meta is hiring visiting PhD students from CMU, UW, Berkeley, and NYU! We study core ML, optimization, amortization, transport, flows, and control for modeling and interacting with complex systems. Please apply here and message me:.
9
41
276
I'm excited to announce our new @PyTorch model predictive control library! We use this in our (forthcoming) NIPS 2018 paper. This is joint work with I. Jimenez, J. Sacks, B. Boots, and @zicokolter. Project Website: GiHub Page:

3
63
268
One more interesting interpretation of the softmax is that it is a projection onto the simplex. The usual solution comes from the KKT conditions. Details in Ch 2 of my thesis: And you can implement it this way in PyTorch/TF with:

7
50
262
In our new paper we scale model-based reinforcement learning to the gym humanoid by using short-horizon model rollouts followed by a learned model-free value estimate. Paper: Videos: With @sam_d_stanton @denisyarats @andrewgwils
2
62
249
We've been studying differentiable combinatorial optimization layers and just posted our #ICML2021 paper on CombOptNet! With @AnselmPaulus @MichalRolinek @vit_musil @GMartius. Paper: @PyTorch Code:

3
38
222
We're hiring research scientist interns in FAIR's Core ML team at Meta! Please send an application here and get in touch if you're interested.
5
31
222
After 6 years of review (! longer than my PhD) one of my first papers has been published in the ACM Transactions of Mathematical Software:. Alg. 1007: QNSTOP—Quasi-Newton Algorithm for Stochastic Optimization. Paper: FORTRAN Source:

8
8
217
Excited to share our #nips2018 paper on differentiable MPC and our standalone @PyTorch control package!. Joint work with Jimenez, Sacks, Boots, and @zicokolter. Paper: @PyTorch MPC Solver: Experiments:


4
74
204
🤔 How to extract knowledge from LLMs to train better RL agents?. 📚 Our new paper (with @qqyuzu @HenaffMikael @yayitsamyzhang @adityagrover_ ) studies LLM-driven rewards for NetHack!. Paper: Code:



2
41
206
I just finished my @PyTorch implementation of DenseNet-BC, which gets 4.77% error on CIFAR-10+.

6
50
187
We just posted a longer version of our slides on convex optimization, flows, input-convex neural networks, and (Riemannian) optimal transportation:
Stoked to release our milestone #ICML2021 paper on Riemannian Convex Potential Maps! With @CohenSamuel13 and @lipmanya. Paper: JAX Code: Slides: 🧵
0
26
192
Hydra is an awesome new lightweight experiment manager (and beyond) from @facebookai -- I've been using it with all of my @PyTorch experiments for config/cluster scheduling/hyper-param sweeps. Code:

Hydra is live at .Facebook engineering post:. More info:.
8
36
189
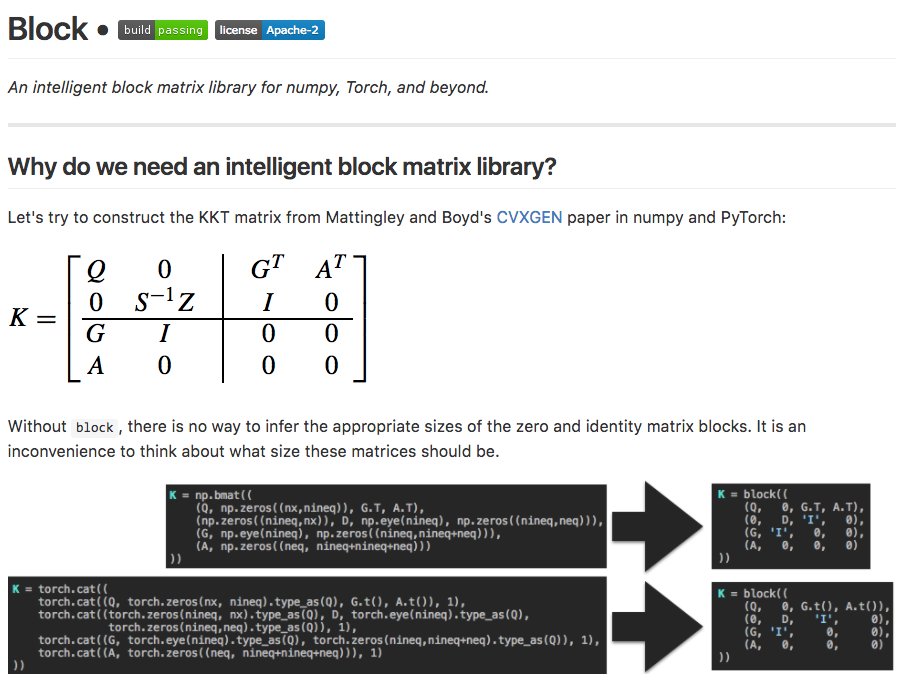
block: My [short] new Python library for intelligent block matrices in numpy, @PyTorch, and beyond.
0
86
181
I am on the job market!. Website and CV: Google Scholar: GitHub:

9
24
188
I've posted a new paper on amortizing convex conjugates for continuous optimal transport along with new JAX software for (Euclidean) Wasserstein-2 OT!. 🧵
7
28
178
📢 My team at Meta (including @lipmanya and @RickyTQChen) is hiring a postdoctoral researcher to help us build the next generation of flow, transport, and diffusion models! Please apply here and message me:.
5
34
179
Just released a new blog post and code! Image Completion with Deep Learning in TensorFlow
6
123
167
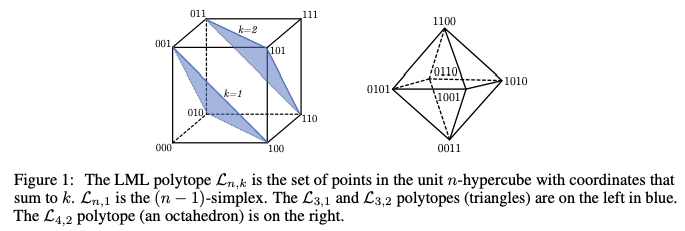
Excited to share my new tech report from my @IntelAI internship on the Limited Multi-Label projection layer! Joint work with Vladlen Koltun and @zicokolter. Paper: @PyTorch Code:


1
36
165
Our Meta OT paper was rejected from @NeurIPS despite having WA/A/SA throughout the discussion period. How did it happen? The AC based the decision on a review that came a month late that we couldn't even respond to. We've made the full discussion public:.

5
7
157
Lately I've been interested in LLM prompt optimization and amortization. Here's my new Dagstuhl talk highlighting some of my favorite papers in the space:. 📚 & our AdvPrompter paper amortizes prompt optimization for jailbreaking:
4
18
156
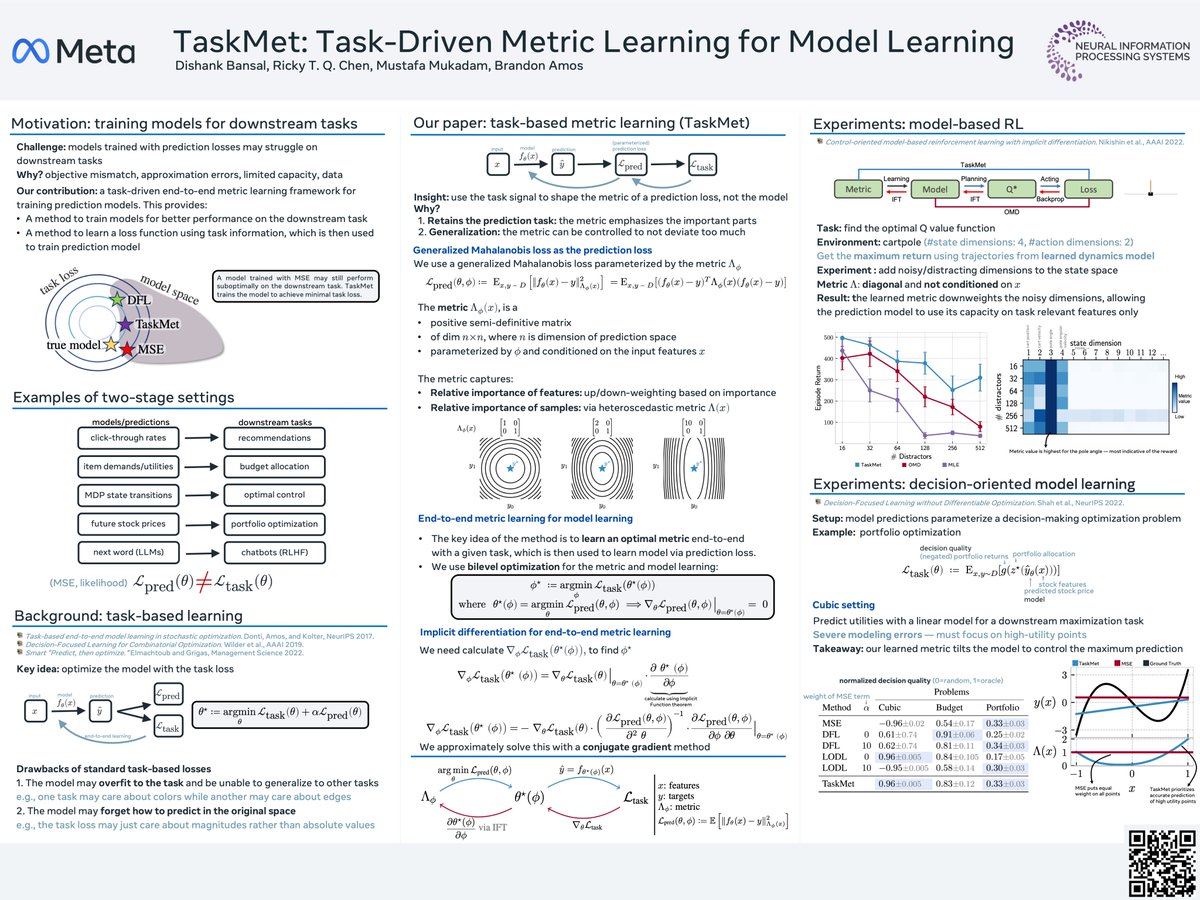
Our new #NeurIPS2023 paper shows how to learn a task-driven metric on the prediction space! Come chat at our poster (#1128) on Weds at 10:45am. Paper: Code: Talk: with @theshank9 @RickyTQChen @mukadammh
2
25
146
Come intern at @facebookai and do awesome ML/AI/RL/NLP/vision/optimization/game theory research with us. && write beautiful @PyTorch code while doing so. Please get in touch!. More details:
1
16
147
TensorFlow has a great new K-FAC library in tf.contrib by the authors and collaborators:.


2
60
138
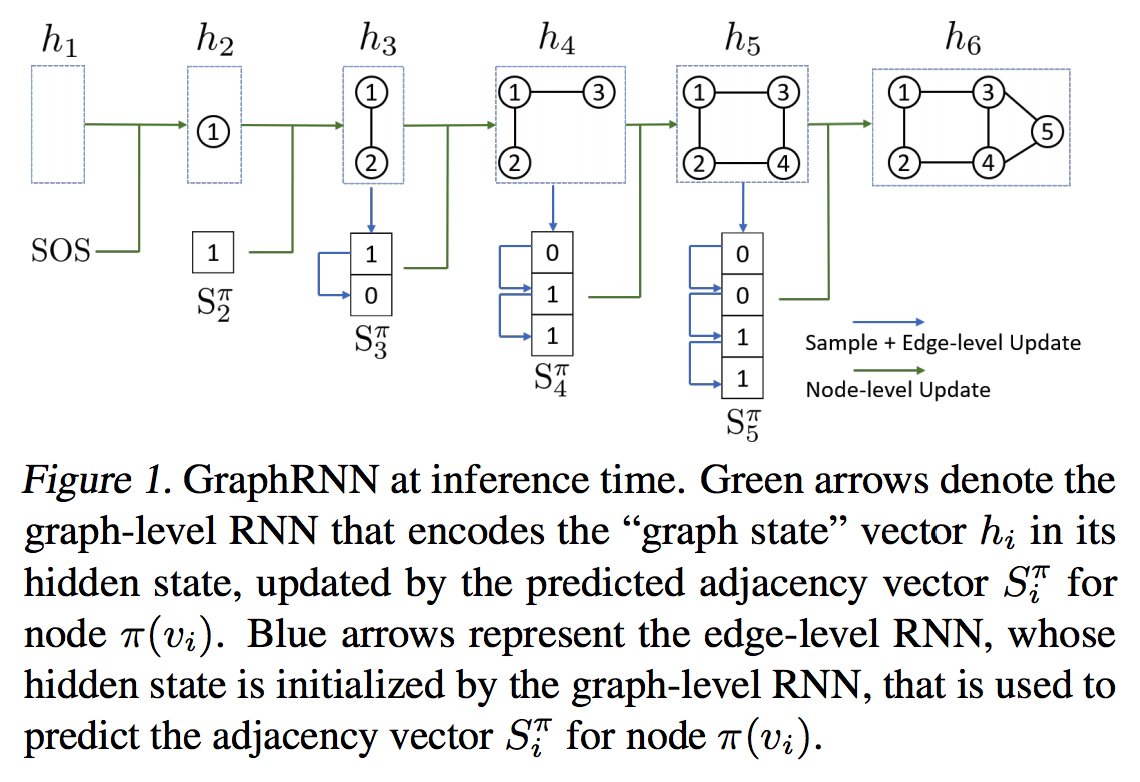
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Model by @youjiaxuan, R. Ying, @xiangrenUSC, @williamleif, and @jure. #ICML2018 Paper: @PyTorch Code: Unofficial Slides:

0
44
140
Also on debugging layers/tools, I'd love to see more "unit tests" for research, like in this ICLR 2014 paper:.

0
40
140
I'm in SF for the @PyTorch developer conference. Come and say hi! Here's a poster with some of my contributions to the thriving PyTorch ecosystem.

2
15
137
🎉 Our new paper generalizes Flow Matching to the /Meta/ setting, where we solve (and amortize 😅) a family of FM problems simultaneously. We do this via a GNN-based conditioning and use Meta FM between cell populations. See @lazar_atan's thread for more info!.

🚀Introducing — Meta Flow Matching (MFM) 🚀. Imagine predicting patient-specific treatment responses for unseen cases or building generative models that adapt across different measures. MFM makes this a reality. 📰Paper: 💻Code:


6
12
136
With @denisyarats, we've released the @PyTorch code and camera-ready version of our #ICML2020 paper on the differentiable cross-entropy method. Paper: Code: Videos: More details in our original thread:.
Excited to share my first paper with @facebookai:. The Differentiable Cross-Entropy Method.with @denisyarats. Paper: Videos:
1
41
132
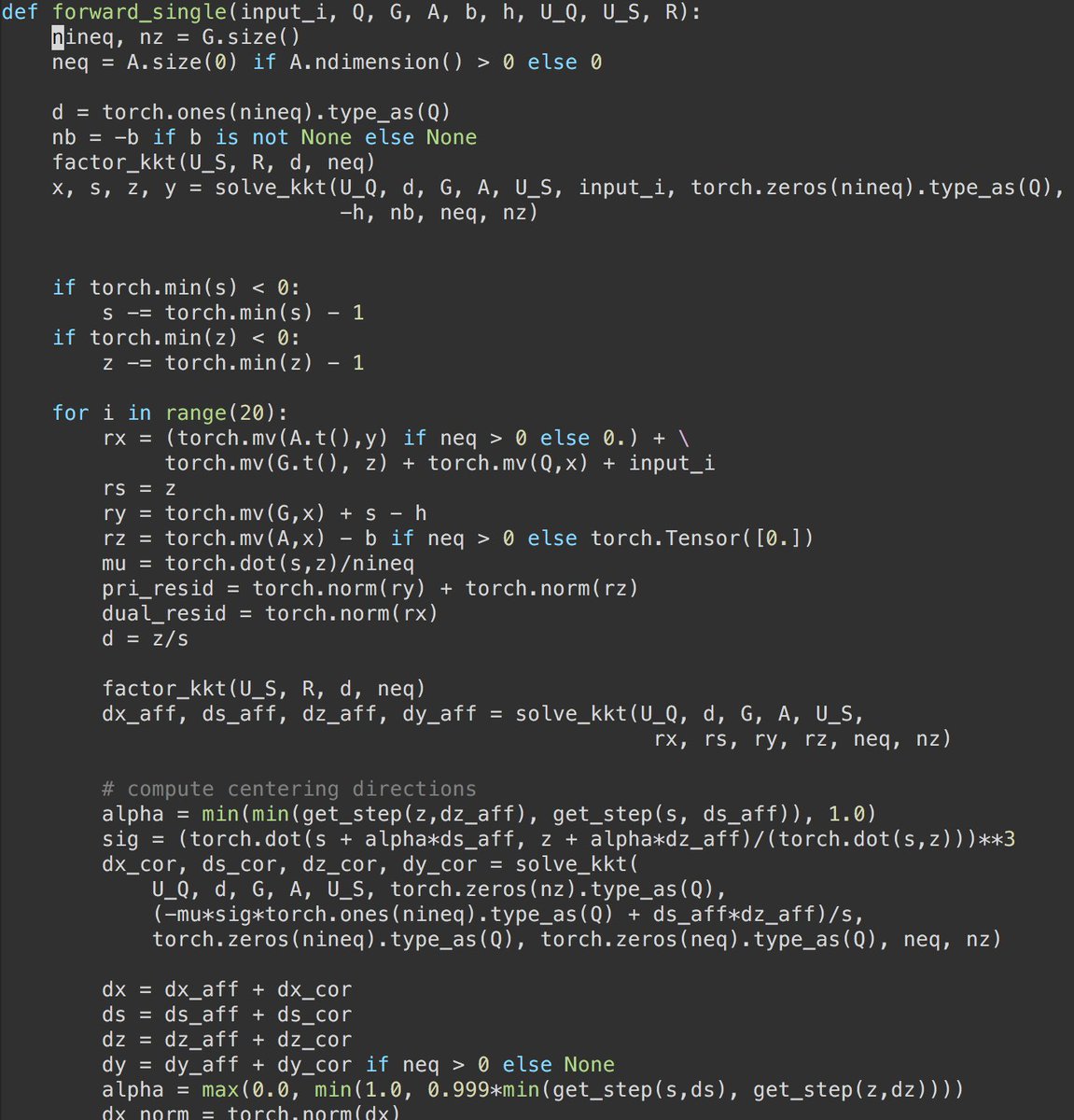
Why PyTorch's layer creation is powerful: Here's my layer that solves an optimization problem with a primal-dual interior point method.
6
56
129
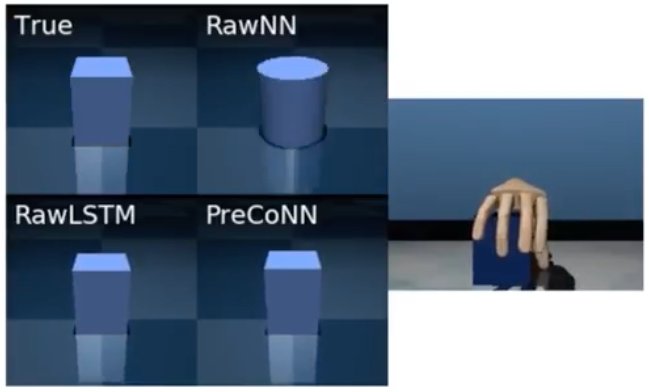
Our new #iclr2018 paper on Learning Awareness Models, with @laurent_dinh @serkancabi @notmisha @NandoDF and many others. Paper: Videos:


2
48
132

SparseMAP: Differentiable Sparse Structured Inference by @vnfrombucharest et al. #icml2018 Paper: @PyTorch Code:

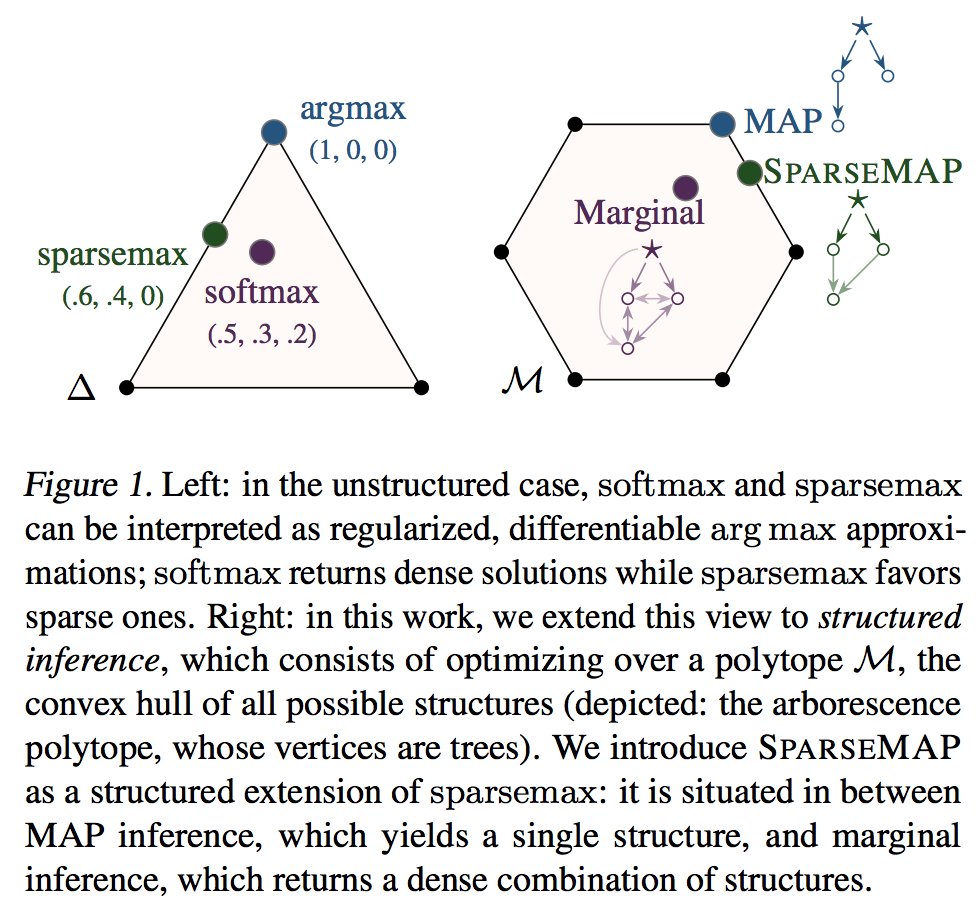
0
44
132
Here's my #CVPR2020 deep declarative network workshop talk on differentiable optimization:. Video: Slides:

2
31
129


Here's my take on an LLM intro for our ML course at Cornell Tech (with @volokuleshov). It starts with the foundations then goes through code to use pretrained models for 1) generation, 2) chat, and 3) code infilling. pdf: ipynb:
2
19
127
The Wasserstein distance works well for imitation learning on a single system: Our new paper explores the cross-domain setting and uses the Gromov-Wasserstein distance to imitate between /different/ systems:

We provably achieve cross-domain transfer in non-trivial continuous control domain by minimizing the Gromov-Wasserstein distance with deep RL. Paper: Site: Joint work with @CohenSamuel13 Stuart Russell @brandondamos. A thread:
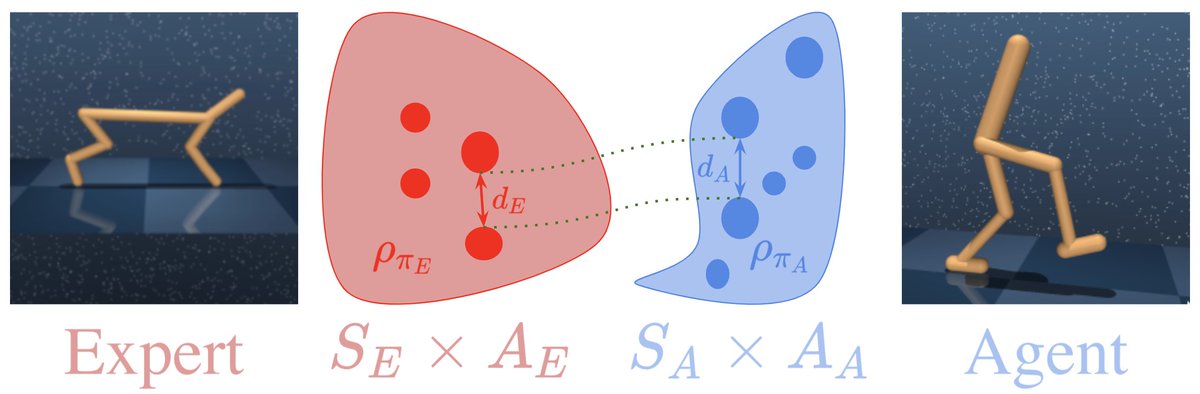
2
17
122
Smooth Loss Functions for Deep Top-k Classification.Leonard Berrada, Andrew Zisserman, M. Pawan Kumar.ICLR 2018. @PyTorch code:

0
32
120
This is a great post! The argmin operations that come up here can be prototyped in PyTorch/TF/(+Jax soon) in a few lines of code with cvxpylayers: Our blog post has working code examples for the sparsemax/csparsemax/LML and others:

Notebook for🤗 Reading Group this week on understanding softmax, entropy, and `Adaptively Sparse Transformers` from Correia, Niculae, and Martins.



1
24
116
Excited to share our NeurIPS workshop on Learning Meets Combinatorial Optimization (LMCA)! Consider submitting a 4-page paper if you're working in the area (due Oct 5):. With @vlastelicap, J. Song, A. Ferber, @GMartius, @BDilkina, and @yisongyue

2
30
111
These ICML 2019 papers on exploring via disagreement are awesome:. Model-Based Active Exploration.@recurseparadox, @WJaskowski, F. Gomez. Self-Supervised Exploration via Disagreement.@pathak2206, D. Gandi, A. Gupta. 1/5.
2
29
115
Some related papers for our recent Lagrangian OT:. 0. On amortizing convex conjugates for OT.1. Neural Lagrangian Schrödinger Bridge.2a. Deep Generalized Schrödinger Bridge.2b. DGSB Matching.3. Wasserstein Lagrangian Flows.4. Metric learning via OT. A 🧵 summarizing these ❤️.
📢 In our new @UncertaintyInAI paper, we do neural optimal transport with costs defined by a Lagrangian (e.g., for physical knowledge, constraints, and geodesics). Paper: JAX Code: (w/ A. Pooladian, C. Domingo-Enrich, @RickyTQChen)
4
11
110
Our new paper 'Input Convex Neural Networks': The code is also online at:


3
44
100
Excited to finally share our #ICLR2021 papers! With @RickyTQChen and @mnick. Neural Event Functions for ODEs. Neural Spatio-Temporal Point Processes. 🧵 following with virtual posters


1
16
97
I'm giving an #ISMP2024 talk today (Tue) at 5:20pm in 514C on amortized optimization for two seemingly separate topics: optimal transport and LLMs :). If you're not around, I just uploaded the slides to and here's a gif going through them. & a short 🧵.
If you're at #ISMP2024, we're having a session today on learning and verification for continuous optimizers!!. w/ @RSambharya V. Ranjan, and @b_stellato

2
9
94
The satire in one of my ICML reviews is pretty good. The reviewer rejected my paper in a few egregiously wrong sentences and then sprinkled in that I defined the |.| operator only for set cardinality but used it in another context for the absolute value. 😬.
4
9
96


JAX's Optimal Transport Tools (OTT) package by @CuturiMarco et al. was crucial for developing our new Meta OT paper. I highly recommend looking into it if you are developing new OT ideas!. Code: Docs: Paper:
Our new paper on Meta Optimal Transport uses amortized optimization to predict initializations and improve optimal transport solver runtimes by 100x and more. With @CohenSamuel13 @GiuliaLuise1 @IevgenRedko . Paper: JAX source code:
2
14
89
I'm at #NeurIPS2019! Get in touch if you want to talk about. derivatives. And check out our paper and poster on Weds evening: (I'm also open to talking about things that are not derivatives).
Stoked to share a milestone project for all of us! #NeurIPS2019 paper with @akshaykagrawal, @ShaneBarratt, S. Boyd, S. Diamond, @zicokolter:. Differentiable Convex Optimization Layers. Paper: Blog Post: Repo:
1
5
89
I'm giving a talk at 1:30pm today (Sat) at the #NeurIPS2023 OTML workshop (room 220-222) on amortized optimization for optimal transport. Come by to learn more!. Workshop: Slides:



1
18
89

Differentiating through the Fréchet Mean.A Lou, @isaykatsman, Q. Jiang, @SergeBelongie, S. Lim, @chrismdesa.



1
17
84

Variational Inference in Probabilistic Submodular Models.Doctoral Dissertation, ETH Zurich.Josip Djolonga.



0
21
78

good times 😅 *checks date* . over one decade ago~


please don't apply for a senior dev position if your github looks like this.

2
1
81
"Beware of math books that don't use pictures to convey ideas.". - Last sentence of Pugh's real analysis book. (Found by @gabrfarina)


1
23
75
In our finalized L4DC paper, we study the stochastic value gradient for continuous model-based RL. Paper: @PyTorch Code: Slides: Talk: With @samscub @denisyarats @andrewgwils
1
12
77
I'm at #NeurIPS2018! If we run out of preprints and ICLR subs to talk about, here are my papers:. Differentiable MPC (with @zicokolter et al., poster Thu 5pm): Imperfect-Info Game Solving (mostly by @polynoamial, poster Wed 5pm):
Excited to share our #nips2018 paper on differentiable MPC and our standalone @PyTorch control package!. Joint work with Jimenez, Sacks, Boots, and @zicokolter. Paper: @PyTorch MPC Solver: Experiments:
0
17
76
In our #automl workshop at @icmlconf, @trailsofwater and I look into learning better convex optimization solvers. Paper: @PyTorch Code:

4
14
76
Here are some of my quick thoughts on seven awesome and super-promising applications areas of differentiable optimization-based modeling. From the last chapter of my thesis:



0
15
75
Here's our new paper on jailbreaking LLMs! To do this, we learn /another/ LLM called AdvPrompter to generate a semantically meaningful suffix conditional on a malicious instruction. with @AnselmPaulus @ArmanZharmagam1 C. Guo @tydsh


2
13
74
Deep Frank-Wolfe For Neural Network Optimization.Leonard Berrada, Andrew Zisserman, M. Pawan Kumar. @PyTorch code:

1
20
69
Excited to share our new @aistats_conf paper on time series alignment on incomparable spaces! With @CohenSamuel13, G. Luise, @avt_im, and @mpd37. Paper: @PyTorch Code: Blog post:

Pleased this joint work on time series alignment with amazing collaborators will be at AISTATS!! @GiuliaLuise1 @avt_im @brandondamos @mpd37.
1
12
72
MetaOptNet: Meta-Learning with Differentiable Convex Optimization.CVPR 2019 Oral.



0
14
72
We've added a Meta OT initializer to the Optimal Transport Tools (OTT) JAX package!. Tutorial: Docs: With @CuturiMarco, @JamesTThorn, and Michal Klein

Our new paper on Meta Optimal Transport uses amortized optimization to predict initializations and improve optimal transport solver runtimes by 100x and more. With @CohenSamuel13 @GiuliaLuise1 @IevgenRedko . Paper: JAX source code:
1
8
71

Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement.W. Kool, H. van Hoof, M. Welling.

1
9
69


There Is No Free Lunch In Adversarial Robustness.(But There Are Unexpected Benefits).



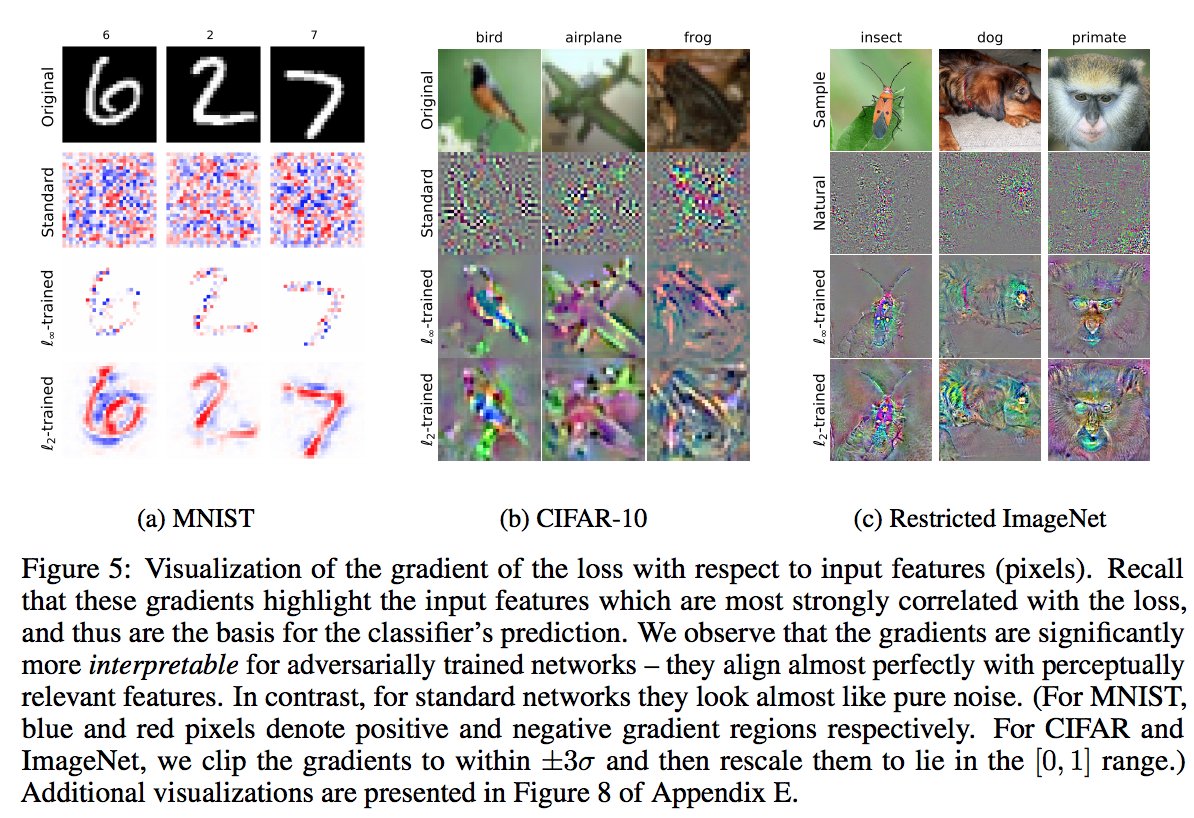
1
22
64
draw_convnet - a Python script for illustrating neural nets by Gavin Weiguang Ding

1
30
64
🎉 @PyTorch code:

Our new paper, with @zicokolter and Vladlen Koltun, on extensively evaluating convolutional vs. recurrent approaches to sequence tasks is on arXiv now!
2
24
62
The Wasserstein GAN code is another great PyTorch example:. Paper: Code:

0
21
62
qpth (by me and @zicokolter) has a new website and works with the @PyTorch master branch instead of our fork.

1
18
61