
Phillip Isola
@phillip_isola
Followers
17K
Following
5K
Media
107
Statuses
650
Associate Professor in EECS at MIT, trying to understand intelligence.
Joined December 2016
#BigGAN is so much fun. I stumbled upon a (circular) direction in latent space that makes party parrots, as well as other party animals:
31
658
3K
Our computer vision textbook is released!. Foundations of Computer Vision.with Antonio Torralba and Bill Freeman. It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields. 1/4

41
403
2K
New paper: The Platonic Representation Hypothesis. In which we posit that _different_ foundation models are converging to the _same_ representation of reality. paper: website: code: 1/8.
37
253
1K
Language-conditional models can act a bit like decision transformers, in that you can prompt them with a desired level of "reward". E.g., want prettier #dalle creations? "Just ask" by adding "[very]^n beautiful":. n=0: "A beautiful painting of a mountain next to a waterfall."

34
199
1K
A simple, fun example to refute the common story that ML can interpolate but not extrapolate:. Black dots are training points. Green curve is true data generating function. Blue curve is best fit. Notice how it correctly predicts far outside the training distribution!. 1/3

61
134
1K
We’re releasing a new image similarity metric and dataset!. --> DreamSim: a metric which outperforms LPIPS, CLIP, and DINO on similarity and retrieval tasks.--> NIGHTS: a dataset of synthetic images with human similarity ratings. paper+code+data: 1/n

11
194
901
An interesting thing about ChatGPT is you can script in it a bit like you would in a programming language. You can define functions, compose them, etc. Except all in natural language!. This means you can write out common tasks and attach them to command names. For example:. 1/n

13
114
789
This figure from group norm ( is super useful for anyone trying to keep track of how all these things relate:

2
229
694
Back in 2018 at OpenAI, a few of us wrote a story with gpt as an AI "co-author". We didn't have an AI illustrator back then, but now we sort of do, so I tried plugging the text into #dalle. Here is the result! “The Bees”, a short story by humans & AIs:

17
77
595
This looks like one of those results that marks a phase transition in science: for years people have anticipated that synthetic data would eventually outperform / boost real, but an imagenet scale result has been elusive. Finally models are good enough that it works!.

12
101
595
n=22: "A very very very very very very very very very very very very very very very very very very very very very very beautiful painting of a mountain next to a waterfall."

9
54
532
This paper is so cool: It shows several kinds of illusions that I had never seen before (e.g., color inversion illusion). It's exciting to see more and more cases like this, where AI opens up new kinds of art, rather than only imitating old forms.
10
133
543
Wondering what to do in the era of GPT?. One answer: do science! There is still so much to understand about _why_ these models work (or don’t). Here’s my group’s lastest* on the science of deep learning, newly accepted in TMLR:.
6
73
524
I'm updating the "hacker's guide to deep learning" lecture for a course I'm teaching this semester ( -- what are your favorite ~2022 DL tips and tricks should I definitely include?.
16
75
525
Sharing two new preprints on the science and theory of contrastive learning:. pdf: code: w/ @YonglongT, Chen Sun, @poolio, @dilipkay, Cordelia Schmid. pdf: code: w/ @TongzhouWang. 1/n.
4
107
426
I give a lot of talks but often only a few people see them. I’m going to try a new experiment where I write blog versions of some of the talks I give. Here’s the first one: .A short, general-audience intro to "Generative Models of Images" -->

5
51
380
This only worked because we had a good hypothesis space (few params, contains true fn). Point is: if you have the right hypothesis space, you can extrapolate, correctly, far outside the training distribution!. 3/3.
20
9
353
GANs get a lot of press for making photorealistic images, but to me the more impressive and useful feat is that they discover this organized "latent space" that underlies the visual world. This video is a really nice intro to that concept and why it is so cool:.
4
63
358
I recently gave a talk on the platonic representation hypothesis at the Simons Institute, which is now online here: pdf of the slides for those interested, feel free to reuse:
3
55
345
More new work at ICCV: Training a GAN to explain a classifier. Idea: visualize how an image would have to change in order for the predicted class to change. Can reveal attributes and biases underlying deep net decisions. w/ big team @GoogleAI.—>
3
62
331
Surprising and fun result: Unpaired image translation without a deep net, just a _linear_ transformation: (and no GAN too!).
3
60
300
Now trying out parameterized natural language commands in ChatGPT. a bit like defining a function F(X;n) where n is a parameter. Here is the prompt:. 1/n

9
26
271
Should you train your vision system on real images or synthetic? . In the era of stable diffusion, the answer seems to be: synthetic! . One stable diffusion sample can be worth more than one real image. paper link:

New paper!! We show that pre-training language-image models *solely* on synthetic images from Stable Diffusion can outperform training on real images!!. Work done with @YonglongT (Google), Huiwen Chang (Google), @phillip_isola (MIT) and Lijie Fan (MIT)!!
8
46
245
n=6: "A very very very very very very beautiful painting of a mountain next to a waterfall."

1
13
210
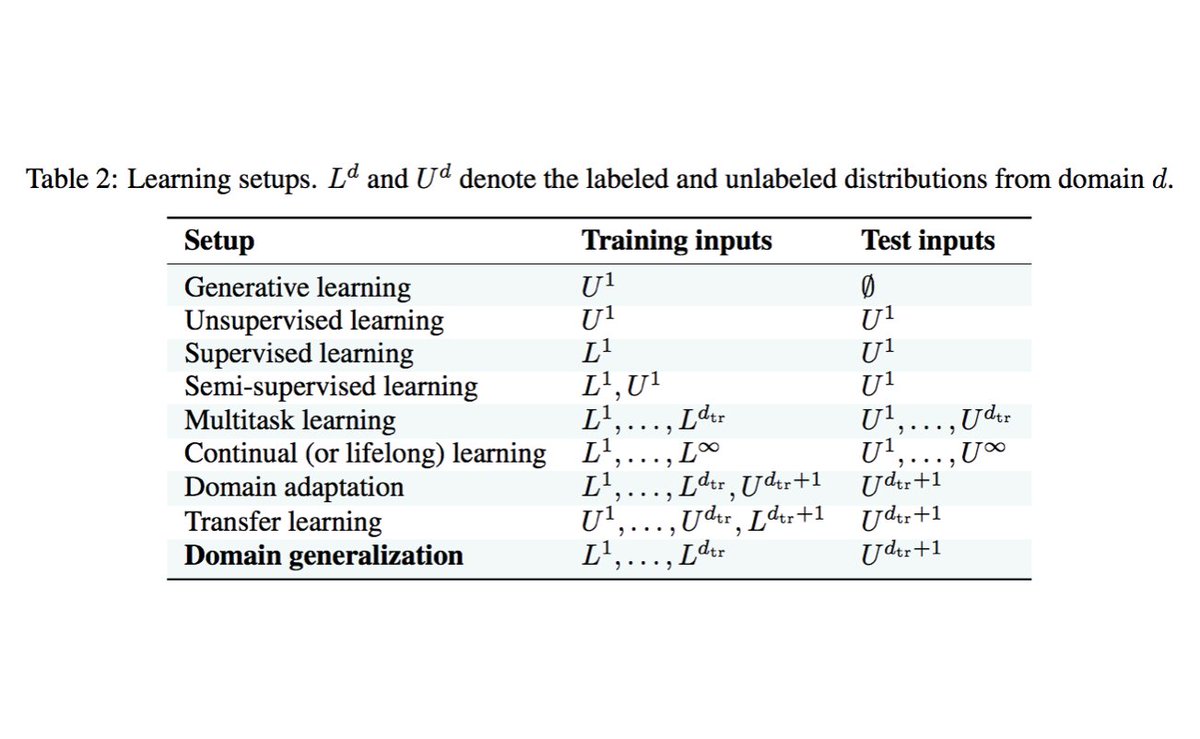
Beautiful summary of different learning problems from a new paper by @__ishaan and David Lopez-Paz . (rest of paper also looks interesting)
0
34
210
As a kid I was fascinated the Search for Extraterrestrial Intelligence, SETI. Now we live in an era when it's becoming meaningful to search for "extraterrestrial life" not just in our universe but in simulated universes as well. This project provides new tools toward that dream:.

Introducing ASAL: Automating the Search for Artificial Life with Foundation Models. Artificial Life (ALife) research holds key insights that can transform and accelerate progress in AI. By speeding up ALife discovery with AI, we accelerate our
4
18
213
How is that possible? . Because we aren't fitting over all possible mappings x-->y, we are only considering fits of the form y = a*sin(x^2) + b*x. This "hypothesis space" extrapolates in the way shown above. Since the true fn is in this space, the extrapolation is ~correct. 2/3.
21
8
193
New paper at #CoRL2023! "Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation". How should robots represent the world around them?. This paper's answer: as a field of foundation model features localized in 3D space. paper+code: 1/n
1
28
200
Very interesting work on a question I've been thinking a lot about: when can training a system on X' ~ G outperform training directly on X (where G is a gen model of X). They find that retrieving task-relevant images from X outperforms sampling task-relevant images from G. 1/n.

Will training on AI-generated synthetic data lead to the next frontier of vision models?🤔. Our new paper suggests NO—for now. Synthetic data doesn't magically enable generalization beyond the generator's original training set. 📜: Details below🧵(1/n).
6
23
201
What's cool about this, to me, is that BigGAN learned something that looks like 3D rotation, but it did so just by modeling 2D images:
9
27
189
Impressive results! This paper incorporates so many of my favorite things: representational convergence, GANs, cycle-consistency, unpaired translation, etc.

excited to finally share on arxiv what we've known for a while now:. All Embedding Models Learn The Same Thing. embeddings from different models are SO similar that we can map between them based on structure alone. without *any* paired data. feels like magic, but it's real:🧵.
2
12
194
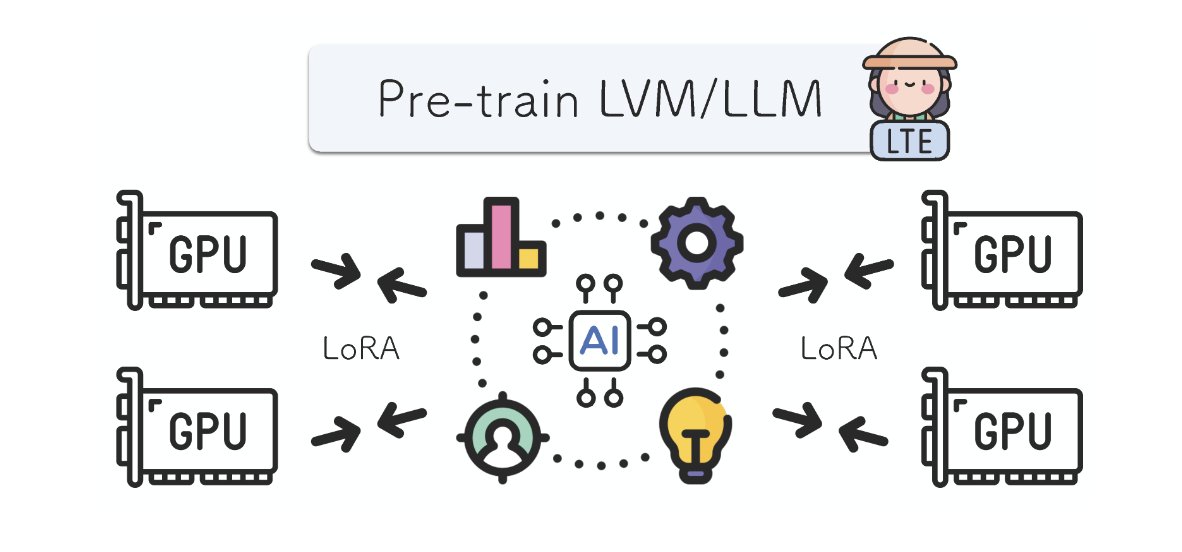
Distributed training using parallel LoRAs, infrequently synced. My fav part is the analogy to git, where lots of coders can work together on a project, coordinated by simple operators like pull, commit, merge. Potential implications toward community training of big models.


Presenting a method for training models from SCRATCH using LoRA: .💡20x reduction in communication .💡3x savings in memory. - Find out more: .- Code available to try out.- Scaling to larger models ongoing.- led by Jacob Huh!
6
24
186
A big dream in AI is to create world models of sufficient quality that you can train agents within them. Classic simulators lack visual diversity and realism. GenAI lacks physical accuarcy. But combining the two can work pretty well!. paper:

For roboticists, one challenge towers above the others: there isn’t enough data. To accelerate the deployment of intelligent robots in the real world, MIT CSAIL’s "LucidSim" uses genAI & physics engines to create diverse & realistic virtual training grounds for robots. W/o any
3
24
188
Jumping on the CLIP+VQGAN bandwagon:. "What is the answer to the ultimate question of life, the universe, and everything?" (using seed=42 of course)
4
23
183
At ICLR this week, we are presenting our work on learning contrastive representations from generative models: . w/ @Ali_Design_1 @xavierpuigf @YonglongT. 1/n.
4
24
180
Slides of the talk I gave today at the #iccv19 synthesis workshop, on "Generative Models as Data Visualization": (covers and .
3
44
164
Great to see GANs becoming competitive on text-to-image. GANs are still my favorite kind of generative model :).

StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis. significantly improves over previous GANs and outperforms distilled diffusion models in terms of sample quality and speed . abs: .project page:
3
17
154
If you’re interested in learning about the theory behind Muon (a new optimizer), Jeremy has a great explainer in this thread. Also check out all his work leading to this (modula, modular duality, etc): It’s a beautiful theory and seems to work too!.

It's been wild to see our work on Muon and the anthology start to get scaled up by the big labs. After @Kimi_Moonshot released Moonlight, people have asked whether Muon is compatible with muP. I wanted to write up an explainer, as there is something deeper going on here!. (1/8)

3
21
167
If you are interested in GANs, and around Boston on 5/31, please come check out this workshop we are organizing: Talks on theory and practice, arts and applications. Also accepting poster submissions here:

SAVE THE DATE! We’re co-hosting a GANs workshop @MIT on Friday 5/31 with @MITIBMLab. Tutorials, talks and posters on one of the hottest topics in AI.
6
37
158
n=1: "A very beautiful painting of a mountain next to a waterfall."

1
7
135
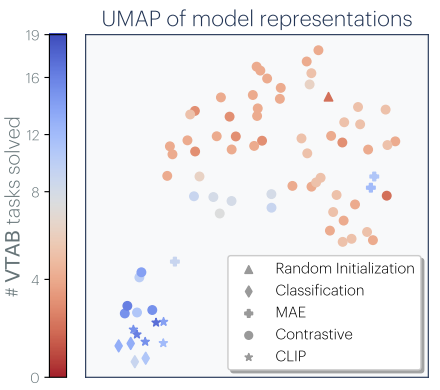
Why are reps converging? We suggest a few possibilities, including:. As we train on more tasks, there are fewer reps that can satisfy all, leading to an Anna Karenina scenario (: all strong models are alike, each weak model is weak in its own way. 3/8
2
9
137
In case anyone finds it useful to know my thoughts on the election, I support Kamala Harris. Why? For me it largely comes down to three values: freedom, truth, and competence. 1/n.
6
2
134
This post prompted some interesting reactions :) so let me quickly respond to a few:. 1. 'but you gave it the answer'.-- yes, partially, and that's the point, the hypothesis space gives it the _form_ of the answer.
A simple, fun example to refute the common story that ML can interpolate but not extrapolate:. Black dots are training points. Green curve is true data generating function. Blue curve is best fit. Notice how it correctly predicts far outside the training distribution!. 1/3
17
8
126
On my way to CVPR: Antonio, Bill, and I will be at the MIT Press booth on Thursday, 4-4:30pm. We will be happy to sign books if you want to bring yours!. We will also raffle away a few copies.
Our computer vision textbook is released!. Foundations of Computer Vision.with Antonio Torralba and Bill Freeman. It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields. 1/4
1
13
134
I like watching image models optimize because the optimization path reveals interesting visual connections. Here's an image being optimized toward “ocean”. First it makes clownfish, then seems to realize “oh those fish could be kayaks instead!” So clever and opportunistic.

0
11
134
It's hard to be surprised these days, but these results surprised me; it really _seems_ to have captured the compositional nature of our world; amazing work!.

0
7
127
One lens on synthetic data:. Often you have a bunch of mappings X-->Y, Y-->Z, etc and you want other mappings implied by these. A simple approach is to use the given mappings to sample training data for the implied mappings. 1/3.
3
10
129
Here's a tool that I think many may find useful: a *variable length* image tokenizer. 𝚕𝚎𝚗(𝚝𝚘𝚔𝚎𝚗𝚒𝚣𝚎(𝚒𝚖𝚊𝚐𝚎)) should depend on image complexity and task needs, and this tool supports both.

Current vision systems use fixed-length representations for all images. In contrast, human intelligence or LLMs (eg: OpenAI o1) adjust compute budgets based on the input. Since different images demand diff. processing & memory, how can we enable vision systems to be adaptive ? 🧵.
2
7
128
This looks like a fascinating report: It gives a name to a major paradigm shift that has occurred over the last few years in AI: "foundation models" are the big pretrained nets on top of which almost everything else will be made. I love the term.
3
10
126
Even wonder if all the fancy new contrastive objectives would be useful for regular old *supervised* learning? Turns out they can be!.
New paper on *Supervised Contrastive Learning*: A new loss function to train supervised deep networks, based on contrastive learning! Our new loss performs significantly better than cross-entropy across a range of architectures and data augmentations.

5
15
122
We survey evidence from the literature, then provide several *new* results including:. As LLMs get bigger and better, they learn representations that are more and more similar to those learned by vision models. And vice versa: strong visual reps are similar to LLM reps. 2/8

3
9
116
One of the most fun parts for me has been making visualizations. To give a sample, here are a few, showing 1) embeddings layer by layer in an MLP, 2) weight sharing in a CNN, 3) a diffusion model, 4) an image captioning system. 2/4

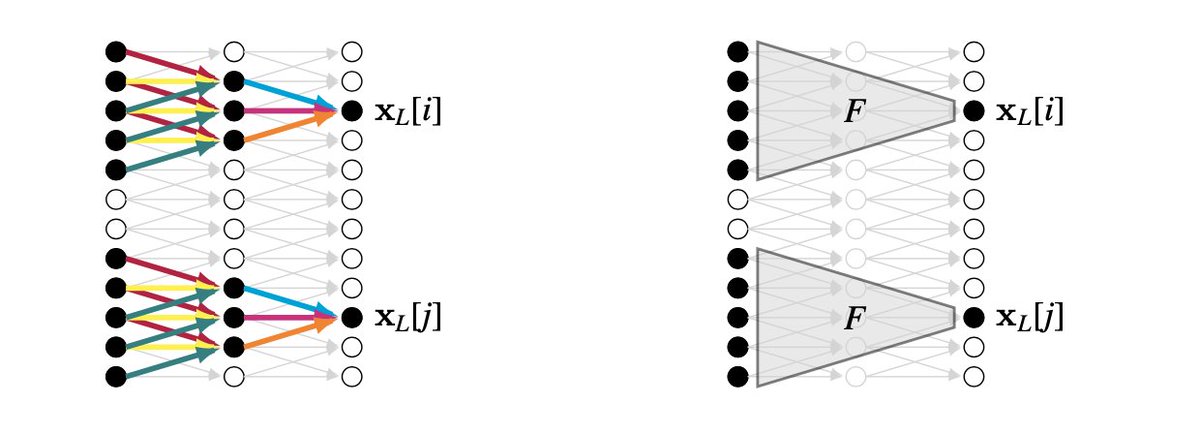


4
9
116
How much does #dalle know about 3D?. Let's see by asking it to render stereo pairs. "An anaglyph photo of a cute lego elephant."
5
13
113
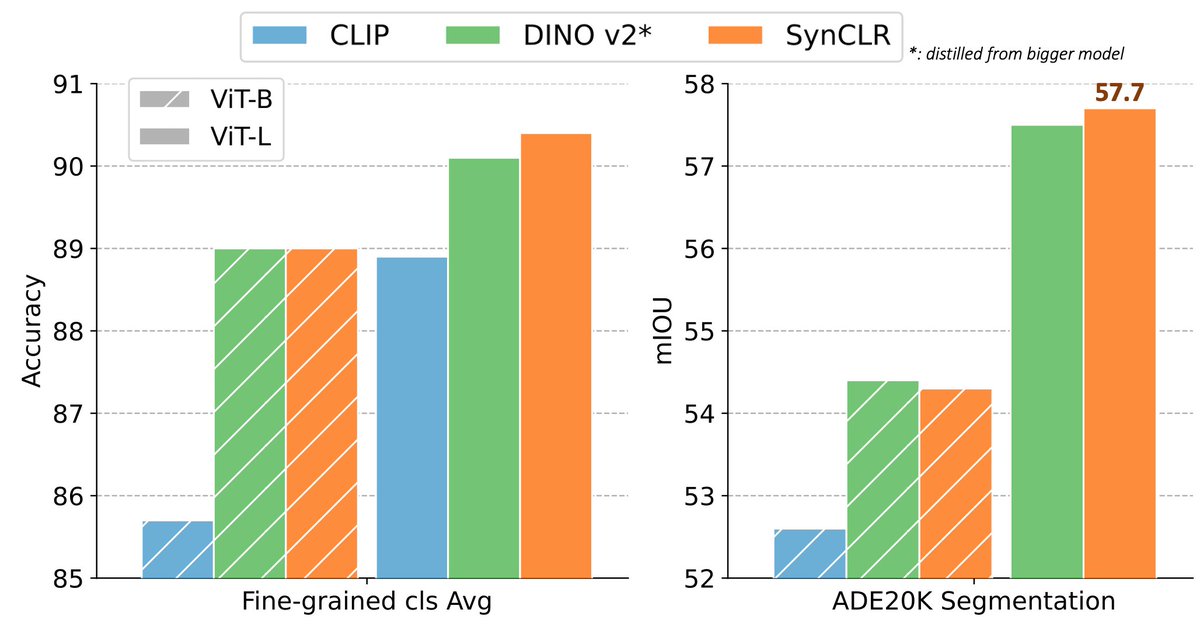
More of our work on learning vision from synthetic data from generative models. This time both the images and the text are synthetic!.

🚀 Is the future of vision models Synthetic? Introducing SynCLR: our new pipeline leveraging LLMs & Text-to-image models to train vision models with only synthetic data!.🔥 Outperforming SOTAs like DinoV2 & CLIP on real images! SynCLR excels in fine-grained classification &
1
12
112
A few more, this time between species. Dog-wolf, goldfinch-bunting, red panda-panda:
3
21
107
(1/2) New work!. Contrastive Multiview Coding.Paper+Code: Different views of the world capture different info, but important factors are shared. Learning to capture the shared info —> SOTA reps. Saturday @ ICML self-sup workshop.w/ @YonglongT + @dilipkay.
2
30
111
Tomorrow at ECCV, we are presenting “Totems: Physical Objects for Verifying Visual Integrity”. Remember totems from Inception? We tried to make something *a bit* like that in reality. website: paper: 1/n

3
17
107
Human imagination is compositional: e.g., you can picture the Notre Dame, on a grassy field, surrounded by oaks, . Turns out GANs can too, in their latent space! . We study to what extent GANs can compose parts, and provide some fun tools for doing so in the paper+code below:.

Excited to share our ICLR 2021 paper on image composition in GAN latent space! joint with @jswulff @phillip_isola . paper+code+colab: .it's interactive and super fun to play with :)
1
18
103
Nice to see more theory on this. Paraphrasing: the only way to correctly colorize pikachu yellow is to first implicitly recognize that you are looking at a picture of pikachu!.

Predicting What You Already Know Helps: Provable Self-Supervised Learning.We analyze how predicting parts of the input from other parts (missing patch, missing word, etc.) helps to learn a representation that linearly separates the downstream task. 1/2

2
10
95
How can we learn good visual reps from *environments*, rather than datasets?. Requires exploring env to collect data to train rep. We study this as adv game (curiosity) between an explorer and a contrastive learner. At ICCV! w/@du_yilun @gan_chuang.-->

0
8
88
"Google search" for generative models:. with all the gazillions of models being trained now, I think tools like this will become more and more essential -- very exciting work!.

Introducing Modelverse (, an online model sharing and search platform, with the mission to help everyone share, discover, and study deep generative models more easily. Please share your models on Modelverse today. [1/4]
0
7
92
great! now to finish translating the bard into the twitter-verse, let's turn it into emojis:. "*emojify* *shorten* *shorten* *shorten* *shorten* *shorten* *shorten* *simplify* [R&J prologue]". 5/n

1
1
92
Well-trained generative models are great but I also love the visual creativity of poorly optimized models. Sometimes the results are more interesting when the model is not quite doing what you told it to do:

5
5
89
Different generative models (not just CNNs) tend to all make similar mistakes, especially at the patch level. This means you can train a fake detector on one kind of fake and it generalizes decently well to detecting fakes from held out models too!. We analyze this ability here:.
Just released our new project on using small patches to classify and visualize where artifacts occur in synthetic facial images, joint with @davidbau, Ser-Nam Lim, @phillip_isola . code+paper available at:
1
12
90
Nonparametric image synthesis has gone out of fashion but this paper shows that it can still do amazing things when combined with deep nets to clean things up: Amazing how much results have improved in just the last 1.5 years:
1
37
84
I found this to be a really nice perspective for understanding recent DL optimizers. My favorite kind of science is when someone finds a unifying theory that makes knowledge simpler than it was before, and I think this in that category.
Laker and I wrote this anthology to show how if you disable the EMA in three of our best optimizers---Adam, Shampoo and Prodigy---then they are actually steepest descent methods under particular operator norms applied to layers. (1/3).
0
5
86
Work we did on visualizing memorability, using GANs!.
What makes some images stick in the mind while others fade? Ask a GAN. via @MIT #icccv2019 @phillip_isola @AudeOliva @alexjandonian @L_Goetschalckx.
1
9
78
My favorite thing here is we are not just supervising our way to this result by imitating artist examples. Rather good sketches emerge, in part, as a consequence of what may be the _objective_ of line drawings: to communicate geometry and meaning. Demo:

Our new work (with fun demo!) on making better line drawing by making them informative, as assessed by a neural network's ability to infer depth and semantics. With Caroline Chan and @phillip_isola

3
9
80
Giving tutorial talk today on image-to-image translation. 9am at CVRP deep content creation tutorial: Slides here:
1
5
78
Imagine having a personalized library of functions like this written in natural language. I wonder how far you can take it. Can you parameterize the functions ("shorten by X%"), can you define loops ("repeat X times"), . I guess people will find! (or probably already have!).
5
1
76
Are game engines world simulators? . Given a mesh+texture, a game can render a beautiful depiction of tree bark. But, typically, it doesn't model how the bark came to be in the first place, how the mesh+texture were created. Gen models, in a sense, do. 1/3.
5
7
71
What are we converging to?. We hypothesize that there is an endpoint to all this convergence: a representation of the joint distribution over the underlying events that cause our observations. 4/8.
3
4
73
@docmilanfar I agree this is one mode for success. But I think you can also be successful in other modes. I think my own career, which has had some success, is more often in the mode of jumping around from topic to topic.
1
1
71
Revisiting this idea with GPT-4!. Prompt:."When I type “eli[N,M] X”, please explain X like I’m age N, using M references to movies. Respond with one sentence.". Now maybe it can help us all understand how GPT-4 works. 🧵.
Now trying out parameterized natural language commands in ChatGPT. a bit like defining a function F(X;n) where n is a parameter. Here is the prompt:. 1/n
5
7
71
Super cool results on generative representation learning; thought-provoking about generative versus contrastive. Generative tries to model all info, which may make it less efficient, but perhaps sufficient in the end:.

Transformers trained to predict pixels generate plausible completions of images and learn excellent unsupervised image representations!. To compensate for their lack of 2d prior knowledge, they are more expensive to train.
0
5
69
can't end on a negative one, so let's try to max this out:. *peppify[infinity]* It's Saturday and I have to do laundry.

4
2
66
In particular, in an specific idealized world, we show that contrastive learners converge to a representation whose kernel is the pointwise mutual information function over the underlying events. On a simple color domain, this empirically holds. 5/8

2
3
64
The field changed a lot while writing this. Here is our graph of progress. (I joined in the middle and my first contribution was to slow things down. ). But it's been fun to try to connect the old and the new. So many concepts reappear in each era, a spiral of progress. 3/4

2
3
67
However there are many immediate objections to consider:.* what about information that is _unique_ to one modality?.* what about special-purpose systems that do not require general world knowledge?.* are we measuring rep similarity in the right way?. There’s lots more to do!. 7/8.
3
1
59
This is very intriguing, suggestive that of the underlying sameness of so many problems. Reminds me of the Feynman quote: "Nature uses only the longest threads to weave her patterns, so each small piece of her fabric reveals the organization of the entire tapestry.".

What are the limits to the generalization of large pretrained transformer models?. We find minimal fine-tuning (~0.1% of params) performs as well as training from scratch on a completely new modality!. with @_kevinlu, @adityagrover_, @pabbeel.paper: 1/8.
1
8
58
I think we are in for a very interesting future of creative expression. To me, these tools do change things. Something is lost and something is gained. I really enjoyed making this, but also feel the pain that certain parts of this creative process are no longer uniquely human.
3
3
56
@RRKRahul96 perhaps but I think similar principles help explain the extrapolation properties of modern neural nets. CNNs and transformers extrapolate in part due to the extreme constraints they place on the hypothesis space.
6
5
54
Really cool new high-res + editable version of #pix2pix from nvidia and my colleague @junyanz89:
2
12
55
7
1
55
Really thought-provoking work! In determining what makes a good representation, it might be the journey that matters not the destination.

Excited to share our position paper on the Fractured Entangled Representation (FER) Hypothesis!. We hypothesize that the standard paradigm of training networks today — while producing impressive benchmark results — is still failing to create a well-organized internal.
3
5
55
Thanks to everyone who helped with this book!. Please send us errors and corrections if you find them. More will eventually be made available online. 4/4.
4
2
53
New work to appear at NeurIPS:. How can we get agents to communicate meaningfully with each other?. Simple idea: just have them broadcast compressed reps of their obs. Makes decentralized coordination much easier!. --> w/ @ToruO_O J Huh C Stauffer S Lim

2
6
52
Super cool new paper/framework from @jxbz Tim Large et al. (in which I had a small role). Enables tuning lr on small model, then using same value on big model. Hopefully helps eliminate wasteful lr sweeps on big models.
New paper and pip package:.modula: "Scalable Optimization in the Modular Norm". 📦 📝 We re-wrote the @pytorch module tree so that training automatically scales across width and depth.

0
7
50
This is beautiful, and more so when you think about all the technologies that interact to make this possible:.

I scaled up CLIPDraw ( a bit. "a beautiful epic wondrous fantasy painting of [the ocean / lightning / wind / a deep valley]":




0
6
47
The last sections of our paper explore implications and counterarguments. If there is indeed a platonic representation, then we should keep working to find it. We can marshal all kinds of data and architectures to this cause, rather than proceeding in disciplinary silos. 6/8.
1
1
45
We are presenting a few papers at NeurIPS this week. I’ll be at the posters and would be great to see folks there!. Details follow:. [1/n].
1
7
47
Fun test to see if you are living in a dream (adapted from Solaris):.- Pick a problem you can't mentally solve, but can check e.g., prime factorization.- Solve with a computer.- Mentally check.- If checks out, then you are not in a dream! (at least not one produced by your mind).
5
4
47
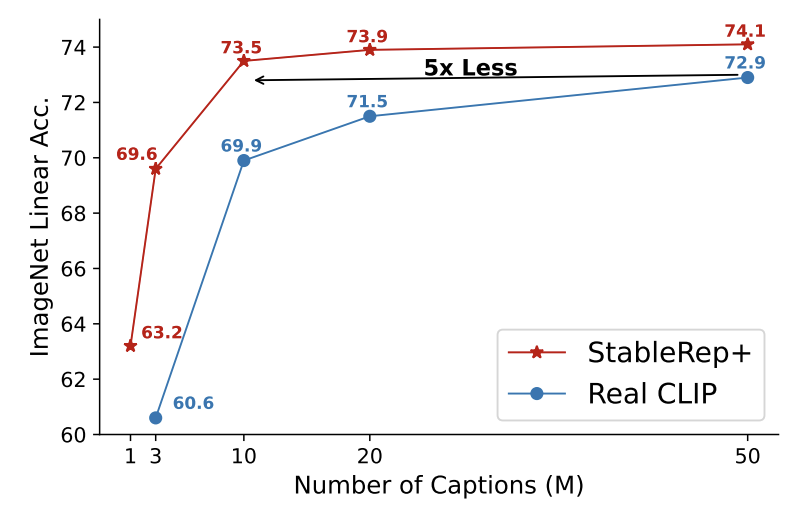
Re StableRep (, getting questions like: "isn't this because SD is trained on bigger data (LAION+CLIP)?". Yes, but I think it's more than that. In (Tab. 2) we equated training data and still found big boost from synthetic over real:

1
7
46
These are beautiful. It's interesting how the objects seem have their own unique style, a bit distinct from other CLIP/NeRF styles. I'd like to play a video game rendered in this style.
Zero-Shot Text-Guided Object Generation with Dream Fields.abs: project page: combine neural rendering with multi-modal image and text representations to synthesize diverse 3D objects solely from natural language descriptions
0
6
46


