
Yonglong Tian
@YonglongT
Followers
3K
Following
317
Media
5
Statuses
93
Research Scientist @OpenAI. Prev RS@GoogleDeepMind, PhD@MIT. Opinions are my own.
Boston, MA
Joined June 2019
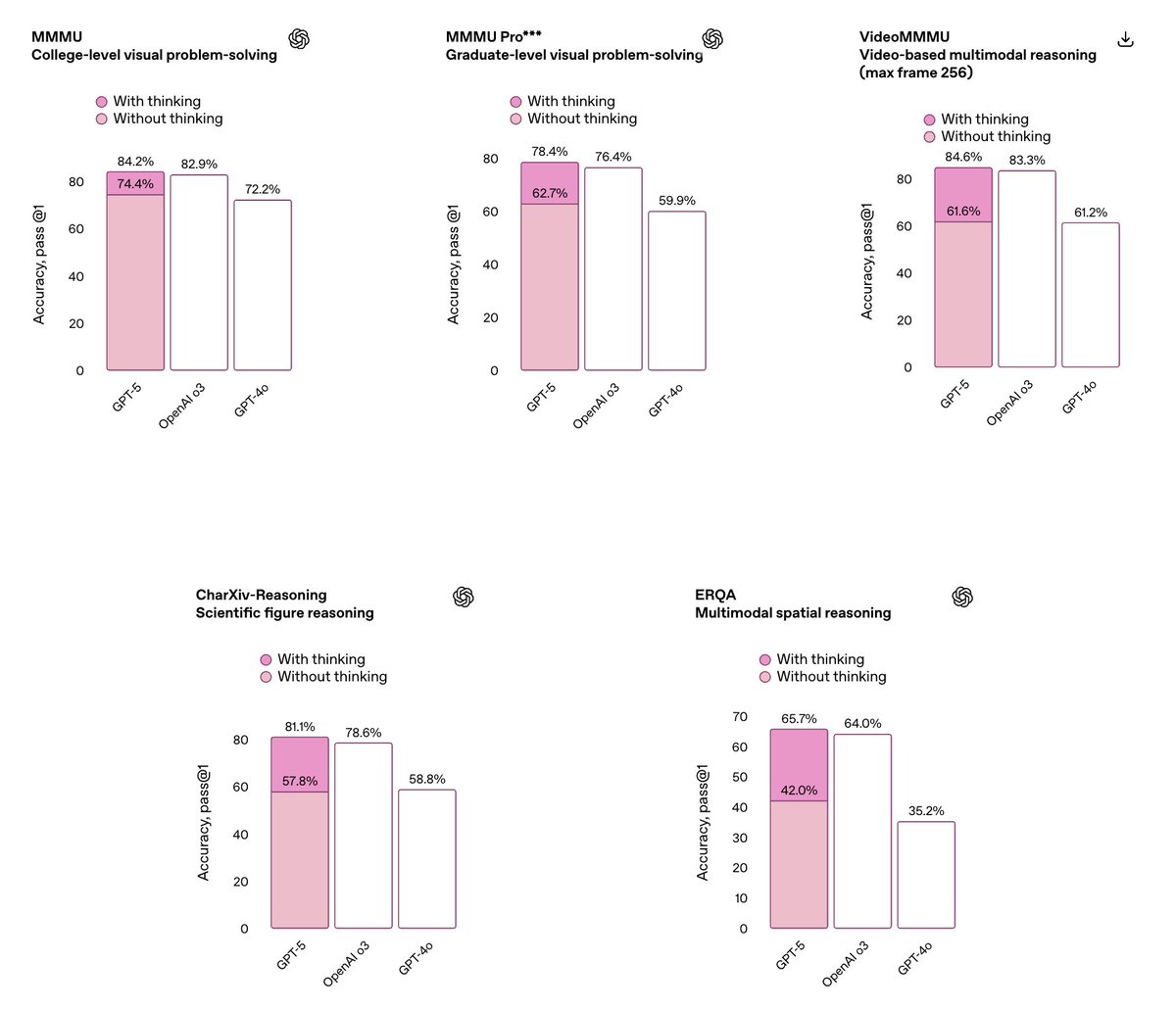
GPT-5 dropped! . For *multimodal*, the nice thing is it will use tools way more efficient than o3 (much better than the rendered acc numbers here), making it both better and faster. @jilin_14, efforts baked in.

2
6
43
RT @shobsund: Personal vision tasks–like detecting *your mug*-are hard; they’re data scarce and fine-grained. In our new paper, we show y….
0
62
0

RT @lijie_fan: 🚀 Excited to share our latest work Fluid!. We've developed a scalable autoregressive text-to-image model without VQ. We trai….
0
22
0
We name our Fluid model from 150M upto 10B! Surprisingly, Fluid with only 300M achieves similar FID as prior model with billions of parameters, e.g. Parti-20B. Joint work with @lijie_fan, @TianhongLi6, Siyang Qin, Yuanzhen Li, @jesu9, @MikiRubinstein, @DeqingSun, and Kaiming He.
2
1
21
Do we still need codebook/quantization for scalable autoregressive visual generation?. No! Thrilled to share our latest work on scaling w/ continuous tokens. We observe power-law scaling behavior on val loss, and obtain SOTA coco FID and GenEval score.


6
46
279
RT @JiaweiYang118: Very excited to get this out: “DVT: Denoising Vision Transformers”. We've identified and combated those annoying positio….
0
82
0
RT @phillip_isola: Our computer vision textbook is released!. Foundations of Computer Vision.with Antonio Torralba and Bill Freeman.https:/….
0
407
0
Thank you @_akhaliq for featuring our work!.

Denoising Vision Transformers. paper page: identify crucial artifacts in ViTs caused by positional embeddings and propose a two-stage approach to remove these artifacts, which significantly improves the feature quality of different pre-trained ViTs

0
6
41
HNY! Excited to share SynCLR, that rivals CLIP and Dino v2 but uses pure synthetic data. The interesting part - it can outperform models (e.g. CLIP) directly trained on LAION-2B, which was the dataset used to train SD 1.5 that we used to generate images.

5
42
281
RT @lijie_fan: 🚀 Is the future of vision models Synthetic? Introducing SynCLR: our new pipeline leveraging LLMs & Text-to-image models to t….
0
41
0
I had the joy of working with Olivier (and Aaron) at DeepMind. My best internship experience. Strongly recommended!.

Thrilled to announce that we have an opening for a Student Researcher to come work with us at @GoogleDeepMind!. If you’re interested in multimodal learning, in-context adaptation, memory-augmented perception, or active learning, do consider applying:
0
0
6
Thank you @_akhaliq for covering our work!.
Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency. paper page: Current vision-language generative models rely on expansive corpora of paired image-text data to attain optimal performance and generalization capabilities.

0
4
29
RT @TongzhouWang: Quasimetric RL code is now on GitHub: Instead of deleting 80% of the dev repo, I rewrote the alg….

github.com
Open source code for paper "Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning" ICML 2023 - quasimetric-learning/quasimetric-rl
0
25
0
RT @sangnie: Join us at the WiML Un-Workshop breakout session on "Role of Mentorship and Networking"! Do not miss the chance to talk with l….
0
22
0
RT @Jing36645824: 🎉(1/6) Exciting News:🐑LAMM is online!. ⭐️Features:.① 200k 2D/3D Instruction tuning dataset.② Benchmark on 14 high-level 2….
0
2
0
Our new work led by elegant @xuyilun2 , Mingyang and Xiang.

In diffusion models, samplers are primarily ODE-centric, overlooking slower stochastic methods. However, we show that stochastic sampler can outperform previous samplers on Stable Diffusion, if we use stochasticity correctly!. check out Restart Sampling:
0
1
12
MIT is a place for serious research.


0
2
49
RT @dilipkay: New paper!! We show that pre-training language-image models *solely* on synthetic images from Stable Diffusion can outperform….
0
112
0
Today marks the official ending of my PhD life at MIT. So grateful to this journey. Coincidentally, we arXiv a paper today: It shows the potential of learning from synthetic data. This coincidence nicely concludes my PhD life in an academic manner.


0
0
6
Today marks the official ending of my PhD life at MIT. So grateful to this journey. Coincidentally, we arXiv a paper today: It shows the potential of learning from synthetic data. This coincidence nicely concludes my PhD life in an academic manner.
23
20
318