
Lijie Fan
@lijie_fan
Followers
257
Following
6
Media
2
Statuses
9
Research Scientist @GoogleDeepMind. CS PhD @MIT
Cambridge, MA
Joined June 2023
🚀 Excited to share our latest work Fluid!. We've developed a scalable autoregressive text-to-image model without VQ. We trained the model up to 10B parameters, achieving state-of-the-art COCO FID and GenEval scores. 🔥.Check it out: 🙏 Shout out to



2
22
107
RT @TianhongLi6: Check out our latest VQ-free text-to-image model, Fluid! At last, an autoregressive model can generate the face of the Mon….
0
1
0

RT @YonglongT: Do we still need codebook/quantization for scalable autoregressive visual generation?. No! Thrilled to share our latest work….
0
46
0
RT @YonglongT: HNY! Excited to share SynCLR, that rivals CLIP and Dino v2 but uses pure synthetic data. The interesting part - it can outp….
0
42
0
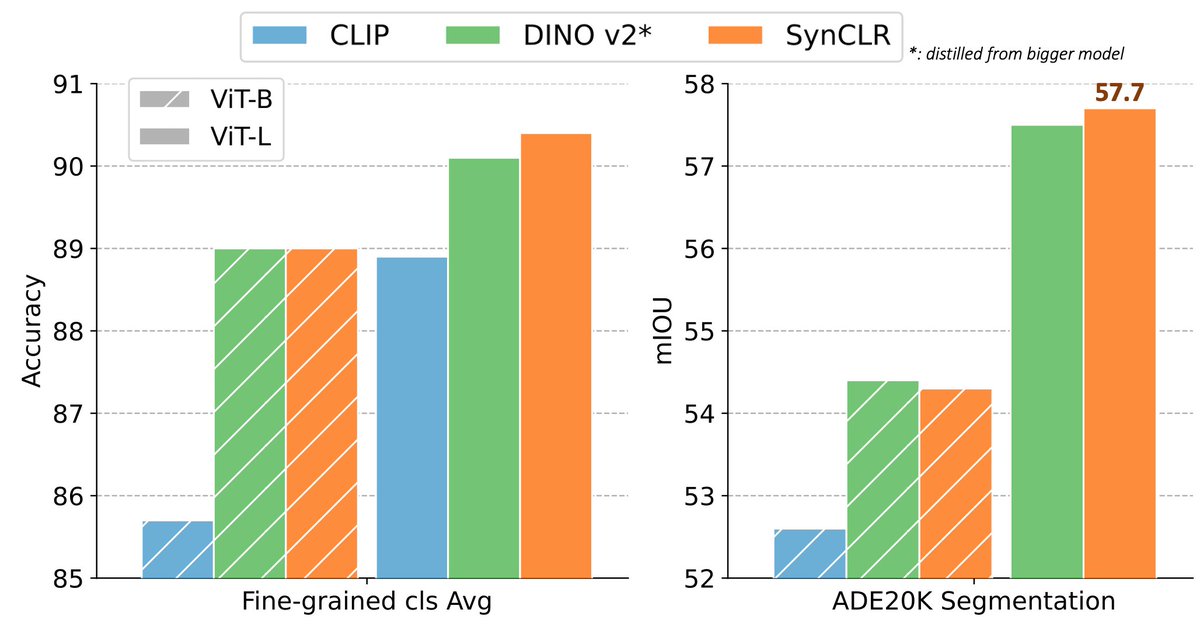
🚀 Is the future of vision models Synthetic? Introducing SynCLR: our new pipeline leveraging LLMs & Text-to-image models to train vision models with only synthetic data!.🔥 Outperforming SOTAs like DinoV2 & CLIP on real images! SynCLR excels in fine-grained classification &
3
41
189
RT @_akhaliq: StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners. paper page: .
0
26
0
RT @phillip_isola: Should you train your vision system on real images or synthetic? . In the era of stable diffusion, the answer seems to b….

arxiv.org
We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural question in the light of the excellent performance of...
0
47
0
RT @_akhaliq: Improving CLIP Training with Language Rewrites. introduce Language augmented CLIP (LaCLIP), a simple yet highly effective app….
0
36
0
RT @dilipkay: New paper! We show how to leverage pre-trained LLMs (ChatGPT, Bard, LLaMa) to rewrite captions, and significantly improve ove….
0
29
0