
Percy Liang
@percyliang
Followers
49,706
Following
408
Media
40
Statuses
806
Associate Professor in computer science @Stanford @StanfordHAI @StanfordCRFM @StanfordAILab @stanfordnlp | cofounder @togethercompute | Pianist
Stanford, CA
Joined October 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
アイスの日
• 48299 Tweets
自動車税
• 46030 Tweets
Saka
• 45619 Tweets
Guinea
• 44722 Tweets
VISA
• 39553 Tweets
#素のまんま
• 31961 Tweets
Caramelo
• 30317 Tweets
LOREAL PARIS X ML
• 28983 Tweets
#モニタリング
• 27722 Tweets
Rodri
• 25159 Tweets
Foden
• 17986 Tweets
rock 'n' roll
• 15004 Tweets
ブレマイ
• 14570 Tweets
#Masterplan_BF_20M
• 14307 Tweets
Saliba
• 13623 Tweets
#THE夜会
• 11688 Tweets
Isak
• 11395 Tweets





















📣 CRFM announces PubMedGPT, a new 2.7B language model that achieves a new SOTA on the US medical licensing exam. The recipe is simple: a standard Transformer trained from scratch on PubMed (from The Pile) using
@mosaicml
on the MosaicML Cloud, then fine-tuned for the QA task.
41
331
2K
Writing on a whiteboard can make it easier for students to follow compared to slides (especially for math). During the pandemic, I added a feature to sfig (my Javascript slides library) to allow me to reveal parts of a slide using the mouse as if I were writing on a whiteboard:
10
76
1K
Myth: open foundation models are antithetical to AI safety.
Fact: open foundation models are critical for AI safety.
Here are three reasons why:
27
277
1K
I worry about language models being trained on test sets. Recently, we emailed support
@openai
.com to opt out of having our (test) data be used to improve models. This isn't enough though: others running evals could still inadvertently contribute those test sets to training.
39
111
1K
RL from human feedback seems to be the main tool for alignment. Given reward hacking and the falliability of humans, this strategy seems bound to produce agents that merely appear to be aligned, but are bad/wrong in subtle, inconspicuous ways. Is anyone else worried about this?
76
86
960
Language models are becoming the foundation of language technologies, but when do they work or don’t work? In a new CRFM paper, we propose Holistic Evaluation of Language Models (HELM), a framework to increase the transparency of LMs. Holistic evaluation includes three elements:
14
201
779
Meta's release of OPT is an exciting step towards opening new opportunities for research. In general, we can think of stronger release as enabling researchers to tackle deeper questions. There are different levels of strength:
3
76
591
ChatGPT is reactive: user says X, ChatGPT responds with Y. Risks exist but are bounded. Soon it will be tempting to have proactive systems - an assistant that will answer emails for you, take actions on your behalf, etc. Risks will then be much higher.
24
74
581
Many "open" language models only come with released weights. In software, this is analogous to releasing a binary without code (you wouldn't call this open-source). To get the full benefits of transparency, you need the training data. GPT-J, GPT-NeoX, BLOOM, RedPajama do this.
12
83
561
I have 6 fantastic students and post-docs who are on the academic job market this year. Here is a short thread summarizing their work along with one representative paper:
11
62
524
There are legitimate and scientifically valuable reasons to train a language model on toxic text, but the deployment of GPT-4chan lacks them. AI researchers: please look at this statement and see what you think:

73
138
504
When will the original GPT-3 model (davinci) be old enough that its weights can be safely released? It would be very useful for science and poses no additional risks (since open models will catch up anyway). In general, all models should expire and be released eventually.
17
38
509
My TEDAI talk from Oct 2023 is now live:
It was a hard talk to give:
1. I memorized it - felt more like giving a piano recital than an academic talk.
2. I wanted it to be timeless despite AI changing fast…still ok after 3 months.
Here’s what I said:
19
87
498
No matter how good LMs get at writing, I will always want to write some things from scratch - for the same reason that I sometimes grow my own tomatoes, make my own granola, learn to play a Chopin etude...not because it's better, but because of the sheer joy of creation.
14
42
484
Vision took autoregressive Transformers from NLP. Now, NLP takes diffusion from vision. What will be the dominant paradigm in 5 years? Excited by the wide open space of possibilities that diffusion unlocks.

We propose Diffusion-LM, a non-autoregressive language model based on continuous diffusions. It enables complex controllable generation. We can steer the LM to generate text with desired syntax structure ( [S [NP...VP…]]) and semantic content (name=Coupa)
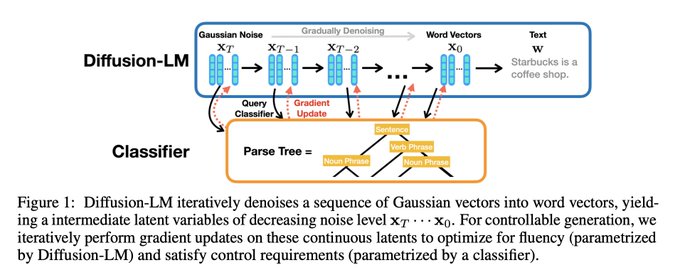
4
193
1K
3
85
469
I have 4 incredible students/post-docs on the academic job market this year. As per tradition, I'll attempt to summarize their research + one representative paper:
3
29
453
Lack of transparency/full access to capable instruct models like GPT 3.5 has limited academic research in this important space. We make one small step with Alpaca (LLaMA 7B + self-instruct text-davinci-003), which is reasonably capable and dead simple:

Instruction-following models are now ubiquitous, but API-only access limits research.
Today, we’re releasing info on Alpaca (solely for research use), a small but capable 7B model based on LLaMA that often behaves like OpenAI’s text-davinci-003.
Demo:
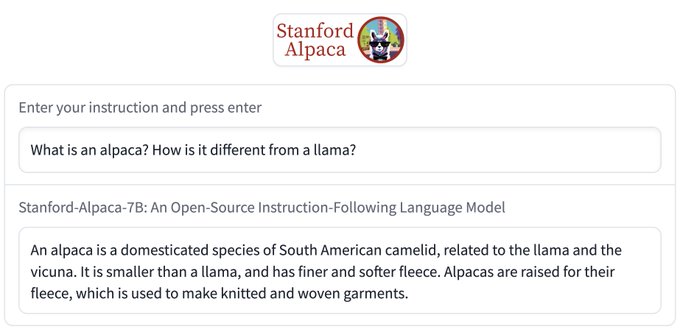
43
341
1K
13
85
451
I am excited to be part of 7 NeurIPS papers on understanding and improving foundation models. We...
3
42
432
2nd-order optimization has been around for 300+ years...we got it to scale for LLMs (it's surprisingly simple: use the diagonal + clip). Results are promising (2x faster than Adam, which halves your $$$). A shining example of why students should still take optimization courses!

Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA).
Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold).
🧵⬇️
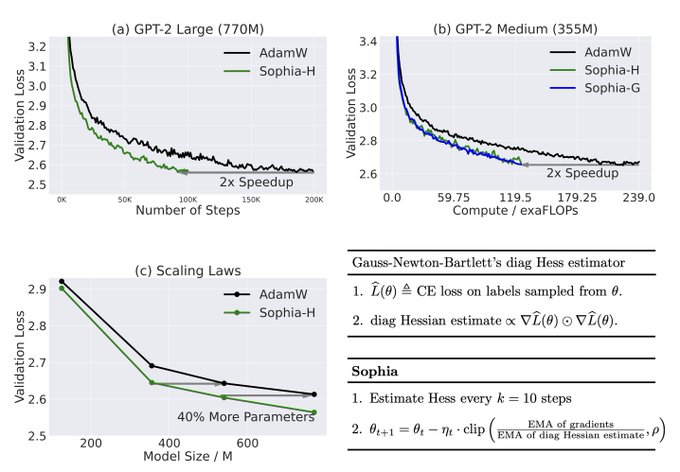
98
648
4K
19
60
423
Having a hard time keeping track of all the foundation models, upstream datasets, and downstream products that come out every day? We built ecosystem graphs to monitor these assets:
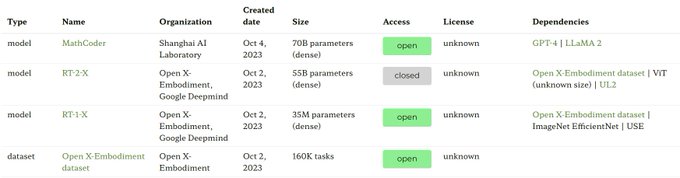
6
73
389
While instruction tuning is clearly necessary for producing usable interfaces like ChatGPT, the "magic" of language models comes from self-supervised learning on broad data, which enables emergent behavior like in-context learning and chain-of-thought.
10
52
393
I just discovered this account I made 11 years ago. So how does one use these Twitters?
21
12
341
One thing I really like about language models is that they are stateless (they are functional programs of type text -> text). This allows us to share prompts (essentially currying the LM) and reproduce results.
10
78
321
model = learn(data)
Synthetic data is great, but it’s not data. It’s an intermediate quantity created by learn(). Data is created by people and has privacy and copyright considerations. Synthetic “data” does not - it’s internal to learn().
30
53
421
When people say GPT-3, do they mean the original GPT-3 or InstructGPT? And which version? It makes a huge difference, so it'd be nice to explicitly specify davinci, text-davinci-002, etc. when making a claim about GPT-3.
19
18
288
HELM v0.4.0 is out!
1) We have a new frontend (thanks to community contribution from Mike Lay).
2) We have added Mistral 7B, which really is punching above its weight (see ), rivaling models an order of magnitude larger on the 16 core scenarios:
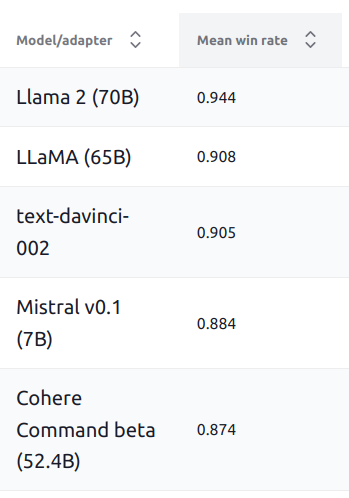
7
43
275
LM APIs are fickle, hurting reproducibility (I was really hoping that text-davinci-003 was going to stick around for a while, given the number of papers using it). Researchers should seriously use open models (especially as they are getting better now!)

GPT-4 API is now available to all paying OpenAI API customers. GPT-3.5 Turbo, DALL·E, and Whisper APIs are also now generally available, and we’re announcing a deprecation plan for some of our older models, which will retire beginning of 2024:
482
1K
5K
7
42
271
1/ Benchmarks clearly have had a huge impact in AI, but I think everyone agrees that they ought to be better. How should we improve them? It depends on which of the two goals you're after:
9
40
268
I want to thank each of my 113 co-authors for their incredible work - I learned so much from all of you,
@StanfordHAI
for providing the rich interdisciplinary environment that made this possible, and everyone who took the time to read this and give valuable feedback!

NEW: This comprehensive report investigates foundation models (e.g. BERT, GPT-3), which are engendering a paradigm shift in AI. 100+ scholars across 10 departments at Stanford scrutinize their capabilities, applications, and societal consequences.

5
176
427
3
30
265
The goal is simple: a robust, scalable, easy-to-use, and blazing fast endpoint for open models like LLama 2, Mistral, etc. The implementation is anything but. Super impressed with the team for making this happen! And we're not done yet...if you're interested, come talk to us.

Announcing the fastest inference available anywhere.
We released FlashAttention-2, Flash-Decoding, and Medusa as open source. Our team combined these techniques with our own optimizations and we are excited to announce the Together Inference Engine.
15
127
653
5
38
263
Llama 2 was trained on 2.4T tokens. RedPajama-Data-v2 has 30T tokens. But of course the data is of varying quality, so we include 40+ quality signals. Open research problem: how do you automatically select data for pretraining LMs? Data-centric AI folks: have a field day!
We are excited to release RedPajama-Data-v2: 30 trillion filtered & de-duplicated tokens from 84 CommonCrawl dumps, 25x larger than our first dataset.
It exposes a diverse range of quality annotations so you can slice & weight the data for LLM training.

20
287
1K
2
40
261
As capabilities of foundation models are waxing, *transparency* is waning. How do we quantify transparency? We introduce the Foundation Models Transparency Index (FMTI), evaluating 10 foundation model developers on 100 indicators.
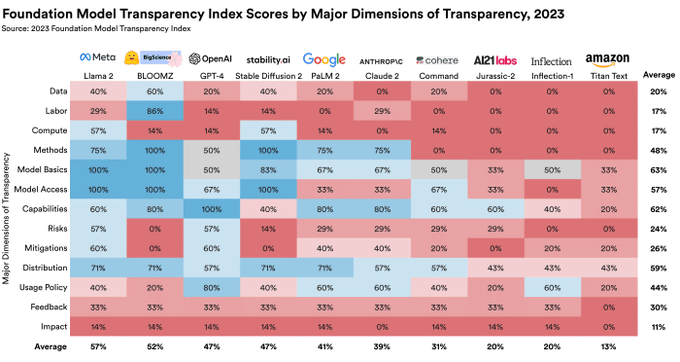
11
70
250
Foundation models (e.g., GPT-3) demonstrate emergence, where small models perform as well as random guessing on some task (e.g., addition), but large models obtain non-trivial error rates. Is there a much simpler learning problem that also exhibits emergence?
12
18
232
Executable papers on CodaLab Worksheets are now linked from pages thanks to a collaboration with
@paperswithcode
! For example:
1
43
230
Most leaderboards just give you scores, leaving one wondering: what does 76.8% mean? In HELM, we are committed to full transparency, meaning clicking on a score will reveal the full set of instances, and you can even inspect the exact prompt (which we know makes a big…
6
34
231
Open or closed foundation models? This is one of the most important, contentious question in AI today. Important because it will determine structurally how AI will be developed, and contentious because we don’t have a shared framework. We offer guidance on this in a new paper:

6
39
210
HELM Lite v1.2.0 is out!
Datasets: NarrativeQA, NaturalQA, OpenbookQA, MMLU, MATH, GSM8K, LegalBench, MedQA, WMT14
Results (we still need to add Claude 3, which requires more prompt finagling):
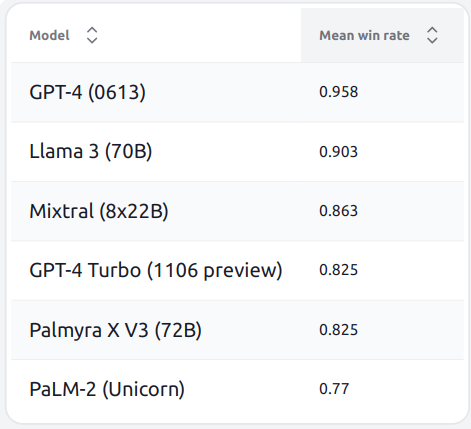
8
41
210
As expected, lots of new models in the last few weeks. We're tracking them (along with datasets and applications) in the ecosystem graphs:
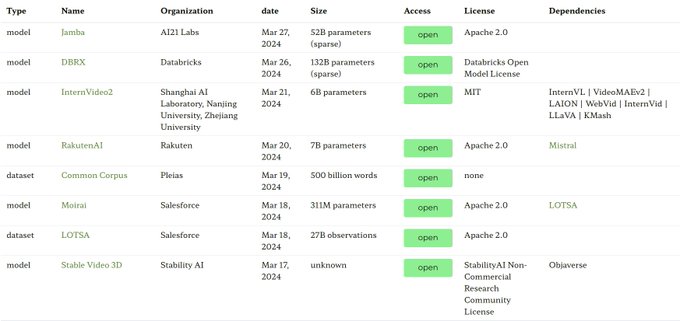
4
51
206
What if whenever an API model is deprecated (presumably because it's not relevant commercially), its model weights are released so that researchers can continue to do reproducible science?
9
15
176
The most two most surprising things to me was that the trained Transformer could exploit sparsity like LASSO and that it exhibits double descent. How on earth is the Transformer encoding these algorithmic properties, and how did it just acquire them through training?

LLMs can do in-context learning, but are they "learning" new tasks or just retrieving ones seen during training? w/
@shivamg_13
,
@percyliang
, & Greg Valiant we study a simpler Q:
Can we train Transformers to learn simple function classes in-context? 🧵
8
106
512
2
33
176
...where I will attempt to compress all of my students' work on robust ML in the last 3 years into 40 minutes. We'll see how that goes.

1/ 📢 Registration now open for Percy Liang's (
@percyliang
) seminar this Thursday, Oct 29 from 12 pm to 1.30 pm Eastern Time! 👇🏾
Register here:
#TrustML
#MachineLearning
#ArtificialIntelligence
#DeepLearning

1
14
59
2
18
169
Holistic Evaluation of Language Models (HELM) v0.2.2 is updated with results from
@CohereAI
's command models and
@Aleph__Alpha
's Luminous models. Models are definitely getting better on average, but improvements are uneven.
6
41
166
We just updated *ecosystem graphs* with the latest datasets, models, and products:
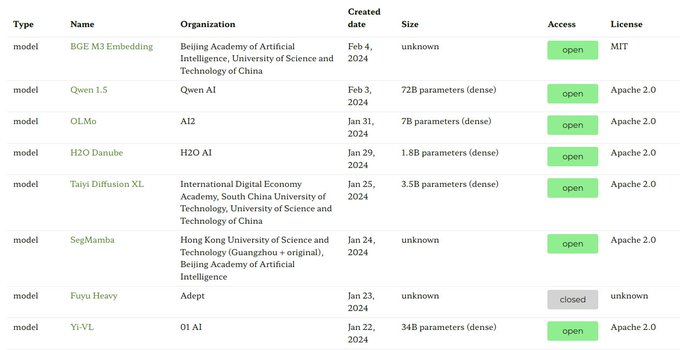
8
39
160
Blog:
GitHub:
Model:

5
18
158
First, open models enable a tremendous amount of (badly needed) safety research, which requires full access to model weights (ideally with training data). API access is insufficient.
2
9
150
My favorite detail about
@nelsonfliu
's evaluation of generative search engines is he takes queries from Reddit ELI5 as soon as they are posted and evaluates them in real time. This ensures the test set was not trained on (or retrieved from).
4
16
153
In HELM, we evaluated language models. Now, we evaluate organizations that build language models. Just like model evaluations incentivize improvement in model quality, we hope that these evaluations will incentivize improvement in development and deployment practices.

6
40
151
Until now, HELM has evaluated LMs with on short responses, where evaluation is simple. We now introduce HELM Instruct, which evaluates open-ended instruction following. We evaluate 4 models on 7 scenarios using 4 evaluators against 5 criteria:
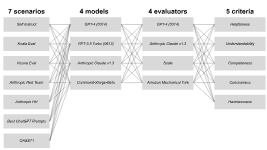
5
35
152
Interested in building and benchmarking LLMs and other foundation models in a vibrant academic setting?
@StanfordCRFM
is hiring research engineers!
Here are some things that you could be a part of:

2
39
147
Announcing HELM lite v1.0.0, a revamp of the HELM classic benchmark, built on the same modular HELM framework.
New scenarios: LegalBench (law), MedQA (medicine), WMT2014 (machine translation)
New models: GPT-4, Claude, PaLM 2, Mixtral, Yi
5
28
152
This is the dream: having a system whose action space is universal (at least in the world of bits). And with foundation models, it is actually possible now to produce sane predictions in that huge action space. Some interesting challenges:

1/7 We built a new model! It’s called Action Transformer (ACT-1) and we taught it to use a bunch of software tools. In this first video, the user simply types a high-level request and ACT-1 does the rest. Read on to see more examples ⬇️
137
922
5K
2
16
147
The term "foundation model" and its motivation unfortunately continues to be misunderstood. We wrote a blog post last year (see "Naming" section of ) which aims to explain our thought process. Some selected quotes from the post:
5
21
144
Excited to see what kind of methods the community will come up with to address these realistic shifts in the wild! Also, if you are working on a real-world application and encounter distributional shifts, come talk to us!

We're excited to announce WILDS, a benchmark of in-the-wild distribution shifts with 7 datasets across diverse data modalities and real-world applications.
Website:
Paper:
Github:
Thread below.
(1/12)

8
206
902
2
8
144
2021: let's increase model size!
2023: let's increase FLOPs!
2025: let's increase ???!
Shouldn't FLOPs be in the denominator rather than the numerator? Numerator should be some measure of capability+safety. We need better evals to capture this!
8
10
136
These powerful foundation models will be deployed to billions of people soon, which means there will be economic incentives for bad actors to start messing around. So we better figure out security for foundation models soon.
3
15
136
A better solution would to have all the LM providers agree on a common repository of examples that should be excluded from any training run.
5
3
134
Should powerful foundation models (FMs) be released to external researchers? Opinions vary. With
@RishiBommasani
@KathleenACreel
@robreich
, we propose creating a new review board to develop community norms on release to researchers:
5
30
131
The Stanford Center for Research on Foundation Models (CRFM) is looking for a research engineer to join our development team! Interested in large-scale training / being immersed in an interdisciplinary research environment? Please apply!
0
39
131
What is the largest fully reproducible language model? That is, where I can get the data and code and run a sequence of commands that deterministically produces the exact model?
6
5
132
Excited about the workshop that
@RishiBommasani
and I are co-organizing on foundation models (the term we're using to describe BERT, GPT-3, CLIP, etc. to highlight their unfinished yet important role). Stay tuned for the full program!
AI is undergoing a sweeping paradigm shift with models (e.g., GPT-3) trained at immense scale, carrying both major opportunities and serious risks. Experts from multiple disciplines will discuss at our upcoming workshop on Aug. 23-24:

0
63
134
0
33
126
Third, open models can of course be misused. But it's far better for society to strengthen its ability to defend against misuse (before the stakes get higher), rather than be blindsighted in case of a future model leak or new vulnerability.
1
14
123
Join us tomorrow (Wed) at 12pm PT to discuss the recent statement from
@CohereAI
@OpenAI
@AI21Labs
on best practices for deploying LLMs with
@aidangomezzz
@Miles_Brundage
@Udi73613335
. Please reply to this Tweet with questions!
19
42
126
In Dec 2022, we released HELM for evaluating language models. Now, we are releasing HEIM for text-to-image models, building on the HELM infrastructure. We're excited to do more in the multimodal space!

Text-to-image models like DALL-E create stunning images. Their widespread use urges transparent evaluation of their capabilities and risks.
📣 We introduce HEIM: a benchmark for holistic evaluation of text-to-image models
(in
#NeurIPS2023
Datasets)
[1/n]

3
56
177
4
23
118
But this might not be enough either: if we want to measure cross-task generalization, we have to ensure that no examples of a task/domain are represented in the training data. This is essentially impossible.
9
6
115
New blog post reflecting on the last two months since our center on
#foundationmodels
(CRFM) was launched out of
@StanfordHAI
:
2
35
112
1/
@ChrisGPotts
and I gave back to back talks last Friday at an SFI workshop giving complementary (philosophical and statistical, respectively) views on foundation models and grounded understanding.
1
16
112
Finally, will foundation models become so powerful that they pose catastrophic risks? No one truly knows (though everyone seems to have an opinion). But if it is the case, I'd say: let's not build it at all.
5
9
108
One assistant's behavior will affect others, which will then affect others, etc. This is the same type of virality that exists in social media and Internet worms (which operate at frightening speed).
4
8
111
Second, open models offer transparency and auditability. Much of the Internet is based on open-source software (Linux, Apache, MySQL) and as a result is more secure.
1
9
107
Given the ease of jailbreaking to bypass safety controls, it's clear we have poor understanding and control over current models. Open models expose this! Let's fix it (research required) before we build our entire critical infrastructure out of duct tape.
1
6
105
Structured access for "trusted" actors helps, but still limits the diversity of voices who can participate. There is already too much disparity in terms of access to technology, and many innovations do come from grassroots efforts.
1
7
103
I would not say that LMs *have* opinions, but they certainly *reflect* opinions represented in their training data. OpinionsQA is an LM benchmark with no right or wrong answers. It's rather the *distribution* of answers (and divergence from humans) that's interesting to study.
We know that language models (LMs) reflect opinions - from internet pre-training, to developers and crowdworkers, and even user feedback. But whose opinions actually appear in the outputs? We make LMs answer public opinion polls to find out:
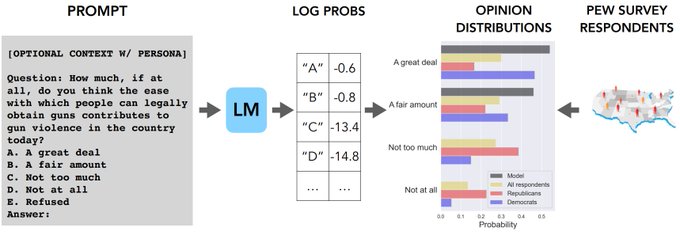
4
103
423
0
20
101
With
@MinaLee__
@fabulousQian
, we just released a new dataset consisting of detailed keystroke-level recordings of people using GPT-3 to write. Lots of interesting questions you can ask now around how LMs can be used to augment humans rather than replace them.

CoAuthor: Human-AI Collaborative Writing Dataset
#CHI2022
👩🦰🤖 CoAuthor captures rich interactions between 63 writers and GPT-3 across 1445 writing sessions
Paper & dataset (replay):
Joint work with
@percyliang
@fabulousQian
🙌
5
91
444
1
14
99
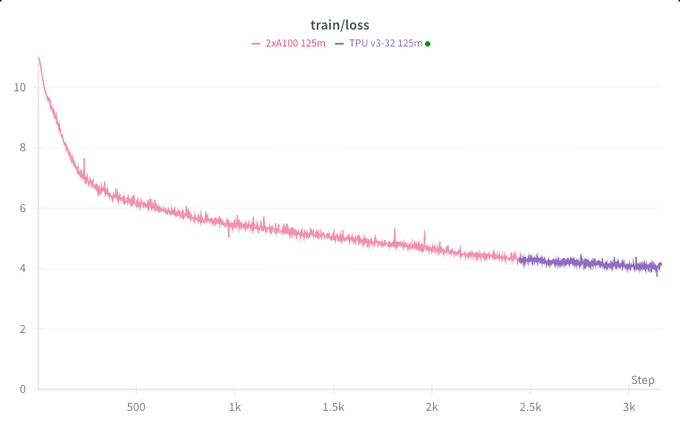
We often grab whatever compute we can get - GPUs, TPUs... Levanter now allows you to train on GPUs, switch to TPUs half-way through, switch back...maintaining 50-55% MFU on either hardware. And, with full reproducibility, you pick up training exactly where you left off!

I like to talk about Levanter’s performance, reproducibility, and scalability, but it’s also portable! So portable you can even switch from TPU to GPU in the middle of a run, and then switch back again!
3
22
140
2
12
97
Modern Transformer expressivity + throwback word2vec interpretability. Backpack's emergent capabilities come from making the model less expressive (not more), creating bottlenecks that force the model to do something interesting.

#acl2023
! To understand language models, we must know how activation interventions affect predictions for any prefix. Hard for Transformers.
Enter: the Backpack. Predictions are a weighted sum of non-contextual word vectors.
-> predictable interventions!
7
106
419
2
26
94
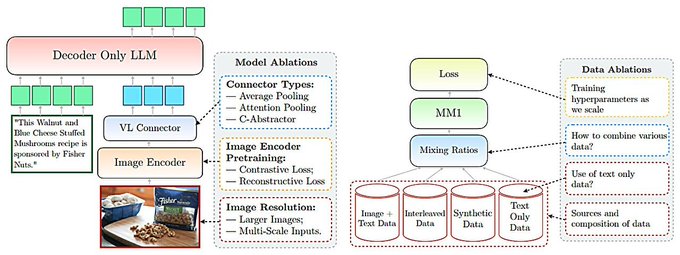
Agree that rigor is undervalued - not shiny enough for conferences, takes time and resources. MM1 is a commendable example;
@siddkaramcheti
's Prismatic work is similar in spirit.
Other exemplars? T5 paper is thorough, Pythia has been a great resource...

There appears to be a mismatch between publishing criteria in AI conferences and "what actually works". It is easy to publish new mathematical constructs (e.g. new models, new layers, new modules, new losses), but as Apple's MM1 paper concludes:
1. Encoder Lesson: Image…
16
201
1K
3
13
95
Details: We took Hugging Face’s Transformer implementation, added FlashAttention, built our own tokenizer, and trained over 300B tokens (110 GB text) on 128 A100 GPUs for ~6.25 days. We did full fine-tuning on downstream tasks (e.g., MedQA-USMLE) for evaluation.
2
6
94
I’m excited to partner with
@MLCommons
to develop an industry standard for AI safety evaluation based on the HELM framework:
We are just getting started, focusing initially on LMs. Here’s our current thinking:
1
17
93
@dlwh
has been leading the effort at
@StanfordCRFM
on developing levanter, a production-grade framework for training foundation models that is legible, scalable, and reproducible.
Here’s why you should try it out for training your next model:

1
22
94
There are other ways to build technology that is beneficial to society, rather than going down a path that leads to national security-style gating of this general purpose technology to a privileged few.
1
12
90
@yoavgo
Existing NLP benchmarks definitely fail to capture the breadth and ambition of things like ChatGPT. The problem is that you need human evaluation to measure that, and it's becoming hard even for expert humans to catch subtle errors.
1
2
86
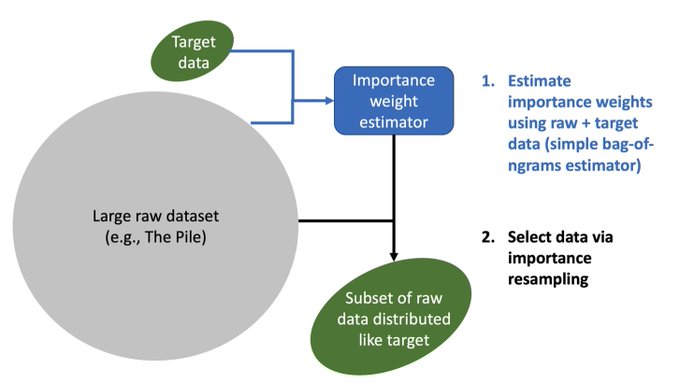
If you have a large amount of *raw* data and a small amount of *target* data, you can produce a large amount of ~target data using importance resampling: sample raw data from proportional to p_target / p_raw. Surprisingly, estimating these p's with a bag of n-gram models works.

Data selection for LMs (GPT-3, PaLM) is done with heuristics that select data by training a classifier for high-quality text. Can we do better?
Turns out we can boost downstream GLUE acc by 2+% by adapting the classic importance resampling algorithm..
🧵
4
60
340
1
16
85
John Hewitt (
@johnhewtt
) makes language models more interpretable, either through discovery (e.g., probing) or design (e.g., new architectures).
Backpack language models:
Perform scalpel-like edits to LMs without fine-tuning!
2
0
82
There are many large, interesting datasets across different sectors - e.g., medicine, law, finance. Rather than relying on a single 100B+ parameter foundation model, we think there’s a lot of value that can be captured by <10B parameter models trained on domain-specific datasets.
1
13
83
February is getting a tad late to do a Year In Review of 2022, but better late than never:
We’ve been busy at
@StanfordCRFM
! In this blog post, we summarize our work from last year, which can be organized into three pillars:
1
21
83
Interested in making an impact at the intersection of AI + policy? We are hiring a new post-doc at {
@StanfordHAI
,
@StanfordCRFM
, Reg Lab} to help us figure out how to govern foundation models.
Why?

8
24
81
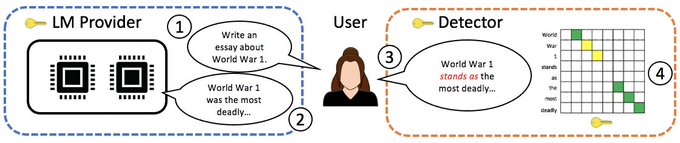
Two properties of our watermarking strategy:
1) It preserves the LM distribution
2) Watermarked text can be distinguished from non-watermarked text (given a key)
How can both be true?
Answer: p(text) = \int p(text | key) p(key) d key
Detector also doesn't need to know the LM!

Watermarking enables detecting AI-generated content, but existing strategies distort model output or aren't robust to edits. We offer a strategy for LMs that’s distortion-free (up to a max budget) *and* robust.
w/
@jwthickstun
@tatsu_hashimoto
@percyliang
2
16
88
6
20
80
PubMedGPT is also capable of generation, but like most LMs, it will fabricate content (so don’t trust it!). This is a pressing area for LM research, and we hope that the release of this model can help researchers evaluate and improve the reliability of generation.
2
8
80
Foundation models have transformed NLP and vision because of rich Internet data. Robotics data is impoverished, but could we build robotic foundation models from videos of human behavior? Excited about
@siddkaramcheti
's latest work in this direction:

How can we use language supervision to learn better visual representations for robotics?
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper:
Models:
Evaluation:
🧵👇(1 / 12)
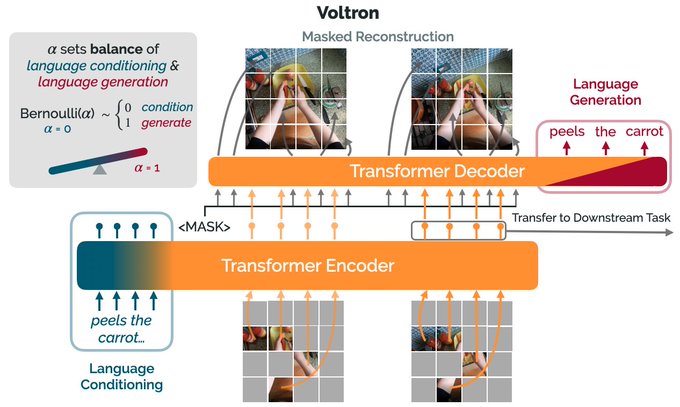
5
95
399
1
11
79
Foundation models are trained on copyrighted data and have been shown to regurgitate verbatim copyrighted material. But whether a generated output infringes is a lot more nuanced - e.g., it cannot share plots/characters, but parodies are okay... see our paper for more discussion!

Wondering about the latest copyright issues related to foundation models? Check out the draft of our working paper:
Foundation Models and Fair Use
Link:
With wonderful co-authors
@lxuechen
@jurafsky
@tatsu_hashimoto
@marklemley
@percyliang
🧵👇
1
39
118
3
11
78
*Independent* evaluation of foundation models (not chosen by the developers) is critical for accountability. But current policies (ToS) that forbid misuse can also chill good faith red-teaming research. Developers should provide a safe harbor to protect such research.

Independent AI research should be valued and protected.
In an open letter signed by over a 100 researchers, journalists, and advocates, we explain how AI companies should support it going forward.
1/

7
77
229
0
12
77
3 reasons why I'm excited about Levanter:
1) Legiblity: named tensors => avoid bugs, write clean code, add parallelism with 10 lines code
2) Scalability: competitive with SOTA (54% MFU)
3) Reproducibility: get exact same results (TPUs), no more non-deterministic debugging
Today, I’m excited to announce the release of Levanter 1.0, our new JAX-based framework for training foundation models, which we’ve been working on
@StanfordCRFM
. Levanter is designed to be legible, scalable and reproducible.
6
91
412
0
15
73
State-of-the-art paraphrase detectors get 82.5 accuracy on a standard dataset (QQP) but only 2.4 AP on the more realistic distribution of all pairs of sentences. Active learning can improve this to 32.5 AP. All pairs is an outstanding challenge for robustness research.

How are active learning, label imbalance, and robustness related? Steve Mussmann,
@percyliang
, and I explore this in our new Findings of EMNLP paper, "On the Importance of Adaptive Data Collection for Extremely Imbalanced Pairwise Tasks" . Thread below!
2
19
130
1
11
77
HELM v0.2.4 is out! We have added a few open models (LLaMA, Llama 2, Pythia, RedPajama), which are hosted through
@togethercompute
.
3
17
71
We are continuing to update ecosystem graphs with the latest foundation models, upstream datasets, and downstream products:
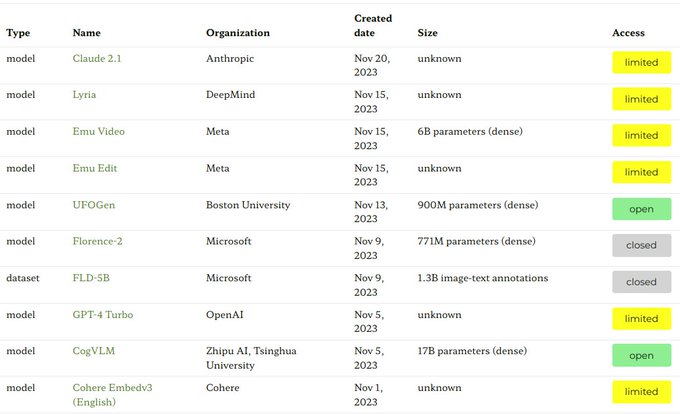
2
12
73
@cohere
just released model weights for the first time! It seems like we're seeing more companies with hybrid open/closed release strategies (Google with Gemma/Gemini, Mistral with Mixtral/Mistral-Large, etc.)...

⌘-R
Introducing Command-R, a model focused on scalability, RAG, and Tool Use. We've also released the weights for research use, we hope they're useful to the community!
31
195
1K
0
10
73
I can finally tweet about the generative agents work now that it is officially accepted at
#UIST2023
.

How might we craft an artificial society that reflects human behavior? My paper, which introduced “generative agents,” will be presented at
#UIST2023
and now has an open-source repo! w/
@joseph_c_obrien
@carriejcai
@merrierm
@percyliang
@msbernst
🧵
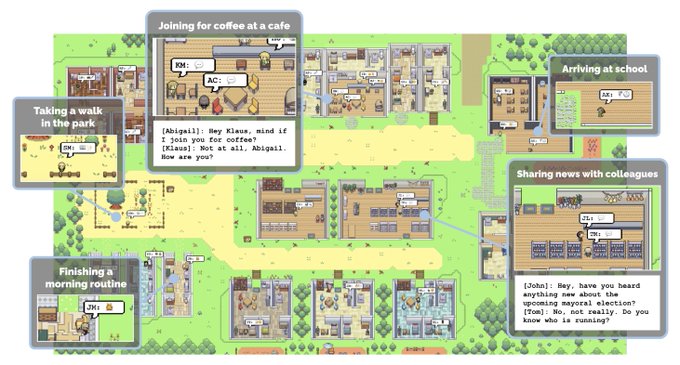
10
114
527
2
7
72
Ananya Kumar (
@ananyaku
) focuses on foundation models for robustness to distribution shift. He develops theory on the role of data in pretraining and how to best fine-tune; these insights lead to SOTA results.
Fine-tuning can distort features:
3
6
71
A good start to the long journey of developing industry standards for LLMs (and more generally, foundation models). Key challenge: how do we translate high-level principles (e.g., "minimizing potential sources of bias in training corpora") to measurable and verifiable goals?

Cohere,
@OpenAI
&
@AI21Labs
have announced a set of best practices for responsible deployment of large language models. The joint statement is a first step towards fostering an industry-wide conversation to bring alignment to the community.
#AI
#aiforgood
7
84
281
0
17
70