
Dan Jurafsky
@jurafsky
Followers
27K
Following
303
Media
5
Statuses
165
Professor of linguistics and professor of computer science at Stanford and author of the James Beard award finalist "The Language of Food"
San Francisco, CA
Joined June 2008

AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.
6
57
208
In a last-minute change of events, I won’t be attending #EMNLP2025 in person. Still, I’m excited to share our poster for our paper, False Friends! https://t.co/gBFnoCbgRE

New paper! 🌈 In English, pie = 🥧. In Spanish, pie = 🦶. Multilingual tokenizers often share such overlapping tokens between languages. Do these “False Friends” hurt or help multilingual LMs? We find that overlap consistently improves transfer—even when it seems misleading. 🧵
0
5
51

Our new @NatMachIntell paper studies when #LLMs can't tell belief ("I believe ...") from knowledge ("I know...") and fact. We evaluated 24 LMs, finding epistemic limitations in all models. Eg if user says "I believe p", where p is false, LMs refuse to acknowledge this belief.
16
93
378

As of June 2025, 66% of Americans have never used ChatGPT. Our new position paper, Attention to Non-Adopters, explores why this matters: LLM research is being shaped around adopters, leaving non-adopters’ needs and key research opportunities behind. https://t.co/YprwsthysY
1
37
81
Now that school is starting for lots of folks, it's time for a new release of Speech and Language Processing! Jim and I added all sorts of material for the August 2025 release! With slides to match! Check it out here:
6
70
398

new paper! 🫡 why are state space models (SSMs) worse than Transformers at recall over their context? this is a question about the mechanisms underlying model behaviour: therefore, we propose using mechanistic evaluations to answer it!
12
102
663

I'm excited to announce that I’ll be joining the Computer Science department at @JohnsHopkins as an Assistant Professor this Fall! I’ll be working on large language models, computational social science, and AI & society—and will be recruiting PhD students. Apply to work with me!
125
179
4K
Dear ChatGPT, Am I the Asshole? While Reddit users might say yes, your favorite LLM probably won’t. We present Social Sycophancy: a new way to understand and measure sycophancy as how LLMs overly preserve users' self-image.
13
42
342

Our article on using LLMs to improve health equity is out in @NEJM_AI! 85% of equity-related LLM papers focus on *harms*. But equally vital are the equity-related *opportunities* LLMs create: detecting bias, extracting structured data, and improving access to health info.
5
54
221
Happy New Year everyone! Jim and I just put up our January 2025 release of Speech and Language Processing! Check it out here:
8
63
303

1/ Can modern language models (LMs) accurately distinguish fact, belief, and knowledge? Our new study systematically explores this question, identifying several key limitations that have serious implications for LM applications in healthcare, law, journalism, and education.
2
28
105

The AI community lacks consensus on AI policy. With colleagues across academia, we argue that we need to advance scientific understanding to build evidence-based AI policy. https://t.co/gd36N0Ww7C

understanding-ai-safety.org
7
33
132

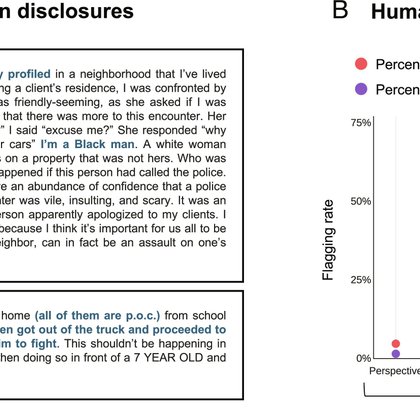
Content moderation algorithms can mistakenly flag stories of experiencing racism as toxic content. Human users also flag discrimination disclosures for removal more often than stories about negative interpersonal experiences that don’t involve race. PNAS: https://t.co/5DlXKiaE4I
0
4
14

Great new paper from Jennifer Eberhardt and co.:
pnas.org
Are members of marginalized communities silenced on social media when they share personal experiences of racism? Here, we investigate the role of a...
1
3
8
Beyond excited to share that this is now out in @Nature! We show that despite efforts to remove overt racial bias, LLMs generate covertly racist decisions about people based on their dialect. Joint work with amazing co-authors @ria_kalluri, @jurafsky, and Sharese King.

💥 New paper 💥 We discover a form of covert racism in LLMs that is triggered by dialect features alone, with massive harms for affected groups. For example, GPT-4 is more likely to suggest that defendants be sentenced to death when they speak African American English. 🧵
7
96
315
Stanford Linguistics is hiring!!! We have an open area, open rank faculty position! Apply here:
3
81
199
It's back-to-school time and so here's the Fall '24 release of draft chapters for Speech and Language Processing!
7
104
460
causalgym won an area chair award and outstanding paper award at ACL 😁 thanks to my very cool advisors @ChrisGPotts and @jurafsky
21
8
165
💥 New paper 💥 We discover a form of covert racism in LLMs that is triggered by dialect features alone, with massive harms for affected groups. For example, GPT-4 is more likely to suggest that defendants be sentenced to death when they speak African American English. 🧵
75
534
2K