

Keunwoo Choi
@keunwoochoi
Followers
5,638
Following
807
Media
383
Statuses
4,154
AI x {LLM Engineer @PrescientDesign @genentech , Advisor @gaudiolab }. music, audio, language, AI. Prev: @BytedanceTalk , @spotify , @c4dm @qmul .
New York, NY
Joined June 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
England
• 204965 Tweets
Corinthians
• 153544 Tweets
#BBCDebate
• 95233 Tweets
Mimi
• 64213 Tweets
#loveIsland
• 59250 Tweets
Saka
• 52694 Tweets
Southgate
• 40967 Tweets
#KızılcıkŞerbeti
• 35668 Tweets
Palmer
• 34121 Tweets
Iceland
• 32094 Tweets
Fatih
• 32066 Tweets
Penny Mordaunt
• 29319 Tweets
Gordon
• 28684 Tweets
Mainoo
• 28415 Tweets
#summergamefest
• 27558 Tweets
Rayner
• 24818 Tweets
Daylight
• 24694 Tweets
Foden
• 23440 Tweets
Kane
• 22662 Tweets
Cenk
• 20539 Tweets
Zverev
• 19954 Tweets
Trent
• 19527 Tweets
Inglaterra
• 17420 Tweets
Stephen Flynn
• 17038 Tweets
Bafana Bafana
• 12836 Tweets
Super Eagles
• 11656 Tweets
Semih
• 11091 Tweets
Geoff
• 10730 Tweets
Harriet
• 10177 Tweets




















Pinned Tweet

hi music people, i wrote a tutorial on large language models and music information retrieval. of course it's called..
LLMs <3 MIR
🥁 have fun!
0
24
176
whoa, this is bigger than ChatGPT to me.
google almost solved music generation, i'd say.
152
1K
6K

One of the key models in MusicLM is SoundStream, an audio codec. It made vocoders obsolete; and reshaped audio generation as a token prediction task.
SS is not open to public, but a similar neural audio codec Encodec is completely open-source →

7
48
400
I won the best paper award in
#ismir2017
!!! Feeling honoured!!!! Thanks for co-authors
@markbsandler
György Fazekas
@kchonyc

21
20
263
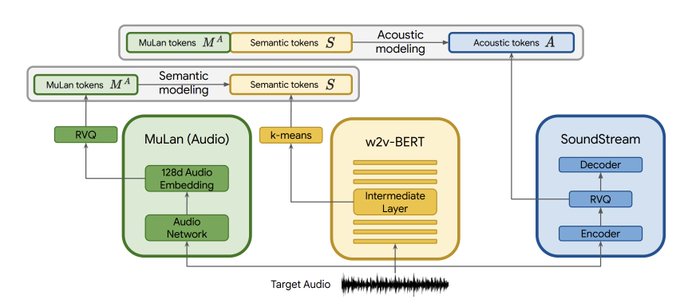
really well done, from SoundStream and AudioLM through MuLan to MusicLM 👏👏
the overall structure of MusicLM
= MuLan + AudioLM
= MuLan + w2v-BERT + SoundStream
2
21
252
Animated attention by
@kchonyc
which took his good 3hrs
@facebookai
@PyTorch
#torched
#deeplearning
#nlp
#attention
#seq2seq
#kyunghyuncho
#nyu
#cds
3
12
195
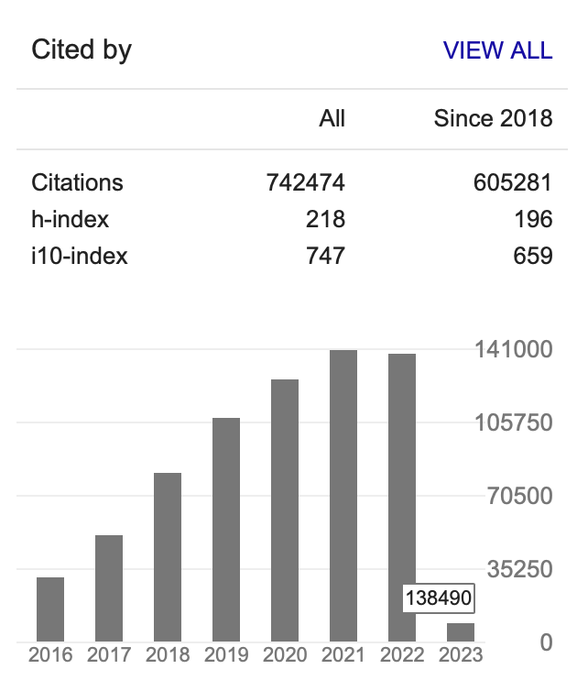
hi all, here's an academic proof that AI has peaked in 2021 and started to downturn by 1.346% in 2022.
diff = np.log(np.exp((1 - 138490 / 140380)))

17
8
136
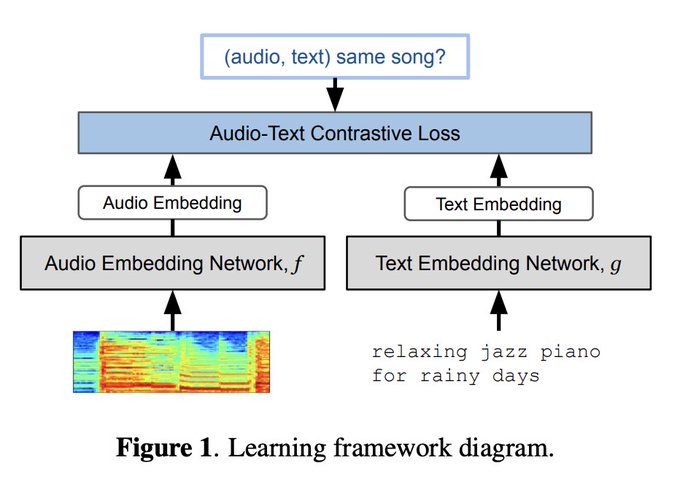
MuLan is a text-music joint embedding model.
- contrastive training
- 44M music audio - text description pairs from "internet music videos" *cough cough* youtube *cough cough*
- AST: audio spectrogram transformer
5
11
135
Last Friday was my last day of the two years at Spotify.
I started to work at ByteDance AI Research from today.
(At Mountain View (California) in principle, but joined remotely from NYC)
12
0
123
I left ByteDance last Friday. It was such a 1.8 year ❤️ (base-12)
I'm glad I got what I wanted - a novel and intense learning experience. I shipped quite a few stuff, worked on research back-end tools, and made some research impact.
Now, time to move on :)
5
2
117
🌱 We’re hiring 2024 summer research interns on LLMs for drug discovery and biomedical applications. Join me,
@stephenrra
,
@kchonyc
, and other amazing people at NYC to work on the LLM product development of
@PrescientDesign
,
@genentech
✨
Details:
0
21
115
🥳 PROPOSAL: Foley Sound Synthesis Challenge 🥳
There are enough challenges out there for speech and music. We propose one for "the other" kind of audio -> sound. Or effects. Or, Foley.
We need to define the problem, dataset, and eval scheme. How? 🧵🧶

9
19
105
I summarized the difference between `tokenizers.Tokenizer`, `transformers.PreTrainedTokenizer`, and `transformers.PreTrainedTokenizerFast`. I even made a github repo just to post this.

1
18
101

Ahem, ahem.
:
I joined Gaudio Lab to - i'd dare say - pioneer some audio/music AI! 🥳
I'm excited more than ever :D
Oh, and I'll visit Seoul more often. Friends in 🇰🇷, catch up soon!

5
2
99
All you need is AI and music -- I'm giving a guest lecture today at NYU, Center for Data Science. Stay tuned for the recording and slides :)

6
6
99
+ they released MusicCaps dataset (5521 music-text pair) which they used as an eval set.
.

6
7
94
THIS IS BIG! All the music folks in Google Deepmind focus on one thing: AI music generation while NOT exploiting artists. Nothing is perfect, there're probably still some holes in giving the credit, but this is better than anything ever for very sure.

Thrilled to share
#Lyria
, the world's most sophisticated AI music generation system. From just a text prompt Lyria produces compelling music & vocals. Also: building new Music AI tools for artists to amplify creativity in partnership w/YT & music industry
111
537
3K
2
8
93
New AI music model alert! yes, again 🎉
#SingSong
, another music generation model by Google;
@chrisdonahuey
et al.
Ok let me do another run for collecting followers. How does it work?
1
11
90
the “llama moment” has come to audio research today! i can’t even imagine what we’ll see out of AudioCraft.
whatever you work on in music/audio, do consider using it, as much as you can. if you don’t know what to do, think what you can do with it and get a head start.

Today we're sharing details on AudioCraft, a new family of generative AI models built for generating high-quality, realistic audio & music from text. AudioCraft is a single code base that works for music, sound, compression & generation — all in the same place.
More details ⬇️
40
535
2K
4
11
92
"All you need is AI and music" by Keunwoo Choi, 2021-12-08; A guest lecture at New York University - at
@kchonyc
's class. Now you can watch it :)

4
17
91
If you belong to an underrepresented group in any sense (gender, race, nationality, financial situation, etc) and need some help on any MIR issues, please just contact me. gnuchoi at the-email-starting-with-G-you-know-what-I-mean😉
4
12
88
My
#NeurIPS2018
summary from music x ML (=music information retrieval (=MIR)) perspective is here:

3
29
85
Hi all, I'm happy to twit-announce that I'm joining 🎧 Spotify NYC from June! 😀
13
7
83
for
#icassp2024
attendees, i'm open sourcing my `What to eat around COEX` list. originally written for
@cwu307
but sharing it for a large crowd and make the world better place, reduce p(doom), etc.

2
14
81
Hi people!
Me and
@kchonyc
's
#ismir2019
paper, "Deep Unsupervised Drum Transcription" aka 🥁 DrummerNet is here.
Paper -->
Blog post -->
Supplementary material -->

2
18
79
📄+📄+📄+📄+📄+📄+📄= 7 papers
🔥MIR researchers at ByteDance (SAMI team) made 7 papers accepted to
#ISMIR2021
🔥
🧵I'll introduce them here one by one :)👇
1
6
79
to recap, i find the whole roadmap really, really brilliant.
- because there's MuLan, they could use audio-only dataset.
- because there's SoundStream, the music generation task was simplified to token generation, not waveform generation.
3
3
78

i'm teaching a class about AI at NYU, Spring 2024. it's "Deep Learning for Media", a course about AI for audio and visual contents.
oof, i thought i became an LLM person.
(it's not a job change, i'm covering one class this semester)
happy to find back a nyu dot edu account!
5
2
69
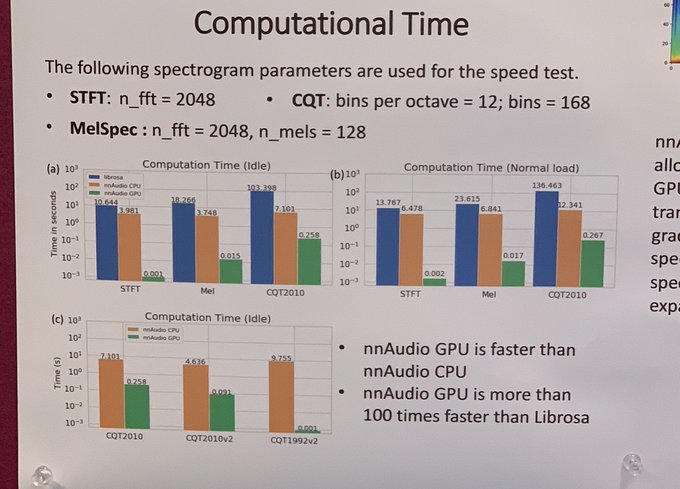
Ok now (restrospectively, on high-level) it's kinda simple.
given an training item:
- extract MuLan tokens (M), extract w2v-BERT (S), SS tokens (A)
- train model for M → S.
- train model for [M;S] → A
both done by decoder-only transformers.
1
4
68
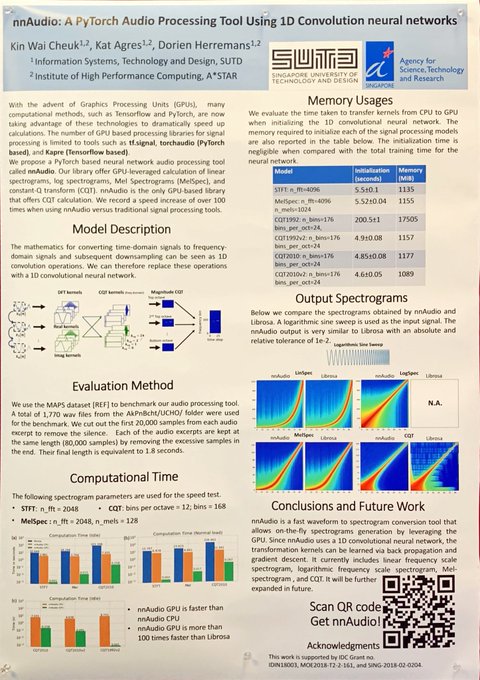
Audio/Deep learning folks - please go check out our `torchaudio-contrib`!
By
@faroit
, Kiran Sanjeevan, and me.

3
27
66
👋
I joined
@PrescientDesign
recently. I distracted
@kchonyc
with music research circa 2016-2019. This time he offered me to join his realm -- languages! I'm already having a lot of fun, knowing more to come.
6
2
65

MT3: Multi-Task Multitrack Music Transcription
T5, but for music transcription. A neat solution to cope with many-but-small existing datasets.
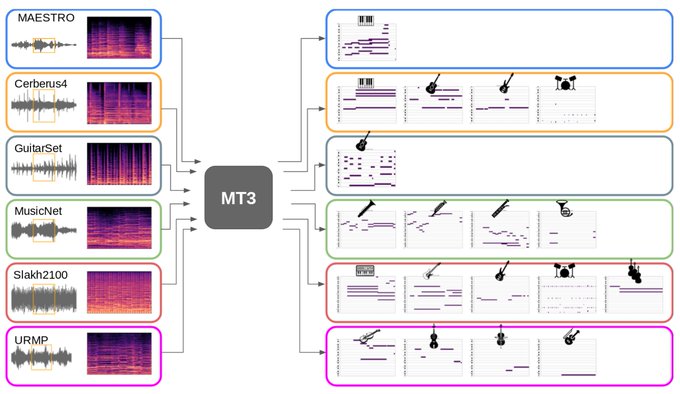
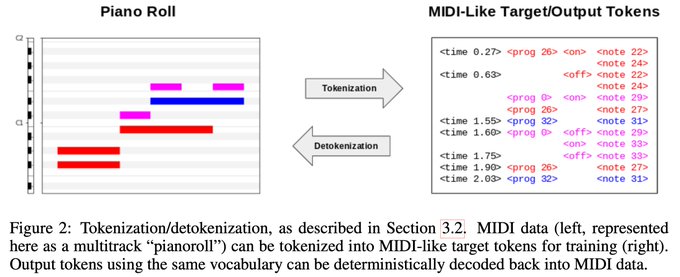
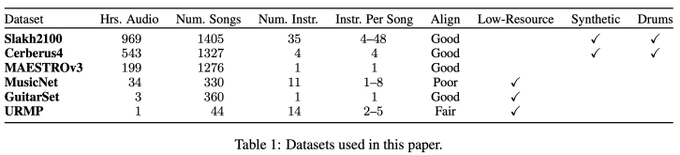
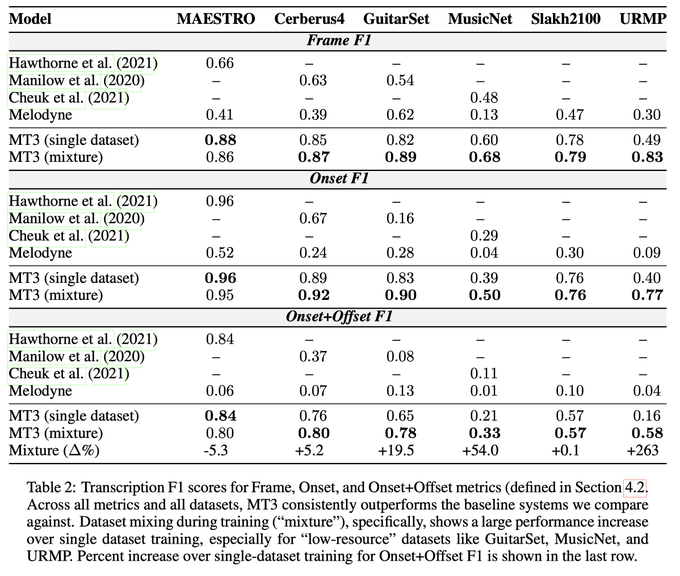
1
6
62
🎙 Let's talk about AI research. And datasets.
Accessibilities. Opportunities. Music.

1
6
61
<shameless as always>
my papers are 1st and 6th most cited ISMIR paper in the last 5 years!🔥🔥
heard it was mentioned at the
#ismir2021
trivia organized by the titans
@r4b1tt
@urinieto
. i think they should arXiv the trivia and cite my paper thx
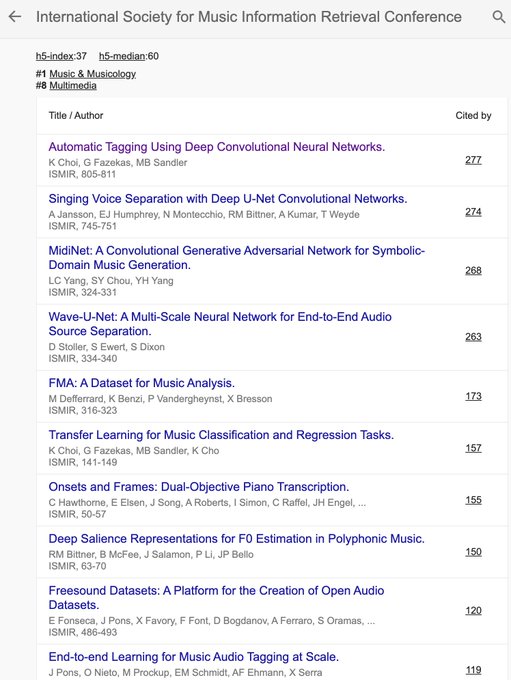
5
2
61
AudioLM = w2v-BERT + SoundStream
w2v-BERT is..
- a BERT, but for audio. originally for speech. in AudioLM, an intermediate layer from speech-pretrained model was used.
- it's "coarse" (250bps of bitrate.)
- it takes care of semantic information.
1
0
58
ByteDance/TikTok is hiring research scientists and software developers around music information retrieval and music/audio signal processing at Mountain View, US. Please hit me up!
#ismir2020
1
12
57
we're hiring AI/LLM engineers!
- covering both pre-training and post-training tasks
- purely for product development, based on *extensive understanding in LLMs*
- with real-world impacts on drug discovery in Genentech
- no publication within sight
1
12
55
do you know what ChatGPT can't do?
🔊 audio generation.
we do, at Gaudio Lab 😉
2
10
54
SoundStream is..
- a neural audio codec.
- residual vector quantizer (RVQ) is used
- as a codec, it's "fine-grained" (2000bps of bitrate)
2
0
53
@urinieto
ROCKING
#ismir2019
HAHAHAHAHAHA 😂😂😂 seriously, my every follower should watch this otherwise please unfollow thanks.
0
12
53
What would you say if I passed the PhD viva today? I mean, I did, so feel free to really say it!
22
0
52

Frrquency-aware CNNs. Ooops I was working on the same thing last summer but had no time after some experiments. It worked for music classification and source separation. Go try this!

4
3
51
🎉 It's happening. Foley Sound Synthesis Challenge!
Generative AI folks, join us and make some sound! 🔊
1
14
50
We're looking for a junior-level MIR researcher (perhaps Master or PhD) in Shanghai; to work with me on music tagging and related problems. Expecting to hire ASAP. Please email me if you're interested!
2
12
48
It seems clear to me that Tensorflow developers are not deeply understanding why researchers struggle with their product. Life is too short for most of researchers to be very good at all Python and machine learning. TF adds another burden, but Pytorch doesn't.
4
11
49
in the training set, no text label is needed because we.. i mean, googlers.. have pre-trained MuLan!
also, if you believe the power neural codec, SoundStream, no need to trained end-to-end with waveforms etc! SoundStream tokens are good enough!
1
0
49

TikTok🎶 is hiring a research scientist in Music/ML @🇬🇧 London office 🔥 Join our SAMI team to work on Speech, Audio, and Music intelligence with us :)
Please feel free to reach out to me for any question 📧
0
6
46
inference is straightforward.
do the same with the training stage except
- use MuLan text model, because we want *text*-to-music.
- after SoundStream tokens are predicted, feed them to SS decoder to generated audio.

1
0
45
*QUITE A FEW* papers are accepted to
#ismir2021
from our team in ByteDance 🚀🚀🚀🚀🚀🚀🚀 I'll share more details once the proceedings are updated.
And yes we're hiring 🔥🔥🔥🔥🔥🔥🔥
0
2
45
Sheet Sage: Lead sheets from music audio
Leverage Jukebox for melody extraction.
Who'd submit this level of amazing work simply to late-breaking/demo session? This guy →
@chrisdonahuey

1
6
44

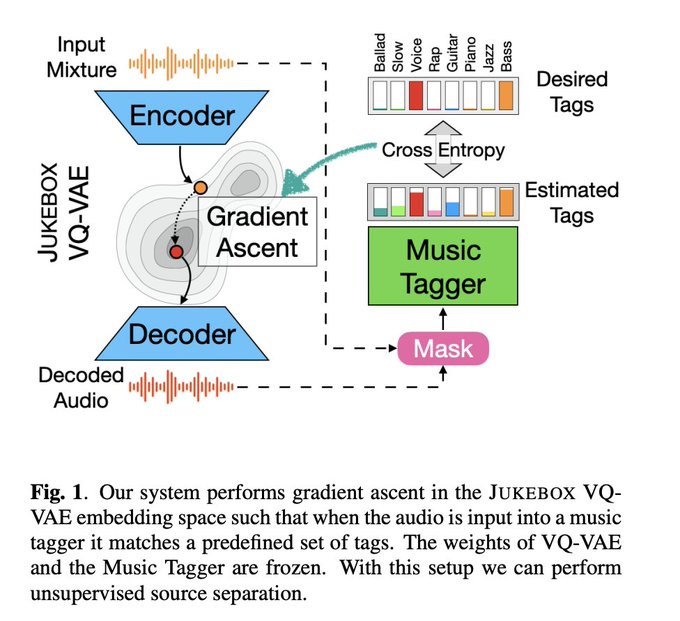
amazing, amazing. done by
@ethanmanilow
@pseetharaman
et al.

Unsupervised Source Separation By Steering Pretrained Music Models
abs:
3
29
159
2
5
43
🚨 We have a MLE position open at
@PrescientDesign
to find a strong engineer to make our language models stronger.
2
12
39
Room Impulse Response Estimation in a Multiple Source Environment. By
@kyungyunleee
at
@gaudiolab
et al.
3
2
40
c4dm folks won the
#ismir2022
best paper award!! 🎉🥳🎊 amazing!
congrats,
@liulelecherie
@QiuqiangK
@veromorfi
@emmanouilb
!

0
2
40
Long time no first-authoring! Listen, Read, and Identify network (LRID-Net) identifies singing language by reading the metadata (title, album, artist) and listening to the audio.
1
4
38
Our paper about DCASE Challenge T7 - Foley Sound Synthesis was accepted to the DCASE Workshop 🥳
I can't make it to Finland🇫🇮, but some of the authors will be there to tell you what we went through while organizing the first generative challenge at DCASE.

0
6
39

i'm giving an introductory talk about LLMs for drug discovery at
#ASCPT2024
pre-conference soon.


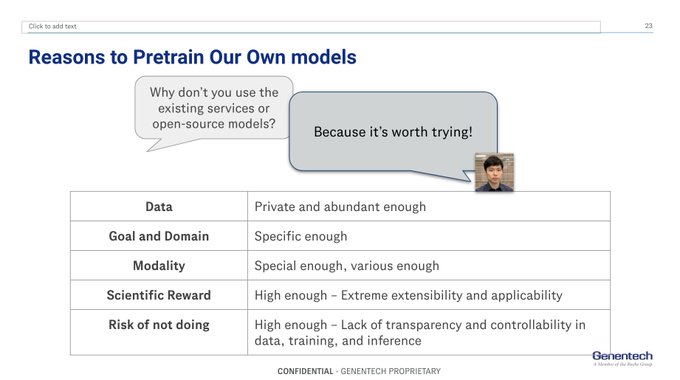
2
8
38
another day, another music generation paper! a diffusion one this time. i’m very curious where they got the training data 🤔
Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts
project page:
11
83
496
2
1
38
ByteDance 🚀 US Speech / Audio / Music research team is extensively hiring research scientists. If you’re a graduating PhD this year, don’t wait and just DM me! 🔥🔥
3
12
37
new music AI model alert 🚨
get your music tracks segmented by
@taejun_kim_

Music Structure Analyzer Released ✨
[Python Package]
[Paper]
[Interactive Demo]
[Hugging Face Space]
11
55
264
2
3
38
DawDreamer: A Python-interfaced DAW. Yeah we can do lot of things with this.

DawDreamer has gained many features recently including pip install. A new notebook shows how to load Ableton warp marker files like this video. Faust integration enables custom polyphonic instruments. Hopefully very useful for ML researchers and artists.
0
0
14
1
4
38

teaching "deep learning for media" at NYU was super fun! now, let me disseminate my students' final projects. these are really cool stuff.
they somehow made it in the vary last minute. i swear none of these was at this level just one week before 😂
anyways, 🧵 starts -
2
1
36
Try it yourself our music source separation!
🚨 ALERT: The performance might be way too good.
4
7
35
look how shamelessly i'm included here! as always, it was great to connect to all the great researchers in MACLab supervised by
@juhan_nam
at
@ISMIRConf
.

This year, people from the Music and Audio Computing Lab at KAIST, led by
@juhan_nam
, participated in the
@ISMIRConf
, and presented our work through scientific programs, late-breaking demos and music sessions!

1
3
35
1
0
35
Big news in AI this week
- Mistral 7B on torrent
- Google Gemini
- and..
- my first single album <unspoken serenity> released;

2
0
35
DCASE Task 7 - Foley Sound Synthesis has finished. It was the very first generative audio AI challenge. I'm very happy to have organized such a successful event! 🎉
1
2
35
The longest ever video of me talking public has become public. "Deep Learning with Audio Signals: Prepare, Process, Design, Expect" in
@QConAI
. In case me tweeting around you isn't enough.

1
5
35
generative AI audio is here to stay.. and prosper! check out this year's challenge.
T7. Sound Scene Synthesis
#DCASE2024

0
2
33
are you an LLM nerd who can understand ML/language model papers and write good code? 👀
we're hiring AI/LLM engineers!
- covering both pre-training and post-training tasks
- purely for product development, based on *extensive understanding in LLMs*
- with real-world impacts on drug discovery in Genentech
- no publication within sight
1
12
55
2
4
32
The
#ismir2019
poster repo is hosting 25 posters and 38-starred now. Would you please 'Like' this tweet if you've ever been the repo and seen any posters there? I wanna know its impact. Thanks!

0
6
33
최근우, 김사무엘(Samuel Kim) 및 174명의 음향, 음성 과학자는 PD수첩에서 방영한 숭실대학교 배명진 교수 사태와 관련 다음의 성명서를 발표합니다. 이 성명서는 한국음향학회 및 숭실대학교 전자정보공학부 임원진과 교수님들께도 발송하였습니다. 감사합니다. 성명서:

1
63
29
After like 3 months of experiments (with some progress) I just realised out of N layers, good three of them didn't have an activation function at all.
5
1
32
"Building the MetaMIDI Dataset: Linking Symbolic and Audio Musical Data"
Hell a lot of midi files and matched audio clips.
#ismir2021

1
4
31
oo more text-to-music to come. this time, from academia!

Can't wait to share our new Text-to-Audio model, AudioLDM. 😆
This video shows the generation result with a simple text prompt: "A music made by xxx".
More demos coming soon!😉
The paper will be available next Monday on arXiv! 😊
Our model will be open-sourced soon!😎
27
99
613
2
6
31
so are spectrograms just images???
Riffusion, real-time music generation with stable diffusion
@huggingface
model:
project page:

64
626
3K
6
2
31
Um, Spotify will definitely hire 2019 summer research interns for some fun MIR works, so please stay tuned! (i.e. don't say yes to others too soon 😎)
3
2
30
"Visualization for AI-Assisted Composing" shows lots of cool ideas! absolutely helpful, i'd say.
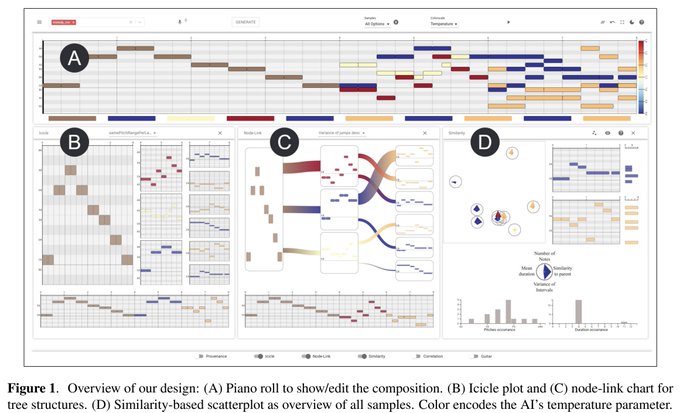

2
3
31
two sides of making music.
(a) manufacturing music
(b) expressing creativity through music
i see prompting music Gen AI - to get the final, whole audio - purely as (a), which is totally fine as long as its training is done legally.
5
3
31
I've been an audio person for 10+ years. Let me tell you - you don't need 192/24 or anything. If you don't like the audio quality from any legit music streaming service, it's NOT about the codec. get a better connection, quieter place, better earbuds.
4
6
31