

Lucas Atkins
@LucasAtkins7
Followers
3K
Following
5K
Media
231
Statuses
3K
Today, we’re officially releasing the weights for AFM-4.5B and AFM-4.5B-Base on HuggingFace. This is a major milestone for @arcee_ai. AFM is designed to be flexible and high-performing across a wide range of deployment environments.

23
58
340
Glad to see EvolKit being used here - we should probably fast track v2.

Motif 2.6B tech report is pretty insane, first time i see a model with differential attention and polynorm trained at scale!. > It's trained on 2.5T of token, with a "data mixture schedule" to continuously adjust the mixture over training. > They use WSD with a "Simple moving

1
1
21

This is my super bowl dude hell yeah.

BACK 2 BACK 2 BACK. WE SWEEP THE ENTIRE WAR WITHIN AND CLAIM OUR THIRD STRAIGHT WORLD FIRST!!! 🏆🏆🏆

1
0
6
The gang moves to SF.

SF I have moved to you.
4
0
36
RT @vikhyatk: mixture of experts models are so painful to train it feels like I'm doing it on purpose to inflict suffering on myself.
0
2
0
RT @giffmana: This is an unwise statement that can only make people confused about what LLMs can or cannot do. Let me tell you something: P….
0
33
0
.@ariaurelium has been exemplary: . focused, creative, self-motivated, curious, and deeply informed. can't ask for much more. welcome to the team!.

really happy to announce: I joined @arcee_ai working on software infrastructure! it's really exciting to be part of such a focused and innovative team. i can now say pretty confidently that we are Cooking.
1
0
24
Had a great time at the @datologyai office today. Sorry for @code_star photo bombing the logo shot

18
4
105
The last two days have been a whirlwind, and I haven’t had a chance to read this end to end - though I did see an early draft - let alone comment. I’m one of the few people outside @datologyai fortunate enough to have seen these results firsthand, and everyone can experience.

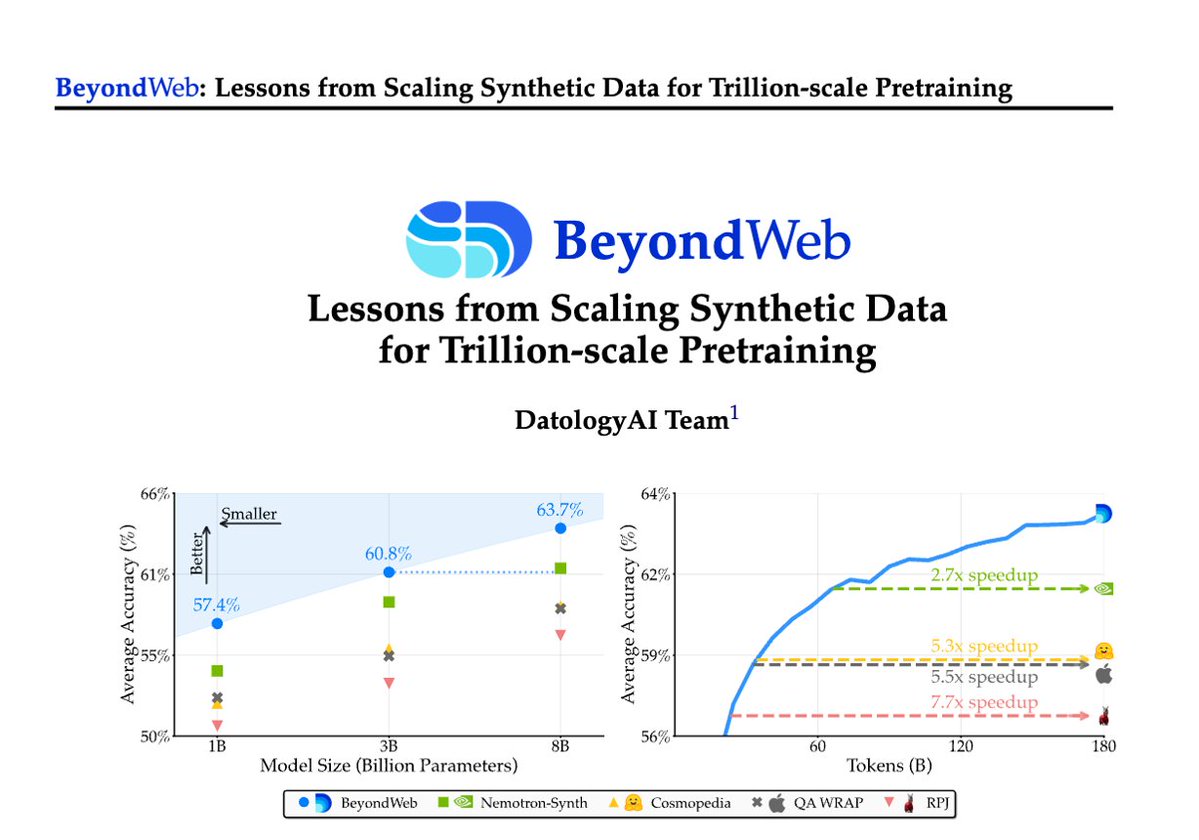
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳.- 3B LLMs beat 8B models🚀.- Pareto frontier for performance
0
12
66
Elie is one of the good ones.
I really like the fact that @deepseek_ai released a model with small improvements. There's literally no downside, thanks 🐳 for the strong oss commitment once again, it's the way to go when you're developing a sota model. What's the point of gatekeeping it because it doesn't

2
0
15

RT @code_star: the last thing you see before your run crashes (again). wandb: ⭐️ View project at .wandb: 🚀 View run at.
0
7
0

RT @samsja19: kind of annoying to get startup idea each time I go on a long bike ride, I need to focus on open source agi rn.
0
1
0
I literally could NOT be more bullish on this.


2
7
65
I’m fine with this. The community largely agrees that lmsys isn’t a reliable proxy for real-world performance, and Sonnet consistently scores low because it doesn’t optimize for that benchmark. To me, this signals a shift from preference-based rewards to real-world rewards, and

1
2
27
RT @boltdotnew: Most vibe coding tools are fun toys, but fail to scale your products with secure & reliable infrastructure. Today this cha….
0
87
0



My week is ruined.


2
0
23