

Serena Yeung-Levy
@yeung_levy
Followers
7K
Following
284
Media
1
Statuses
114
Assistant Professor of Biomedical Data Science and (by courtesy) of CS and EE @Stanford. AI, healthcare, computer vision.
Stanford, CA
Joined October 2010

🚀 Excited to release SciVideoBench — a new benchmark that pushes Video-LMMs to think like scientists! Designed to probe video reasoning and the synergy between accurate perception, expert knowledge, and logical inference. 1,000 research-level Qs across Physics, Chemistry,

🚨 New Paper Alert! Introducing SciVideoBench — a comprehensive benchmark for scientific video reasoning! 🔬SciVideoBench: 1. Spans Physics, Chemistry, Biology & Medicine with authentic experimental videos. 2. Features 1,000 challenging MCQs across three reasoning types:
0
7
16

🧬 What if we could build a virtual cell to predict how it responds to drugs or genetic perturbations? Super excited to introduce CellFlux at #ICML2025 — an image generative model that simulates cellular morphological changes from microscopy images. https://t.co/z3N0dV3i91 💡
3
20
50

Really enjoyed collaborating with Anita Rau, @yeung_levy, and the Stanford crew on this! If we want AI to help in the OR, we need to know what today's VLMs can (and can't) do. Great to see Med-Gemini benchmarked alongside others here in this much-needed, rigorous eval for the
How good are current large vision-language models at performing the tasks needed for surgical AI? We conducted an assessment of leading models including proprietary (GPT / Gemini / Med-Gemini) and open-source (Qwen2-VL / Pali Gemma / etc.) generalist autoregressive models,
0
3
13
How good are current large vision-language models at performing the tasks needed for surgical AI? We conducted an assessment of leading models including proprietary (GPT / Gemini / Med-Gemini) and open-source (Qwen2-VL / Pali Gemma / etc.) generalist autoregressive models,

There’s growing excitement around VLMs and their potential to transform surgery🏥—but where exactly are we on the path to AI-assisted surgical procedures? In our latest work, we systematically evaluated leading VLMs across major surgical tasks where AI is gaining traction..🧵
0
8
53
🚨 Excited to co-organize our @CVPR workshop on "Multimodal Foundation Models for Biomedicine: Challenges and Opportunities" — where vision, language, and health intersect! We’re bringing together experts from #CV, #NLP, and #healthcare to explore: 🧠 Technical challenges (e.g.
0
16
60
We're excited to introduce a new VLM benchmark, MicroVQA, to support frontier models pushing towards scientific research capabilities! MicroVQA comprises 1K manually created, researcher-level questions about biological image data, contributed by biologist researchers from diverse

Introducing MicroVQA: A Multimodal Reasoning Benchmark for Microscopy-Based Scientific Research #CVPR2025 ✅ 1k multimodal reasoning VQAs testing MLLMs for science 🧑🔬 Biology researchers manually created the questions 🤖 RefineBot: a method for fixing QA language shortcuts 🧵
0
7
70
🚨Large video-language models LLaVA-Video can do single-video tasks. But can they compare videos? Imagine you’re learning a sports skill like kicking: can an AI tell how your kick differs from an expert video? 🚀 Introducing "Video Action Differencing" (VidDiff), ICLR 2025 🧵
7
48
58
Just published in @ScienceAdvances, our work demonstrating the ability of AI and 3D computer vision to produce automated measurement of human interactions in video data from early child development research -- providing over 100x time savings compared to human annotation and
2
13
53
🚀 Introducing Temporal Preference Optimization (TPO) – a video-centric post-training framework that enhances temporal grounding in long-form videos for Video-LMMs! 🎥✨ 🔍 Key Highlights: ✅ Self-improvement via preference learning – Models learn to differentiate well-grounded
1
12
29
We've just released BIOMEDICA, an open-source resource making all scientific articles from PubMed Central Open Access conveniently accessible for model training through Hugging Face, with accompanying tags and metadata. Includes 24M image-text pairs from 6M articles, annotations,

Biomedical datasets are often confined to specific domains, missing valuable insights from adjacent fields. To bridge this gap, we present BIOMEDICA: an open-source framework to extract and serialize PMC-OA. 📄Paper: https://t.co/zkb2m5yeal 🌐Website: https://t.co/atIKEfOpkv
8
44
216
Biomedical datasets are often confined to specific domains, missing valuable insights from adjacent fields. To bridge this gap, we present BIOMEDICA: an open-source framework to extract and serialize PMC-OA. 📄Paper: https://t.co/zkb2m5yeal 🌐Website: https://t.co/atIKEfOpkv
13
55
145
🔍 Vision language models are getting better - but how do we evaluate them reliably? Introducing AutoConverter: transforming open-ended VQA into challenging multiple-choice questions! Key findings: 1️⃣ Current open-ended VQA eval methods are flawed: rule-based metrics correlate
3
73
153

How does visual token pruning after early VLM layers maintain strong performance with reduced visual information? The answer may not be what you expect. ✨Introducing our new paper Feather the Throttle: Revisiting Visual Token Pruning for Vision-Language Model Acceleration 🧵👇
3
9
23

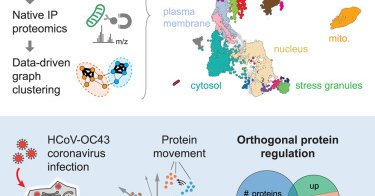
So excited to start the year w/ our new paper @CellCellPress! #proteomics spatial map of human cells + dynamics using #organelle IP at scale. 🙌 to amazing teamwork @czbiohub and beyond. Check out portal https://t.co/Gb1TvlKcCH and paper https://t.co/YskVRBUqZi. 1/n
cell.com
Organelle proteomics defines the cellular landscape of protein localization and highlights the role of subcellular remodeling in driving responses to perturbations such as viral infections.
16
49
222
🤔 Why are VLMs (even GPT-4V) worse at image classification than CLIP, despite using CLIP as their vision encoder? Presenting VLMClassifier at #NeurIPS2024: ⏰ Dec 11 (Wed), 11:00-14:00 📍 East Hall #3710 Key findings: 1️⃣ VLMs dramatically underperform CLIP (>20% gap) 2️⃣ After
2
21
87
Our lab at Stanford has postdoc openings! Candidates should have expertise and interests in one or multiple of: multimodal large language models, video understanding (including video-language models), AI for science / biology, or AI for surgery. Please send inquiries by email and
4
39
199

Thank you @StanfordHAI and Hoffman-Yee for this grant to build a unified model of human cells spanning molecules, their structures and cellular organization - applied towards women’s health. Super excited for this collab w @StephenQuake @jure @yeung_levy @Rbaltman 🌟

We are pleased to announce six @Stanford research teams receiving this year's Hoffman-Yee Grants, a key initiative of @StanfordHAI since our founding. Read about the scholars who are ready to shape the future of human-centered AI: https://t.co/r7eCqKKSZy
0
3
28

📅I am happy to be presenting Video-STaR at @twelve_labs's webinar this Friday (Aug 2nd, 13:30)! ⏪Almost three weeks ago, we released Video-STaR, a novel self-training method that allows improving and adapting LVLMs with flexible supervision. 📈 I am happy to see the continued

✅ @orr_zohar, Ph.D. Student @StanfordAILab, will introduce Video-STaR - a self-training for video language models, allowing the use of any labeled video dataset for video instruction tuning. https://t.co/OooOdwQIM9
0
4
8
📢 Check out our ECCV paper, “Viewpoint Textual Inversion” (ViewNeTI), where we show that text-to-image diffusion models have 3D view control in their text input space https://t.co/emBVF4jfjf
1
11
33