

Alejandro Lozano
@Ale9806_
Followers
163
Following
46
Media
7
Statuses
48
Ph.D. Student @ Stanford AI Lab Building open biomedical AI
Stanford, California
Joined May 2023
RT @Zhang_Yu_hui: 🧬 What if we could build a virtual cell to predict how it responds to drugs or genetic perturbations?. Super excited to i….
0
20
0
RT @AkliluJosiah2: There’s growing excitement around VLMs and their potential to transform surgery🏥—but where exactly are we on the path to….
0
6
0

Shout out to my stellar first co-authors @minwsun and @jmhb0 for leading this effort, as well as the incredible team of computer scientists, statisticians, biologists, and clinicians that made this possible: @jnirsch.Christopher Polzak, @Zhang_Yu_hui, @cliangyu_, Jeffrey Gu,.
0
0
1
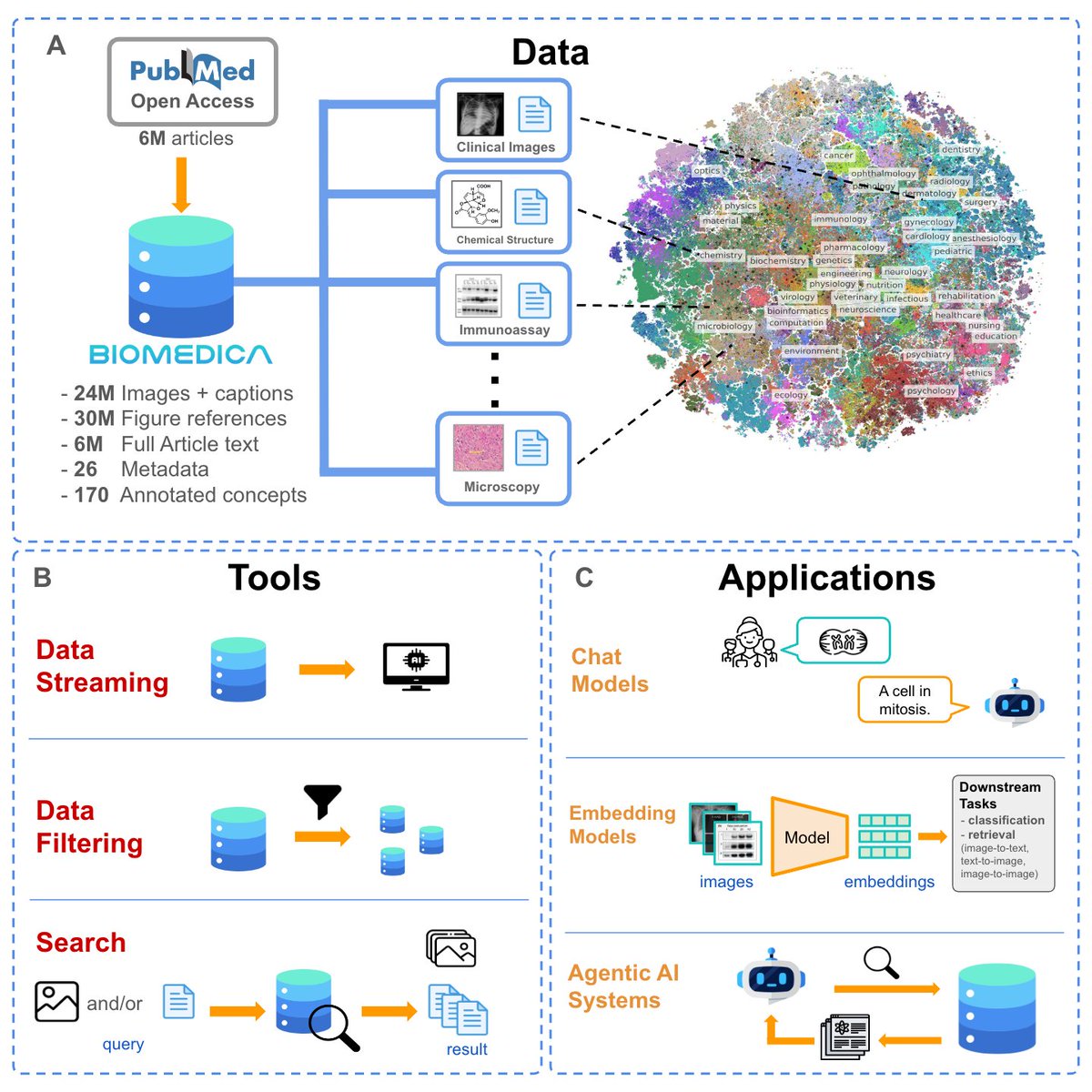
Earlier this year, we released the BIOMEDICA dataset, featuring 24 million unique image caption pairs and 30 million image references derived from open-source biomedical literature. It's been great to see the community engaging with it—we're currently seeing around 6K downloads
3
9
26
Introducing video differencing, a new task for detecting differences between video frames. Notably, even the most advanced Video LLMs struggle with this challenge, underscoring the long road ahead!.

🚨Large video-language models LLaVA-Video can do single-video tasks. But can they compare videos?. Imagine you’re learning a sports skill like kicking: can an AI tell how your kick differs from an expert video?. 🚀 Introducing "Video Action Differencing" (VidDiff), ICLR 2025.🧵
0
0
4
Check out our new work accepted to ICLR 2025. We introduce time-to-event (TTE) pretraining to leverage temporal supervision from longitudinal EHR data and estimate the risk of future events. By scaling to 225M clinical events, we achieve SOTA prognostic performance!.

🎉 Excited to share that our latest research, 𝘛𝘪𝘮𝘦-𝘵𝘰-𝘌𝘷𝘦𝘯𝘵 𝘗𝘳𝘦𝘵𝘳𝘢𝘪𝘯𝘪𝘯𝘨 𝘧𝘰𝘳 3𝘋 𝘔𝘦𝘥𝘪𝘤𝘢𝘭 𝘐𝘮𝘢𝘨𝘪𝘯𝘨, has been accepted at 𝗜𝗖𝗟𝗥 2025! 🚀. 🔍 𝗜𝗺𝗽𝗿𝗼𝘃𝗶𝗻𝗴 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗜𝗺𝗮𝗴𝗲 𝗣𝗿𝗲𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝘄𝗶𝘁𝗵 𝗧𝗶𝗺𝗲-𝘁𝗼-𝗘𝘃𝗲𝗻𝘁.
0
1
3
RT @XiaohanWang96: 🚀 Introducing Temporal Preference Optimization (TPO) – a video-centric post-training framework that enhances temporal gr….
0
12
0
[10/10. @cliangyu_,@jnirsch, Jeffrey Gu, Ivan Lopez,.@AkliluJosiah2, Austin Katzer, Collin Chiu, Anita Rau,.@XiaohanWang96,@Zhang_Yu_hui, Alfred Song,.@robtibshirani,@yeung_levy.
0
0
2
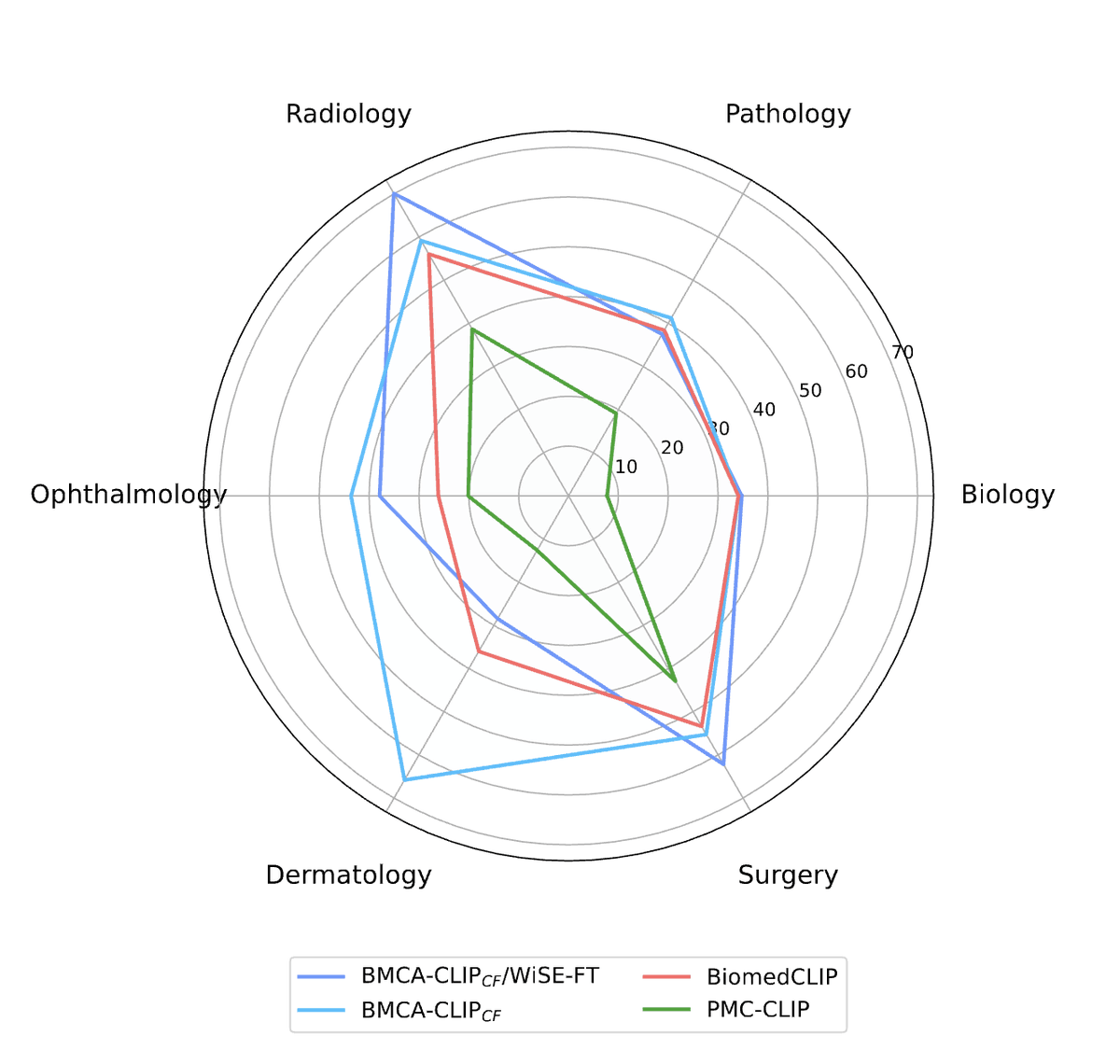
[8/10]. While our models offer state-of-the-art performance, all evaluations indicate that there is still significant room for improvement. We release all our contributions under a permissive license to facilitate broader use and further development.
0
0
2
[7/10] 💡 We demonstrate the utility and accessibility of our resource by training BMC-CLIP, a suite of CLIP-style models continuously pre-trained on our dataset using different training recipes via streaming.
0
0
2
[6/10]. 🎯 We demonstrate the utility and accessibility of our resource by training BMC-CLIP, a suite of CLIP-style models continuously pre-trained on our dataset using different training recipes via streaming.
0
0
2
[5/10]. 💵 Our archive is hosted in HuggingFace, enabling streaming. Eliminating the need to download 3.9 TB of data locally in order to use BIOMEDICA.
0
0
2
[4/10]. ⚡Our archive is serialized as a webdataset. Providing 3x-10x higher I/O rates when compared to random access memory (decreasing GPU idle time).
0
0
1
[3/10]. 🗄️Rather than pre-filtering to specific domains, we provide ~10x more metadata and expert-derived annotations at various granularities. Subsequently, we offer a pipeline to use these metadata and filter on demand, accommodating to different interests in the community.
0
0
2
[2/10]. Our framework produces a comprehensive archive with over 24M unique image-text pairs, including image-captions, image-references, full metadata, and human derived annotations from over 6M articles, that can be freely used by the community for model training.

0
0
3
Biomedical datasets are often confined to specific domains, missing valuable insights from adjacent fields. To bridge this gap, we present BIOMEDICA: an open-source framework to extract and serialize PMC-OA. 📄Paper: .🌐Website:

13
55
145
RT @Zhang_Yu_hui: 🔍 Vision language models are getting better - but how do we evaluate them reliably? Introducing AutoConverter: transformi….
0
74
0