

Shoubin Yu
@shoubin621
Followers
738
Following
853
Media
30
Statuses
388
Ph.D. Student at @unccs @uncnlp, advised by @mohitban47. Interested in multimodal AI.
Joined November 2021
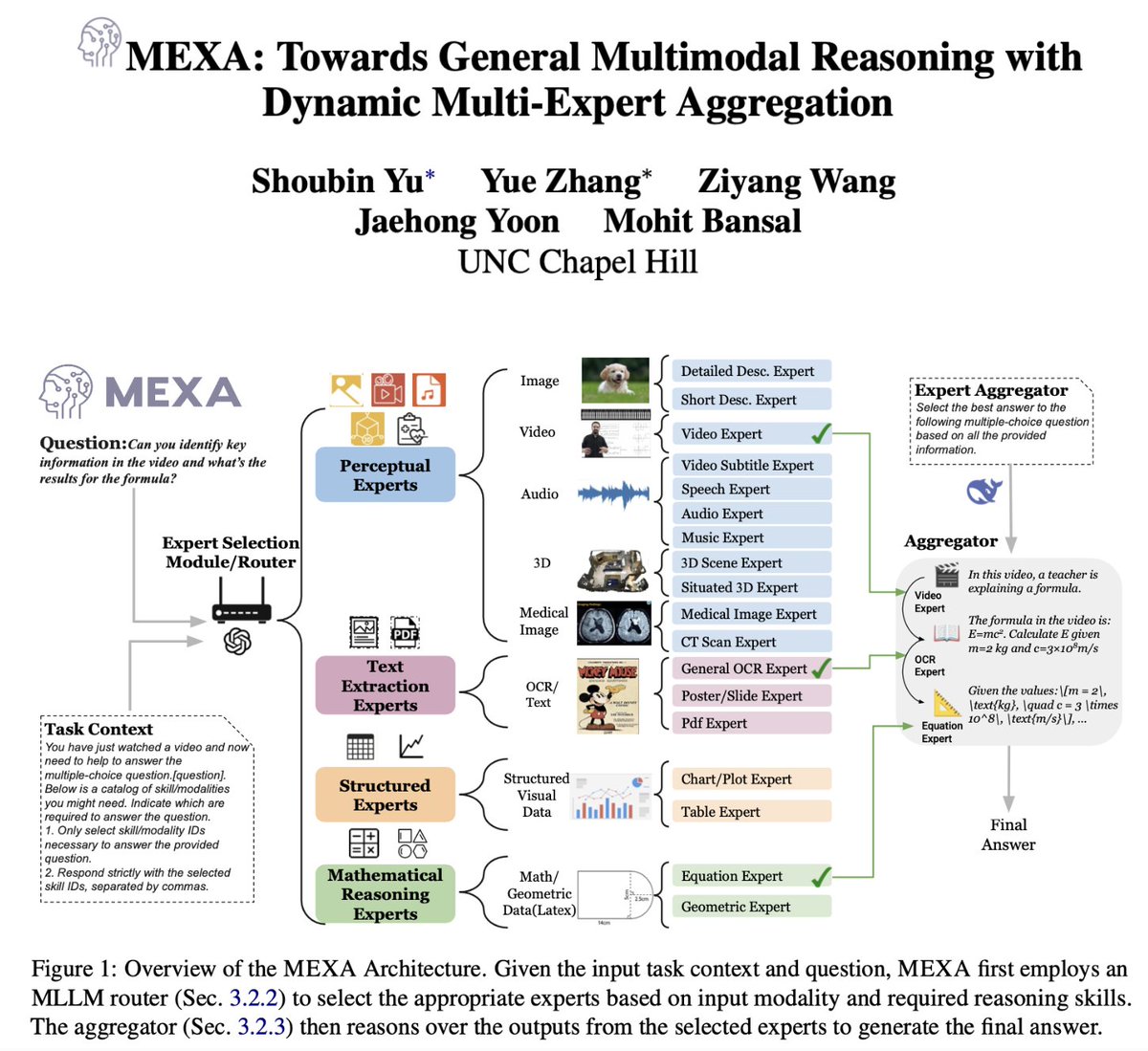
New paper Alert 🚨 Introducing MEXA: A general and training-free multimodal reasoning framework via dynamic multi-expert skill selection, aggregation and deep reasoning!. MEXA:.1. Selects task- and modality-relevant experts based on the query and various required multimodal
2
29
70
RT @hanlin_hl: 🤔 Can we bridge MLLMs and diffusion models more natively and efficiently, by having MLLMs produce patch-level CLIP latents a….
0
47
0

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
380
665
3K
RT @_akhaliq: 3D-R1 is out on Hugging Face. Enhancing Reasoning in 3D VLMs for Unified Scene Understanding. 3D-R1 is an open-source general….
0
72
0
RT @meetdavidwan: Excited to share GenerationPrograms! 🚀. How do we get LLMs to cite their sources? GenerationPrograms is attributable by d….
0
42
0
RT @AiYiyangZ: GLIMPSE 👁️ | What Do LVLMs Really See in Videos?.A new benchmark for video understanding:. 3,269 videos and 4,342 vision-cen….
0
10
0
RT @mmiemon: Checkout our new paper: Video-RTS 🎥.A data-efficient RL method for complex video reasoning tasks. 🔹 Pure RL w/ output-based re….
0
6
0
RT @peterbhase: Overdue job update -- I am now:.- A Visiting Scientist at @schmidtsciences, supporting AI safety and interpretability.- A V….
0
22
0
🚨 Check our new paper, Video-RTS, a novel and data-efficient RL solution for complex video reasoning tasks, complete with video-adaptive Test-Time Scaling (TTS). 1⃣️Traditionally, such tasks have relied on massive SFT datasets. Video-RTS bypasses this by employing pure RL with.

🚨Introducing Video-RTS: Resource-Efficient RL for Video Reasoning with Adaptive Video TTS! . While RL-based video reasoning with LLMs has advanced, the reliance on large-scale SFT with extensive video data and long CoT annotations remains a major bottleneck. Video-RTS tackles

0
8
14
RT @jaeh0ng_yoon: 🚀 Check out our new paper Video-RTS — a data-efficient RL approach for video reasoning with video-adaptive TTS!. While pr….
0
11
0
RT @_akhaliq: Video-RTS. Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video Reasoning .
0
14
0
Don't miss this amazing workshop if you are also working on spatial intelligence 👇.

📣 Excited to announce SpaVLE: #NeurIPS2025 Workshop on Space in Vision, Language, and Embodied AI! . 👉 🦾Co-organized with an incredible team → @fredahshi · @maojiayuan · @DJiafei · @ManlingLi_ · David Hsu · @Kordjamshidi . 🌌 Why Space & SpaVLE?.We

0
4
5
RT @ziqiao_ma: 📣 Excited to announce SpaVLE: #NeurIPS2025 Workshop on Space in Vision, Language, and Embodied AI! . 👉 .
0
27
0
RT @ZiyangW00: 🚨Introducing Video-RTS: Resource-Efficient RL for Video Reasoning with Adaptive Video TTS! . While RL-based video reasoning….
0
29
0
RT @hanqi_xiao: 🎉 Excited to share that TaCQ (Task-Circuit Quantization), our work on knowledge-informed mixed-precision quantization, has….
0
16
0
RT @ArchikiPrasad: 🥳Our work UTGen & UTDebug on teaching LLMs to generate effective unit tests & improve code debugging/generation has been….
0
27
0
RT @AlexiGlad: How can we unlock generalized reasoning?. ⚡️Introducing Energy-Based Transformers (EBTs), an approach that out-scales (feed-….
0
255
0
RT @hyunji_amy_lee: 🥳Excited to share that I’ll be joining @unccs as postdoc this fall. Looking forward to work with @mohitban47 & amazing….
0
27
0
RT @May_F1_: 🧠 How can AI evolve from statically 𝘵𝘩𝘪𝘯𝘬𝘪𝘯𝘨 𝘢𝘣𝘰𝘶𝘵 𝘪𝘮𝘢𝘨𝘦𝘴 → dynamically 𝘵𝘩𝘪𝘯𝘬𝘪𝘯𝘨 𝘸𝘪𝘵𝘩 𝘪𝘮𝘢𝘨𝘦𝘴 as cognitive workspaces, similar….
0
62
0
RT @_akhaliq: Bytedance presents EX-4D. EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh
0
65
0
RT @mohitban47: 🎉 Yay, welcome to the @unc @unccs @unc_ai_group family and beautiful Research Triangle area, Jason! . Looking forward to th….
0
8
0
RT @RenZhongzheng: 🥳 Excited to share that I’ll be joining the CS Department at UNC-Chapel Hill (@unccs @unc_ai_group) as an Assistant Prof….
0
14
0