
Dwarak Rajagopal
@dwarak
Followers
545
Following
246
Media
8
Statuses
254
VP/Head of AI Eng @ Snowflake, ex-{Google, FB/Meta, Uber, Apple, AMD}
Palo Alto, CA
Joined October 2008

Snowflake is at the center of the enterprise AI revolution, and our Q3 results show the momentum. 📈 Product revenue up 29% YoY to $1.16B, with RPO at $7.88B (37% YoY). 💡 Snowflake Intelligence marks our fastest product adoption ever, helping @TSImagine_ , @Fanatics & @USABS
6
15
81

Alright, quite a few things wrt Snowflake AI Research at @NeurIPS in San Diego this week 1. [Expo Booth] Come and talk to us and get a Snowflake T-shirt and swag 2. [Meetup] Snowflake x FastVideo - fireside conversations, food, light drinks - Thursday, Dec 5 @ 5pm - RSVP’s

luma.com
We’re hosting a relaxed, open gathering during NeurIPS for anyone interested in connecting with folks from Snowflake and FastVideo, or simply looking to unwind…
1
5
19
Have you ever wondered by how much is your MoE implementation slower than its dense equivalent - let's say Qwen3-Next-80B-A3B and we want to compare its performance to its 3B dense equivalent which doesn't exist. Well, just set `config.num_experts=0` and voila, you get the dense
5
11
95

18 months ago, @karpathy set a challenge: "Can you take my 2h13m tokenizer video and translate [into] a book chapter". We've done it! It includes prose, code & key images. It's a great way to learn this key piece of how LLMs work. https://t.co/aSgsZz0VxO

fast.ai
A text and code version of Karpathy’s famous tokenizer video.
33
347
3K
AI doesn’t steal jobs. It hands you the keys to all of them.
0
0
4

In era of pretraining, what mattered was internet text. You'd primarily want a large, diverse, high quality collection of internet documents to learn from. In era of supervised finetuning, it was conversations. Contract workers are hired to create answers for questions, a bit

Introducing the Environments Hub RL environments are the key bottleneck to the next wave of AI progress, but big labs are locking them down We built a community platform for crowdsourcing open environments, so anyone can contribute to open-source AGI
262
875
7K
We published new speculative decoding models for gpt-oss-20b and gpt-oss120b! They are based on the LSTMs and make gpt-oss generation 1.6-1.8x faster 🚀 The speculator models are open-sourced and ready-to-run in Arctic Inference 👇
2
6
27
Our team trained and released Arctic Speculator, which improves vllm generation speed by 1.6-1.8x for OpenAI’s recent gpt-oss models. Check it out here: https://t.co/GBf2kUTSvR
5
13
149

Most takes on RL environments are bad. 1. There are hardly any high-quality RL environments and evals available. Most agentic environments and evals are flawed when you look at the details. It’s a crisis: and no one is talking about it because they’re being hoodwinked by labs
31
47
706

We are thrilled to announce that @OpenAI’s most advanced model, GPT-5, is now available natively on Snowflake Cortex AI for customers to use. This integration unlocks a wide range of enterprise use cases within Snowflake’s secure, governed environment: ❄️ Transform data into
0
3
25

🇺🇸 Today is a day we have been working towards for six months. We are announcing America’s AI action plan putting us on the road to continued AI dominance. The three core themes: - Accelerate AI innovation - Build American AI infrastructure - Lead in international AI
247
722
5K
Today is a deep dive into sequence tiling compute. Sequence tiling massively reduces activation memory footprint and can be applied to computations w/o token inter-dependency. The plot shows a huge memory saving with tiled fused logits loss computation. See section 3.1 in our
1
10
64
Arctic Inference helps @allhands_ai complete real-world coding tasks 2x faster through faster LLM inference. Check it out!

Imagine coding agents finishing your requests and sending a pull request in 30 seconds 🤯 Check out this new video of OpenHands + DevStral + @Snowflake’s new inference method ArcticInference. It speeds up coding agents by as much as 2x over vLLM (which is already fast).
0
8
23
As I'm diving into Sequence/Context parallelism in the last few days I wanted to share this write up in 2 parts that nicely compares the few approaches out there and some of their combinations with papers: p1: https://t.co/kUaocgRd78 p2:
insujang.github.io
In the previous analysis of sequence parallelism, I covered two papers 1 2. Those are early works about sequence parallelism and didn’t get attention as there was low demand for context parallelism....
5
25
215
Wrapped up Stanford CS336 (Language Models from Scratch), taught with an amazing team @tatsu_hashimoto @marcelroed @neilbband @rckpudi. Researchers are becoming detached from the technical details of how LMs work. In CS336, we try to fix that by having students build everything:
47
593
5K
Shift Parallelism from @Snowflake AI Research is a game-changer! 🚀 3.4x faster LLM inference with Arctic + @vllm_project . Loving the throughput boost!

Excited to open-source Shift Parallelism, developed at @Snowflake AI Research for LLM inference! With it, Arctic Inference + @vllm_project delivers: 🚀3.4x faster e2e latency & 1.06x higher throughput 🚀1.7x faster generation & 2.25x lower response time 🚀16x higher throughput
1
0
3
Arctic-Text2SQL-R1 outperforms BIRD by 11+ points, using simple rewards, strong reasoning, & scalable design. Enhances SQL generation for complex database queries in analytics platforms. https://t.co/4TYCwDZZha

snowflake.com
A deep dive into how Snowflake AI built Arctic-Text2SQL-R1 using simple rewards, strong reasoning, and a scalable approach to real-world SQL generation.
1
0
1
Arctic Inference delivers 2x faster response times using Shift Parallelism, SwiftKV, & speculative decoding. Optimized for enterprise AI, it scales compute for real-time apps like recommendation systems. https://t.co/1kypypoaIg

snowflake.com
Built by Snowflake AI Research, Arctic Inference uses Shift Parallelism, SwiftKV, and speculative decoding to power the fastest open-source enterprise AI.
3
0
2
16x faster embeddings in Cortex by optimizing serialization, tokenization, & GPU usage for text processing. Achieved 3x throughput over vLLM, cutting costs for scalable AI in search & analytics workloads. https://t.co/62tC2VJ6nI
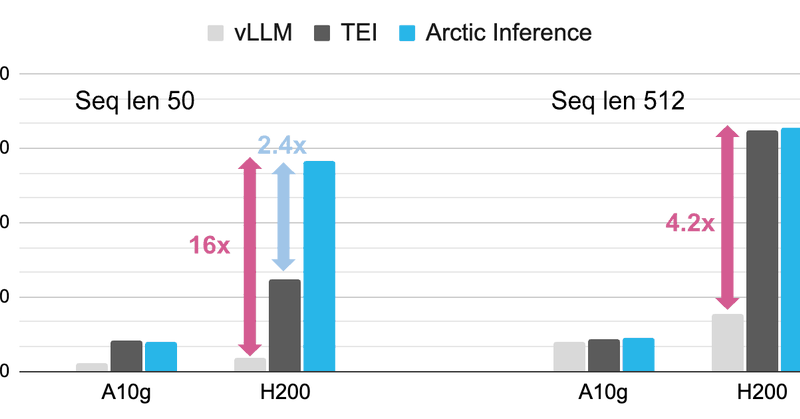
snowflake.com
Learn how we increased embedding throughput 3x in Snowflake Cortex—and 16x vs. vLLM—through smarter serialization, tokenization, and GPU optimization.
1
0
0
🤝 A new era for AI development! @percyliang's Marin lab is redefining open-source AI with open development—fully transparent and collaborative. Join the movement! https://t.co/tH7yKgO68L
#AIInnovation #OpenScience

What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision:
0
0
3