
Runa Eschenhagen
@runame_
Followers
525
Following
522
Media
8
Statuses
198
PhD student in machine learning @CambridgeMLG and external research collaborator @AIatMeta (MSL).
Joined October 2021
1/7 Still using Adam? If anyone wants to try a distributed PyTorch implementation of SOAP/eigenvalue-corrected Shampoo with support for low precision data types instead, here you go. https://t.co/I17zvWhcsb
github.com
For optimization algorithm research and development. - facebookresearch/optimizers
5
87
772

Excited about our new research blog!

Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to

7
12
296

We just released AlgoPerf v0.6! 🎉 ✅ Rolling leaderboard ✅ Lower compute costs ✅ JAX jit migration ✅ Bug fixes & flexible API Coming soon: More contemporary baselines + an LM workload… https://t.co/QBOqGvqNWG
github.com
MLCommons Algorithmic Efficiency is a benchmark and competition measuring neural network training speedups due to algorithmic improvements in both training algorithms and models. - mlcommons/algori...
0
9
43

I would love to see this done, but with the kind of evaluation methodology from the Algo Perf work. Though I guess one of the key takeaways from these two new works is that doing this in a "scaling aware" way requires new methodology.


Amazing "competing" work from @wen_kaiyue @tengyuma @percyliang There are some good stories about optimizers to tell this week 😃 https://t.co/z0K0kG90mW
https://t.co/KziMZlzwGj

1
2
15
Amazing "competing" work from @wen_kaiyue @tengyuma @percyliang There are some good stories about optimizers to tell this week 😃 https://t.co/z0K0kG90mW
https://t.co/KziMZlzwGj
4
31
208

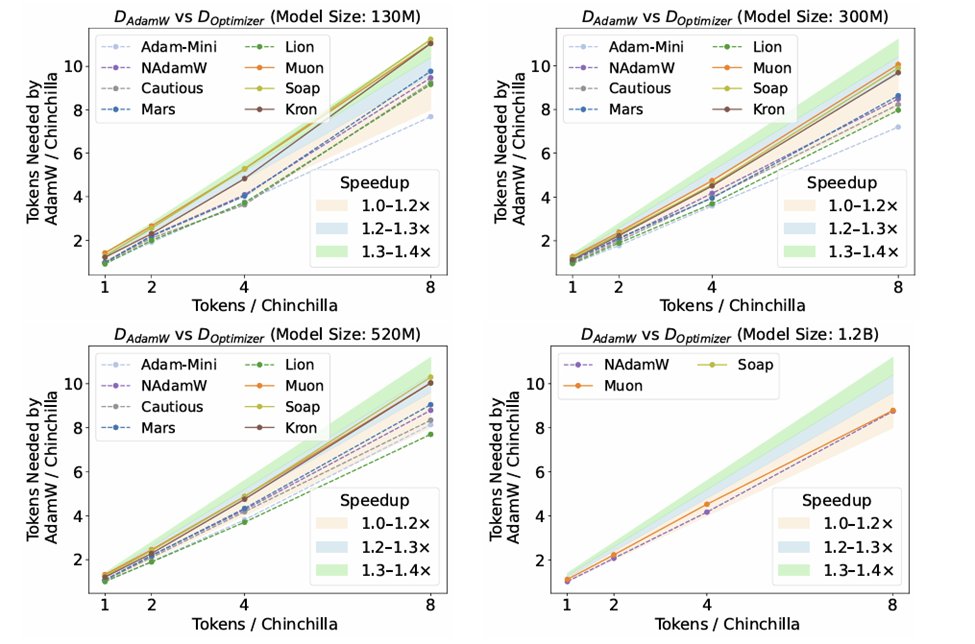
(1/n) Check out our new paper: "Fantastic Pretraining Optimizers and Where to Find Them"! >4000 models to find the fastest optimizer! 2× speedups over AdamW? Unlikely. Beware under-tuned baseline or limited scale! E.g. Muon: ~40% speedups <0.5B & only 10% at 1.2B (8× Chinchilla)!
12
88
418

I've noticed there is some confusion about Dion since it mathematically looks so different from Muon and Spectral descent, so I wrote a small note expressing Dion in terms of the SVD and how it differs from PowerSGD 👇
1
2
4

KFAC is everywhere—from optimization to influence functions. While the intuition is simple, implementation is tricky. We (@BalintMucsanyi, @2bys2 ,@runame_) wrote a ground-up intro with code to help you get it right. 📖 https://t.co/sIQfB1bmsE 💻

github.com
KFAC from scratch (KFS)---Paper & Code. Contribute to f-dangel/kfac-tutorial development by creating an account on GitHub.
0
9
39





This past spring, I spent time with the @exolabs team to work on a new DL optimizer and wiring up clusters of Macs for distributed TRAINING on Apple Silicon. If you’re at ICML, be sure to come by the @ESFoMo workshop (posters 1-2:30pm) this Saturday. I’ll be there to share some



I’m going to be in Vancouver next week for ICML! Would love to meet anyone involved with distributed training, infrastructure, inference engines, open source AI. I'll be presenting two papers: - EXO Gym - an open source framework for simulating distributed training algorithms


4
13
115



Excited to share our ICML 2025 paper: "Scalable Gaussian Processes with Latent Kronecker Structure" We unlock efficient linear algebra for your kernel matrix which *almost* has Kronecker product structure. Check out our paper here: https://t.co/wqq89CTrAb

arxiv.org
Applying Gaussian processes (GPs) to very large datasets remains a challenge due to limited computational scalability. Matrix structures, such as the Kronecker product, can accelerate operations...
1
9
22

I’ll be presenting our paper “On The Concurrence of Layer-wise Preconditioning Methods and Provable Feature Learning” at ICML during the Tuesday 11am poster session! DL opt is seeing a renaissance 🦾; what can we say from a NN feature learning perspective? 1/8
2
9
64

You don't need bespoke tools for causal inference. Probabilistic modelling is enough. I'll be making this case (and dodging pitchforks) at our ICML oral presentation tomorrow.

1
4
15
When comparing optimization methods, we often change *multiple things at once*—geometry, normalization, etc.—possibly without realizing it. Let's disentangle these changes. 👇
1
4
6

📢 [Openings] I'm now an Assistant Prof @WesternU CS dept. Funded PhD & MSc positions available! Topics: large probabilistic models, decision-making under uncertainty, and apps in AI4Science. More on https://t.co/h8R8VpDN83

1
11
27

Never will be.


5
13
139

My former PhD student Fred Kunstner has been awarded the @c_a_i_a_c Best Doctoral Dissertation Award: https://t.co/R6Wdl0FtIu His thesis on machine learning algorithms includes an EM proof "from the book", why Adam works, and the first provably-faster hyper-gradient method.

3
23
238

Why do gradients increase near the end of training? Read the paper to find out! We also propose a simple fix to AdamW that keeps gradient norms better behaved throughout training. https://t.co/t5gxzV9CrZ

13
75
548


