

Pablo Samuel Castro
@pcastr
Followers
13K
Following
16K
Media
3K
Statuses
9K
Señor swesearcher @ Google DeepMind. Adjunct prof @ U de Montreal & Mila. Musician. From 🇪🇨 living in 🇨🇦.
Ottawa/Montreal, QC
Joined December 2009
thrilled to finally put out the second release from my musical project "the 45s" with my buddy JS Diallo!. (links in thread)

1
1
20
RT @LuciaCKun: 📷 New research: How do LLMs think strategically? We built Game Reasoning Arena to find out. LLMs play strategic games whi….

arxiv.org
The Game Reasoning Arena library provides a framework for evaluating the decision making abilities of large language models (LLMs) through strategic board games implemented in Google OpenSpiel...
0
12
0

RT @GoogleDeepMind: 🦜“Where does this endangered bird live?”.🦭“How many seals are being born?”.🐠“Have salmon numbers declined?”. Our update….
0
169
0
It was too hard to pick only four pictures, so here are a few more:




0
0
9
Yesterday I did a 28.4k trail run and 1300m climb with some good friends (& colleagues). It was absolutely incredible! This was my first trail run, but now I think I'm hooked! .#trailrunpostconference




4
0
92




Once again, I leave @RL_Conference convinced that it's the best conference out there for RL researchers, such a great week!.It was also so great getting the opportunity to see so many of my students shine while presenting and discussing their research!




2
5
136
Did the last #runconference @RL_Conference this morning, fun as always. Until the next time (NeurIPS?)!

Great #runconference @RL_Conference today (even with a little rain), join for the last one tomorrow morning, 6:30am, meet at Garneau Lamp!

3
0
48
Was great listening to Turing award winner Rich Sutton tell us about his vision for the future of RL (and AI) @RL_Conference !




3
7
110
Great talk by Peter Dayan @RL_Conference exploring the "open marriage" between natural and engineered reinforcement learning.




2
3
70
RT @jesseengel: Realtime interactive generative models FTW! . Announcing a new 🌊 of details and features for Magenta RealTime, the open wei….
0
170
0
Great #runconference @RL_Conference today (even with a little rain), join for the last one tomorrow morning, 6:30am, meet at Garneau Lamp!
Second #runconference today went well, join us tomorrow same place (Garneau Lamp), same time (6:30am)!

0
2
30
😁

it's extra work, but i really enjoy making creative posters. these are the two i made for #ICML2025 last week. i just sent another poster to get printed with a design i'm excited to hang on the poster boards @RL_Conference next month! 😃


5
7
119
Another great and thought-provoking keynote by @jpineau1 at @RL_Conference , questioning what we mean (and what we should mean) when we talk about "value" in RL!




0
12
84
today (thu) @RL_Conference come see our paper "Optimistic critics can empower small actors".olya and dhruv will present the oral at 11:45am in the deep RL track (CCIS 1-430).and we'll present the poster (poster#8) 3-5:45pm. come chat with us about asymmetric actor-critics!.
📢optimistic critics can empower small actors📢. new @RL_Conference paper led by my students olya and dhruv!.we study actor-critic agents with asymmetric setups and find that, while smaller actors have advantages, they can degrade performance and result in overfit critics. 1/

1
3
25
Very honoured that our paper was granted an outstanding paper award for scientific understanding in RL during the @RL_Conference banquet! .Reggie and Evangelos deserve the bulk of the credit, so congrats to them and all the other awards winners!

today (wed) @RL_Conference come see our paper "Multi-Task Reinforcement Learning Enables Parameter Scaling" . reggie will present the oral at 10:20am in CCIS 1-160.and we'll present the poster 3-5:45pm. come talk to us!.

1
7
121

Super thought-provoking talk by Dale Schuurmans @RL_Conference on LLMs and computation, and why value-based RL doesn't (or can't?) work for post-training.

10
30
336
Second #runconference today went well, join us tomorrow same place (Garneau Lamp), same time (6:30am)!
Great first #runconference @RL_Conference this morning! .Join us tomorrow, 6:30am at the Garneau Lamp for a run (see screenshot or pin below):.


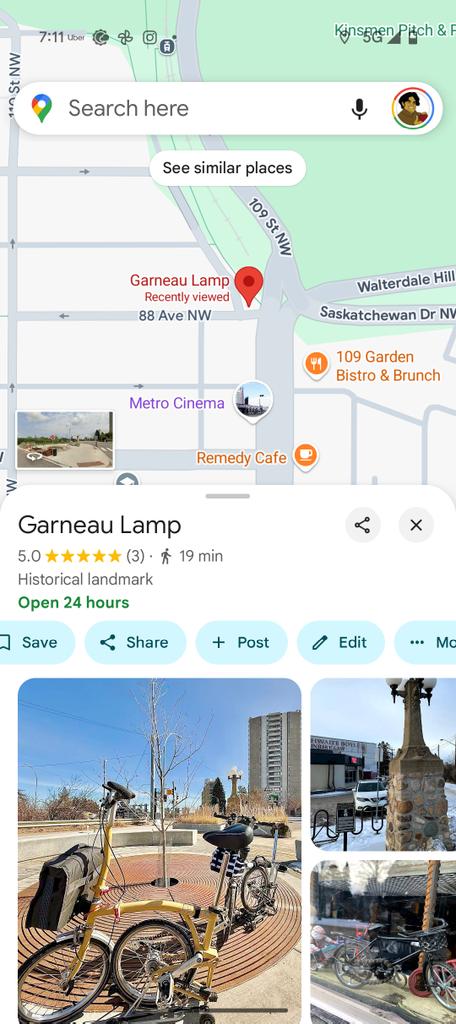
0
2
26
today (wed) @RL_Conference come see our paper "Multi-Task Reinforcement Learning Enables Parameter Scaling" . reggie will present the oral at 10:20am in CCIS 1-160.and we'll present the poster 3-5:45pm. come talk to us!.
1
5
25
Great first #runconference @RL_Conference this morning! .Join us tomorrow, 6:30am at the Garneau Lamp for a run (see screenshot or pin below):.
(mostly) unrelated to workshops, i'll be going for a run tomorrow at 6:30am. i know it's super early, but i want to make it in time for the workshops!.if you want to join, i'll be starting my run outside the metterra hotel #runconference #rlc2025
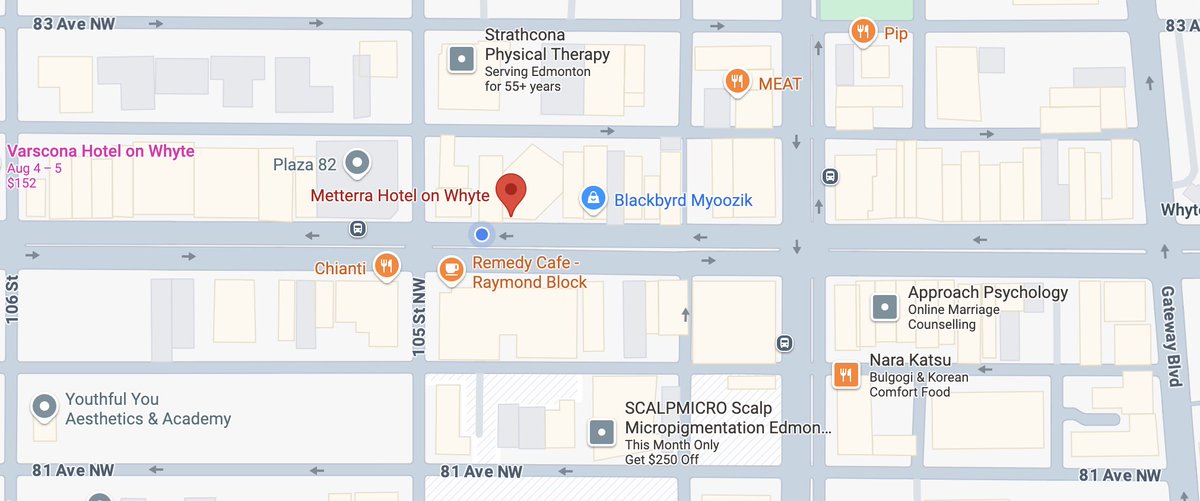
0
1
22