

Rishabh Agarwal
@agarwl_
Followers
11K
Following
8K
Media
135
Statuses
1K
Reinforcement Learner @AIatMeta, Adjunct Prof at McGill. Ex DeepMind, Brain, Mila, IIT Bombay. NeurIPS Best Paper
Montréal, Canada
Joined May 2016
I recently gave a tutorial on knowledge distillation for LLMs, explaining the mathematical derivations behind the commonly used methods. Sharing the slides here given the recent interest in this topic.

18
180
1K
RT @GoogleDeepMind: An advanced version of Gemini with Deep Think has officially achieved gold medal-level performance at the International….
0
784
0
RT @yong_zhengxin: I wrote up this post about how we should **unify RL and next-token-prediction** based on my perspective how humans learn….
0
50
0
RT @RotekSong: Kimi K2 is here! The first big beautiful model purpose-built for agentic capabilities is now open-source! Agent RL, ready fo….
0
18
0
RT @jacobmbuckman: The age of transformers is ending. the dawn of linear-cost architectures is upon us. Power Attention replaces Flash Att….
0
17
0
0
9
0
RT @Happylemon56775: Excited to share what I worked on during my time at Meta. - We introduce a Triton-accelerated Transformer with *2-sim….
0
96
0
RT @AleksandraFaust: Join my team at @genesistxai ! 🧬 We're forging AI foundation models to unlock groundbreaking therapies for patients wi….
0
9
0
RT @setlur_amrith: Since R1 there has been a lot of chatter 💬 on post-training LLMs with RL. Is RL only sharpening the distribution over co….
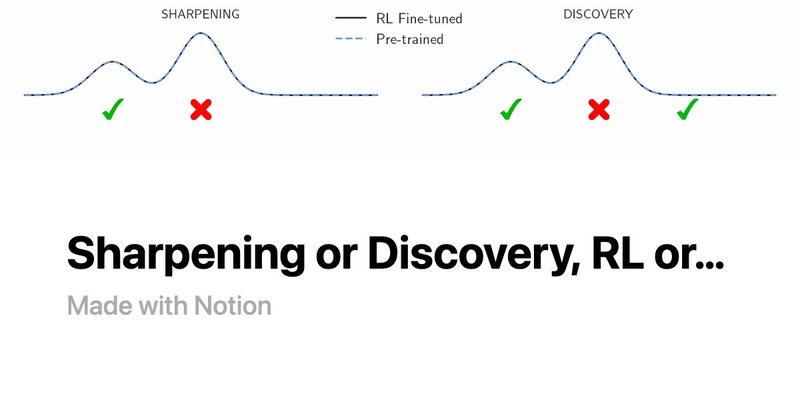
pinnate-flare-8f3.notion.site
Amrith Setlur and Aviral Kumar, Carnegie Mellon University
0
28
0
RT @MiniMax__AI: Day 1/5 of #MiniMaxWeek: We’re open-sourcing MiniMax-M1, our latest LLM — setting new standards in long-context reasoning.….
0
307
0
RT @setlur_amrith: Introducing e3 🔥 Best <2B model on math 💪.Are LLMs implementing algos ⚒️ OR is thinking an illusion 🎩.? Is RL only sharp….
0
26
0
RT @jacobandreas: 👉 New preprint on a new family of Transformer-type models whose depth scales logarithmically with sequence length. Enable….
0
10
0
RT @KhurramJaved_96: Learning to play Atari from pixels from scratch in 30 minutes, all locally on an Apple Watch!
0
11
0

RT @scaling01: A few more observations after replicating the Tower of Hanoi game with their exact prompts:. - You need AT LEAST 2^N - 1 mov….
0
255
0
RT @InfiniAILab: 🥳 Happy to share our new work – Kinetics: Rethinking Test-Time Scaling Laws. 🤔How to effectively build a powerful reasoni….
0
70
0
Good take -- it's a good benchmark to develop better training algorithms / inference time scaling, which you can validate on other domains. Random / incorrect rewards won't work on this one . Main gotcha is to not overfit to just ARC- like puzzles.

people stopped working on ARC-AGI because they realized it was too hard.
3
5
73



RT @charlesfornlp: So many works talking about entropy, but what is the **mechanism** of entropy in RL for LLMs? 🤔. Our work gives a princi….
0
18
0