

Mehmet Saygın Seyfioğlu
@mehsaygin
Followers
914
Following
784
Media
49
Statuses
1,043
Currently @Google and Ph.D. candidate at @UW , working on AI at the intersection of vision and language. Previously 4x Research Intern @AmazonScience .
Seattle, WA
Joined May 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#KAMIGATA_BOYZ
• 130327 Tweets
jeonghan
• 129154 Tweets
ALRIGHT ON TMC STAGE
• 94794 Tweets
#光る君へ
• 60650 Tweets
ジャック
• 45163 Tweets
あんスタ
• 39131 Tweets
ananの表紙
• 38182 Tweets
#阪神タイガース
• 38151 Tweets
ぱしゃっつ
• 26912 Tweets
#鉄腕dash
• 22401 Tweets
ツイステ
• 16421 Tweets
#Meb20BiniYuvarlamalıAçıkla
• 16348 Tweets
阪神ファン
• 11557 Tweets
スイング
• 10087 Tweets



















Pinned Tweet

Thank you
@_akhaliq
for sharing our work!
Check out Diffuse2Choose, a virtual try-all model that allows users to try on any e-commerce item in any setting!
Arxiv:
Website:
Thread:
Stay tuned for more!


Amazon presents Diffuse to Choose
Enriching Image Conditioned Inpainting in Latent Diffusion Models for Virtual Try-All
paper page:
Diffuse to Choose (DTC) allows users to virtually place any e-commerce item in any setting, ensuring detailed,
14
143
729
1
8
54
Introducing Quilt-LLaVA, a Large Language and Vision Assistant for
#Pathology
trained with spatially localized instruction tuning data generated from educational
#YouTube
videos, outperforming SOTA in various tasks.
🌎:
📜:
A 🧵:

4
30
161
Quilt-1M has been accepted for an oral presentation at
@NeurIPSConf
. As promised, we have also released our data and our model:
See you all in New Orleans!

Introducing Quilt-1M: One Million Image-Text Pairs for Histopathology. With Quilt-1M we propose a new source (video) and pipeline for collecting medical multimodal data!
📜:
💻:
🌎:
Demo:
5
31
110
0
15
69
Excited to share our latest work from my
@AmazonScience
internship: Diffuse2Choose, which is a zero-shot diffusion model that enables "Virtual Try-All" – the ability to virtually try on any e-commerce item!
🌎:
📜:
A 🧵:
9
13
61
Happy to share that we will be hosting The First Workshop on the Evaluation of Generative Foundational Models in
@CVPR
!
Are you an NLP or CV researcher with ideas on evaluating generative models? We seek innovative perspectives for talks and discussions, so please reach out!

2
6
56
Excited to share that Quilt-LLaVA has been accepted at
@CVPR
! As promised, we are making our model, datasets, and training scripts available to the community:
See you all in Seattle!
@wizdom_dominic
@fghezloo
@RanjayKrishna
@lindashapiro
Introducing Quilt-LLaVA, a Large Language and Vision Assistant for
#Pathology
trained with spatially localized instruction tuning data generated from educational
#YouTube
videos, outperforming SOTA in various tasks.
🌎:
📜:
A 🧵:
4
30
161
1
7
37
Excited to see our paper's been shared by AK!
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
abs:

0
18
84
0
7
34
Presented our poster with
@wizdom_dominic
and
@fghezloo
at
#NeurIPS2023
. Thank you all for stopping by!

2
2
30
Call for papers on the First Workshop on Evaluation for Generative Foundation Models
@CVPR
. We're eager to hear your ideas on how generative models should be evaluated!
We also have a stellar speaker lineup:
@THassner
, Bo Li,
@RanjayKrishna
, Hanwang Zhang,
@leokarlin
,

3
6
31


0
1
16
Our code, data, and model will be available soon, so stay tuned! Extremely thankful to my amazing co-leads,
@wizdom_dominic
,
@fghezloo
, and to my amazing advisors
@RanjayKrishna
and
@lindashapiro
. Also, a huge thank you to
@Microsoft
for generously supporting us
@ktakeda1
.

0
1
12
After months of hard work, we are proud to introduce Quilt-1M, a large multimodal histopathology dataset curated from Youtube. We fully open-source our dataset and invite everyone to utilize this resource, so give it a try people!
Introducing Quilt-1M: One Million Image-Text Pairs for Histopathology. With Quilt-1M we propose a new source (video) and pipeline for collecting medical multimodal data!
📜:
💻:
🌎:
Demo:
5
31
110
2
3
15
Simulasyonda hava textureleri gec yuklenmeye basladi

0
0
12
Yeni geliştirdiğim neural network weight initialization algoritması milletimizin emrindedir

0
1
10
Jon Snow'un 1 oy farkla seçildiğini unutmayın, oy verin
0
2
9
r(t)=<cos(t),sin(t), t>

NEW - Wind turbine struck by lighting in Cromwell, Texas.
2K
10K
40K
1
0
8
Biri Age of Mythologyde ne kadar buyu varsa tek tek ustumuze atiyo
0
0
8


T.C. Merkez Bankası müzesinde de sergilenmekte olan “Cumhuriyet tarihinin ilk sahte paraları.”


67
365
4K
0
0
8
Thank you
@Scobleizer
, for covering our work!
Check out Diffuse2Choose, a virtual try-all model that allows users to try on any e-commerce item in any setting!
📜:
🌎:
Thread:
Stay tuned for more!

"Diffuse-to-choose"
From Amazon.
Nice implementation, I want to try this.
3
4
30
0
0
8
Europeans never miss any opportunity to be blatantly racist it seems. To my fellow Turkish students, you’ll never see this kind of low IQ garbage statements against students here in the US, so apply here instead.

1
0
7
Excited to share our preprint from my last internship at Amazon: DreamPaint! A framework to inpaint any e-commerce product on any user-provided image.
1/5
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
abs:
0
18
84
2
2
6
Visual Instruction Tuning in pathology faces challenges due to existing PubMed-based datasets that lack 1) Spatial groundings for captions, affecting spatial awareness & 2) Holistic, whole slide image (WSI) level understanding, because of a focus on isolated, patch-level images.
1
0
6

We beat the existing state-of-the-art on close-ended and open-ended tasks on various datasets.



1
0
5
In Iterative Abductive Reasoning, we facilitate conversation between two GPT agents. One, accessing just the patch-level caption, reasons toward a diagnosis. The other, informed by the diagnosis and its supporting facts, guides the first GPT toward the diagnosis as they converse.

1
0
6
Educational videos also enable holistic WSI understanding, which is crucial in pathology. Pathologists compound evidence toward diagnosis as they traverse WSIs in the videos, offering a rich context for diagnosis. The frames that they take time to explain distill the entire WSI.
1
0
6

Offf iğrenç, bu haberi şişko parmaklariyla ağzından salyalar akarak yazdığını hayal ettim.

Akit yazarından 3. havalimanı işçilerine: Bu itler, bitlendik diyorsa biber gazı sıkıp içlerindeki şeytanı çıkartacaksın

1K
1K
1K
0
1
6
We leverage educational videos where narrators use mouse pointers to show histopathological concepts. By capturing these pointer gestures, we effectively localize captions within the images, creating visually localized captions, and thereby generating spatially aware Q&A pairs.
1
0
6
@giffmana
@sainingxie
@endernewton
@inkynumbers
We show that a similar reconstruction-based objective works pretty well on CNN+Transformer in a multi-modal setting! We published our preprint 2 months ago using internal Amazon data, now the results are coming with the open-source data so stay tuned!
2
0
6
Thank you
@thibaudz
, for covering our work!
Please see the following thread for more information!

amazon broke the game of clothing tools... and it'll be not only for clothes
the best part? they ll release the code!
14
43
268
2
0
4
In Complex Reasoning, given a caption, alongside a diagnosis and supporting facts, we prompt GPT-4 in a diagnostic reasoning task designed to extrapolate beyond the immediate context of the given patch’s caption, while anchoring it to the facts extracted from the entire video.

1
0
5
Our code, model, and demo will be available soon, so please stay tuned! Extremely thankful to my amazing manager Karim Bouyarmane and the team at
@AmazonScience
for this opportunity to work on cutting-edge research in generative AI!
1
0
4
Tankımızı da ABD üretti :d
Saadet Partisi lideri: Tankımızı vuran füzeyi ABD üretmiş; Papa, Müslümanlardan özür dileyecek mi?

7
6
8
0
1
5
To evaluate Quilt-LLaVA, we not only used public VQA pathology datasets but also developed Quilt-VQA, which is derived from naturally occurring questions and answers in our videos, comprises 1283 Q&A pairs, curated using GPT-4 and custom algorithms for a comprehensive evaluation.

1
0
5
For training, we initialized Quilt-LLaVA with general-domain LLaVA, involving two stages: Histopathology Domain Alignment with the Quilt dataset and instruction-tuning on Quilt-Instruct. We utilize LLaMA-7b and QuiltNet as our text and image encoders, respectively.

1
0
4

Introducing two novel prompting techniques to generate instruction-tuning data from videos: Complex Reasoning and Iterative Abductive Reasoning, enabling GPT-4 to extrapolate diagnosis from captions and facilitate conversations between two GPT-4 agents for diagnostic insights.
1
0
5
This is a joint work with amazing folks at
@AmazonScience
: Maria Zontak, Bahar Erar Hood, Xu Zhang, Erran Li, Suren Kumar, and Karim Bouyarmane.
Stay tuned for the official announcement, which will include more details. Feel free to reach out anytime!
See you all in Seattle! 🎡
0
0
4
15000 personel 7000 enkazdan nasil insan kurtaracak? Bina basina 2 kisi ile nasil arama kurtarma yapilacak? Degil 15, 150 bin kisi bile yeterli degil. 450-500 bin kisinin seferber olmasi, ordunun erleriyle birlikte goreve dahil olmasi sart. Milletin akliyla alay mi ediyorsunuz?

AFAD: Ulaşılamayan bölge yok. 15 bin personel sahada.
3K
942
19K
0
2
4
Make EE great again

We figured out why the "positional encoding" used in NeRF works so well! NTK theory says that using an MLP with a Fourier basis yields a composed kernel that is good at interpolating (as per basic signal processing). Excited to see what people do with this
19
260
1K
0
0
4
Şimdi nükleer savaş çıkıyor mu çıkmıyor mu ona göre spora gidecem
1
0
4
This opportunity comes once in a lifetime yo
AKP'li vekilin kızı Zeytin Dalı Harekâtı için İngilizce rap şarkı yazdı: Kötü haber Trump, Erdoğan seni kramp yapacak

12
9
13
1
0
4
By placing the reference product directly into the user image, we approximate its appearance. A secondary UNet encoder processes this collage, generating pixel-level product signals, which are then modulated to the main UNet decoder via affine transformations using a FILM layer.

1
0
2

Yeni Türkiye'nin bana öğrettiği bazı kelimeler : Mazbata, sehven, derdest.
0
0
4
Learning with Local and Global Consistency algoritması için Google'a LLGC yazmam ve sonuç olarak London Lesbian and Gay Centre çıkması
0
0
3
@arankomatsuzaki
@MetaAI
We show that a similar reconstruction-based objective works pretty well on CNN+Transformer in a multi-modal setting! We published our preprint 2 months ago using internal Amazon data, now the results are coming with the open-source data so stay tuned!
2
0
3
Thank you,
@MariaZontak
, for doing the heavy lifting in organizing this workshop, and thanks to the rest of the team at
@AmazonScience
!
0
0
3
@Mr_AllenT
Thank you for covering our work!
Please see the following thread for more information!
Also, please consider following me so you won't miss it when we share the codebase and the model 😅
Excited to share our latest work from my
@AmazonScience
internship: Diffuse2Choose, which is a zero-shot diffusion model that enables "Virtual Try-All" – the ability to virtually try on any e-commerce item!
🌎:
📜:
A 🧵:
9
13
61
3
0
3
Simply choose a product, take a picture of the desired location, Dreampaint then generates a realistic representation of the product in that location blending it with the surrounding environment. It's a hassle-free way to preview how products will look in any setting.
2/5

1
0
2
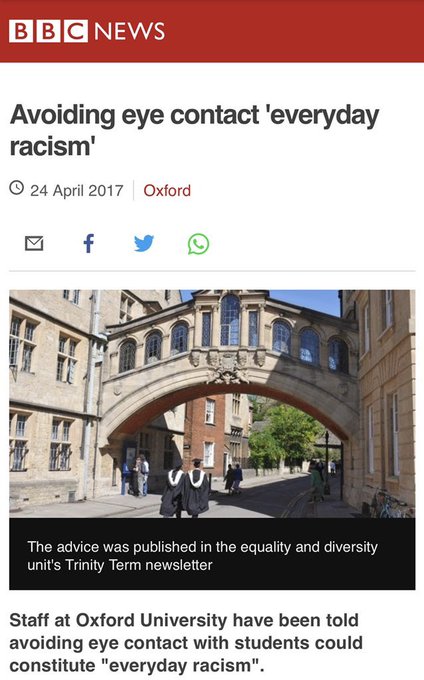
lol

Eye contact is sexist.
Avoiding eye contact is racist.
Take your pick.

604
4K
15K
0
0
3
Dr. Sahin said he and Dr. Türeci learned about efficacy data on Sunday night and marked the moment by brewing Turkish tea at home. “We celebrated, of course,” he said. “It was a relief.

Meet Drs. Ugur Sahin and Özlem Türeci, the husband-and-wife team that founded the German company BioNTech, which has worked with Pfizer on a coronavirus vaccine found to be more than 90 percent effective.
112
1K
8K
1
0
3
Please come and see the QUILT oral today at 4 PM in Ballroom A-C, or find
@wizdom_dominic
,
@fghezloo
, and myself at our poster session in Hall B1+B2 at
#301
around 5 PM!
Introducing Quilt-1M: One Million Image-Text Pairs for Histopathology. With Quilt-1M we propose a new source (video) and pipeline for collecting medical multimodal data!
📜:
💻:
🌎:
Demo:
5
31
110
0
1
3
Bu dönem yanlışlıkla tüm okula mail atan 1. sınıfların sayısında gözle görülür bir artış var. Acaba niye ?
1
0
3
Ben sizin boktan seçim şarkılarınızı dinlemek zorunda mıyım ulan ? Bari bir şeye benzeseler
2
0
3
😁


0
0
3
DreamPaint generates much better images compared to text-only or image-only guidance models as it preserves the fine-grained details of e-commerce items.
4/5

1
0
2
@alexcarliera
Thank you
@alexcarliera
, for covering our work! Please see the following thread for more information!
Also, please consider following so you won't miss it when we share the codebase and the model 😅
Excited to share our latest work from my
@AmazonScience
internship: Diffuse2Choose, which is a zero-shot diffusion model that enables "Virtual Try-All" – the ability to virtually try on any e-commerce item!
🌎:
📜:
A 🧵:
9
13
61
1
0
3
A neat trick of combining Masked Dreambooth and Inpainting modules allows us to learn e-commerce items as unique entities through a few-shot fine-tuning of our U-Net model.
3/5

1
0
2
Unlike recent virtual try-on literature, Diffuse2Choose can handle in-the-wild examples! Also, it is not limited to clothes but can also generate furniture, accessories, and more. Hence, it's a Virtual Try-All model!

1
0
2

Rusya'nın güncel durumu = sırf adam dövmek için vücut çalışan apaçi ergen
0
0
2
Batman'i altın kafese koymuşlar ille de vatanım demiş

0
0
2
Americans are losing their minds because they think $2 per hour is too low for a data annotation job in Kenya. It's slightly higher than the minimum wage in Turkey, which has 5x GDP per capita than Kenya. $2 per hour is probably middle-class wage there so it isn't a sweatshop.

🚨Exclusive: OpenAI used outsourced Kenyan workers earning less than $2 per hour to make ChatGPT less toxic, my investigation found
(Thread)
305
9K
19K
2
0
3
Bu belge gerçek mi sorusuna " Valla bizi bölmek isteyen dış mihrakların oyunu" diye cevap veren Jorah reyiz oradan kovulduysan Türkiyeye gel
0
1
1
Bu coğrafyaya özgü şeyler vol 10928: Deprem olunca camdan atlanması.
0
0
2
@thibaudz
Thank you for covering our work!
Please see the following thread for more information!
Also, please consider following me so you won't miss it when we share the codebase and the model 😅
Excited to share our latest work from my
@AmazonScience
internship: Diffuse2Choose, which is a zero-shot diffusion model that enables "Virtual Try-All" – the ability to virtually try on any e-commerce item!
🌎:
📜:
A 🧵:
9
13
61
2
0
2
@natanielruizg
Awesome work
@natanielruizg
! We did use "almost" the exact same architecture for virtual try-on inpainting approach earlier
Maybe you guys have missed it. We'd appreciate if you guys could cite us in the camera-ready version of the paper :)
0
0
2
Yine birileri doğalgaz kaçağını çakmakla kontrol etmeye çalışırken havaya uçmuş. İşte bunlar hep doğal seleksiyon
0
0
2
@gijigae
Thank you
@gijigae
, for covering our work!
Please see the following thread for more information!
Also, please consider following so you won't miss it when we share the codebase and the model 😅
Excited to share our latest work from my
@AmazonScience
internship: Diffuse2Choose, which is a zero-shot diffusion model that enables "Virtual Try-All" – the ability to virtually try on any e-commerce item!
🌎:
📜:
A 🧵:
9
13
61
0
1
2


We compare against both text-guided and image-guided inpainting modules and show that DreamPaint yields superior performance in both subjective human study and quantitative metrics.
5/5


0
0
2
@berrymerryy
@moordia
Sen 3 milyar 750 milyon sen milyar sen para çekmişsin sen bu parayı sen ne yaptın ?
0
0
2
Gold & Dollar: How Money Became Worthless | Currencies Explained | Docum...
@YouTube
aracılığıyla
0
0
1
Neat trick!
FreeU: Free Lunch in Diffusion U-Net
paper page:
we uncover the untapped potential of diffusion U-Net, which serves as a "free lunch" that substantially improves the generation quality on the fly. We initially investigate the key contributions of the
9
157
756
0
0
1
Recoil testing for pubg

toplu bir delilik hali:
bursa’da muhtarlara kalaşnikoflu silah eğitimi...

96
766
1K
0
0
1
@_akhaliq
How is this any different than DreamPaint?
Isn't it just masked Dreambooth for inpaint/outpainting? I guess it's cool not to cite preprints anymore.
DreamPaint: Few-Shot Inpainting of E-Commerce Items for Virtual Try-On without 3D Modeling
abs:
0
18
84
0
0
1
@ErenHamurcu
@LiberalDemokrat
LDP elit insanların partisi, sen LDP'ye versen benim vermemin anlamı kalmayacaktı karşim ;)
0
0
1
@Scobleizer
Thank you for covering our work!
Please see the following thread for more information!
Also, please consider following so you won't miss it when we share the codebase and the model 😅
Excited to share our latest work from my
@AmazonScience
internship: Diffuse2Choose, which is a zero-shot diffusion model that enables "Virtual Try-All" – the ability to virtually try on any e-commerce item!
🌎:
📜:
A 🧵:
9
13
61
0
0
1
Kömür madenine sahip çıkamayanlar nükleer reaktör kurmak istiyor
0
0
1
1
0
1