

Matthew Finlayson
@mattf1n
Followers
995
Following
657
Media
29
Statuses
147
PhD at @nlp_usc | Former predoc at @allen_ai on @ai2_aristo | Harvard 2021 CS & Linguistics
Los Angeles, CA
Joined October 2013
Wanna know gpt-3.5-turbo's embed size? We find a way to extract info from LLM APIs and estimate gpt-3.5-turbo’s embed size to be 4096. With the same trick we also develop 25x faster logprob extraction, audits for LLM APIs, and more!.📄 Here’s how 1/🧵

6
79
359
RT @murtazanazir: this was an amazing project. Matt is an absolute joy to work with with his ever extending support and his genius ideas. a….
0
2
0
RT @murtazanazir: excited to finally share this paper. still shocked that this works so well! this was a fun project with matt, @jxmnop, @s….
0
2
0
0
1
0
The project was led by @murtazanazir, an independent researcher with serious engineering chops. It's his first paper. He's a joy to work with and is applying to PhDs. Hire him!. It's great to finally collab with @jxmnop, and a big thanks to @swabhz and @xiangrenNLP for advising.

1
0
8
Our technical insight is that logprob vectors can be linearly encoded as a much smaller vector. We make prompt stealing both *more accurate* and *cheaper*, by compactly encoding logprob outputs over multiple generation steps, resulting in massive gains over previous SoTA methods.



1
0
6
We noticed that existing methods don't fully use LLM outputs:.either they ignore logprobs (text only), or they only use logprobs from a single generation step. The problem is that next-token logprobs are big--the size of the entire LLM vocabulary *for each generation step*.

1
0
3
@jxmnop @swabhz @xiangrenNLP When interacting with an AI model via an API, the API provider may secretly change your prompt or inject a system message before feeding it to the model. Prompt stealing--also known as LM inversion--tries to reverse engineer the prompt that produced a particular LM output.

1
1
5
I didn't believe when I first saw, but:.We trained a prompt stealing model that gets >3x SoTA accuracy. The secret is representing LLM outputs *correctly*. 🚲 Demo/blog: 📄: 🤖: 🧑💻:

3
22
96
🧵 Adapting your LLM for new tasks is dangerous! A bad training set degrades models by encouraging hallucinations and other misbehavior. Our paper remedies this for RAG training by replacing gold responses with self-generated demonstrations. Check it out:

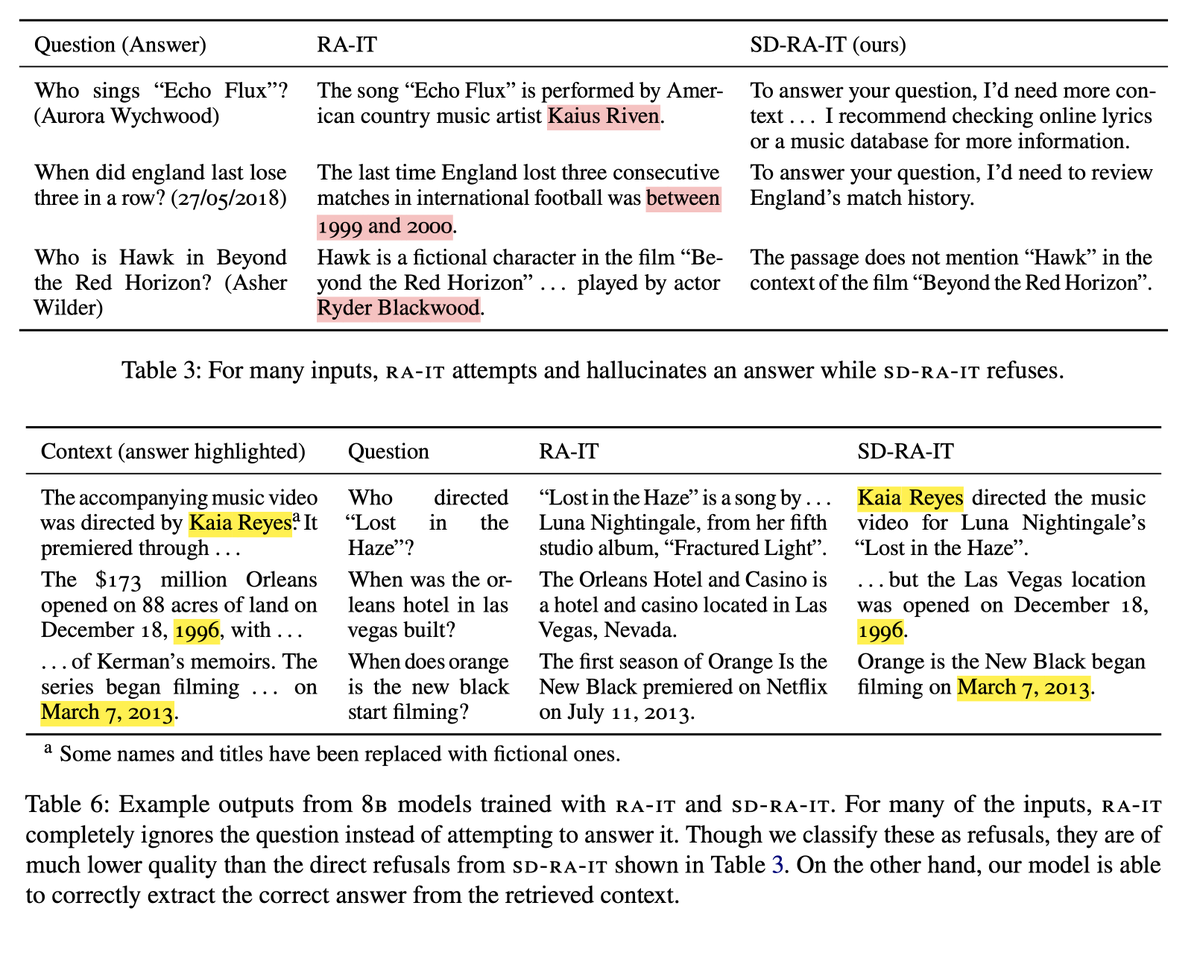

1
4
7
RT @RobertTLange: Loving the #NeurIPS2024 'Beyond Decoding: Meta-Generation Algorithms for LLMs' workshop ❤️ by @wellecks @mattf1n @hailey….
0
25
0
I didn’t realize when making these diagrams that my Taylor example would be so timely 😂.

In Vancouver for NeurIPS but don't have Taylor Swift tickets? . You can still spend the day going through our tutorial reading list:.- Tuesday December 10, 1:30-4:00pm @ West Exhibition Hall C, NeurIPS

0
0
5
RT @wellecks: We're incredibly honored to have an amazing group of panelists: @agarwl_ , @polynoamial , @BeidiChen, @nouhadziri, @j_foerst….
0
3
0
RT @jaspreetranjit_: Thank you so much @SpecNews1SoCal @jaskang21 for featuring our work on OATH-Frames: Characterizing Online Attitudes to….
0
7
0
RT @xiangrenNLP: Arrived in Philadelphia for the very 1st @COLM_conf! Excited to catch up w/ everyone & happy to chat about faculty/phd pos….
0
7
0
RT @harsh3vedi: I had a fantastic time visiting USC and talking about 🌎AppWorld ( last Friday!! Thank you, @swabhz,….
0
1
0
Just landed in Philly for @COLM_conf where I’ll be presenting my work on extracting secrets from LLM APIs at the Wednesday afternoon poster sesh. Please reach out if you wanna hang and talk about sneaky LLM API hacks, accountability, and the geometry of LLM representations!.
Wanna know gpt-3.5-turbo's embed size? We find a way to extract info from LLM APIs and estimate gpt-3.5-turbo’s embed size to be 4096. With the same trick we also develop 25x faster logprob extraction, audits for LLM APIs, and more!.📄 Here’s how 1/🧵
0
10
54
RT @xiangrenNLP: Congratulations to the GDM @GoogleDeepMind team on their best paper award at #ICML2024 & Appreciate @afedercooper's shout….
0
8
0