
Xilun Chen
@ccsasuke
Followers
550
Following
177
Media
17
Statuses
726
Research Scientist @ Meta FAIR
Seattle, WA
Joined March 2010
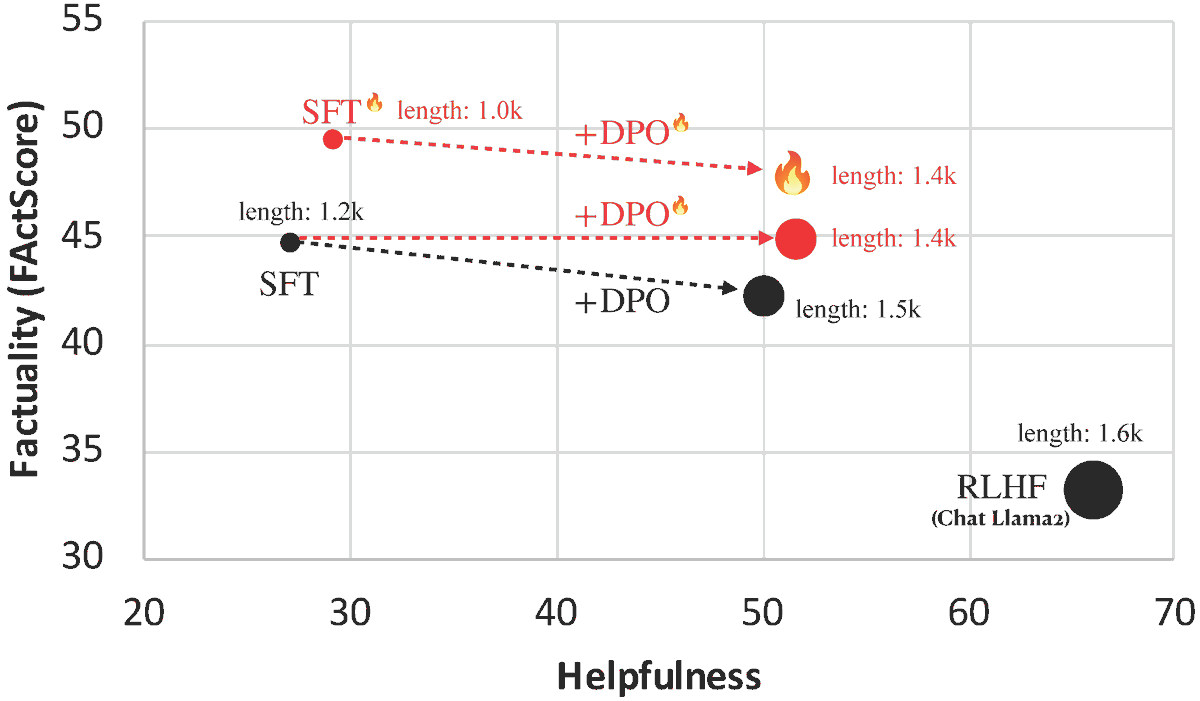
Introducing FLAME🔥: Factuality-Aware Alignment for LLMs. We found that the standard alignment process **encourages** hallucination. We hence propose factuality-aware alignment while maintaining the LLM's general instruction-following capability.
3
9
33
RT @xueguang_ma: Now accepted by #ACL2025 main. We propose a training framework to generate strong smaller retriever with integration of L….
0
8
0
RT @RulinShao: Accepted by #ACL2025! Congrats @mingdachen and the team🥳.Several cool ideas:.- Maintain an explicit editable working memory….
0
12
0


Today we released DRAMA, a set of small (sub-1B) multilingual dense retrievers that perform strongly across multiple languages and tasks. It also offers flexible model sizes and embedding dimensionalities. Led by my awesome intern @xueguang_ma .

Introducing DRAMA🎭: Diverse Augmentation from Large Language Models to Smaller Dense Retrievers. We propose to train a smaller dense retriever using a pruned LLM as the backbone, fine-tuned with diverse LLM data augmentations. With single-stage training, DRAMA achieves strong

0
2
13
RT @sriniiyer88: New paper! Byte-Level models are finally competitive with tokenizer-based models with better inference efficiency and robu….
0
22
0
RT @jacklin_64: I will present our paper FLAME on factuality alignment for LLMs with @luyu_gao at #NeurIPS2024! 🎉 Join us at East Exhibit H….
0
5
0
RT @AkariAsai: 🚨 I’m on the job market this year! 🚨.I’m completing my @uwcse Ph.D. (2025), where I identify and tackle key LLM limitations….
0
118
0
RT @alexlimh23: 1/ Excited to share that our paper "NEST🪺: Nearest Neighbor Speculative Decoding for LLM Generation and Attribution" is acc….
0
7
0
RT @_jasonwei: Excited to open-source a new hallucinations eval called SimpleQA! For a while it felt like there was no great benchmark for….
0
125
0
RT @liliyu_lili: 🚀 Excited to share our latest work: Transfusion! A new multi-modal generative training combining language modeling and ima….
0
17
0
RT @real_asli: 🚀 Exciting news! We're open sourcing Chameleon, our early fusion multimodal foundation model from last year. It handles mult….
0
6
0
RT @VictoriaLinML: 💫 Excited to introduce NEST: Nearest Neighbor Speculative Decoding (, the latest work led by our….
0
11
0
RT @arankomatsuzaki: Meta presents Nearest Neighbor Speculative Decoding for LLM Generation and Attribution. Significantly enhances the gen….
0
60
0
RT @alexlimh23: Curious about enhancing factuality and attribution in LLM generation? Check out our paper: Introdu….
0
16
0