
Konstantin Schürholt
@k_schuerholt
Followers
776
Following
7K
Media
18
Statuses
788
AI Researcher at @ndea. Previously postdoc on weight space learning @ University of St.Gallen, Switzerland.
Joined July 2019
#NeurIPS2022 HyperNetworks have seen a revival in #stablediffusion these days (@hardmaru). Turns out you can now generate weights even unsupervised :) using generative #hyper_representations trained on populations of neural networks - with @damianborth @DocXavi @BorisAKnyazev

4
39
297

Good research is mostly about knowing what questions to ask, not about answering questions that other people are asking.
20
59
628
We've recapped all our 30-day learnings in a full post https://t.co/t76IYmIlWT

arcprize.org
One Month of Learnings Building Interactive Reasoning Benchmarks
1
3
43

.@k_schuerholt was the driver behind last weeks Hierarchical Reasoning Model blog post I saw him give an internal presentation to the team about his work and said "this has to be recorded for the public" He re-recorded it and released it Great watch

The Surprising Performance Drivers of HRM. A paper talk from Ndea AI researcher @k_schuerholt. We ran a series of ablation studies to determine what factors had the biggest impact on the Hierarchical Reasoning Model's performance on ARC-AGI.
4
2
28
The Surprising Performance Drivers of HRM. A paper talk from Ndea AI researcher @k_schuerholt. We ran a series of ablation studies to determine what factors had the biggest impact on the Hierarchical Reasoning Model's performance on ARC-AGI.
11
22
101


Shout out to the authors of the HRM paper @makingAGI for engaging in the discussion with us and sharing their previous experiments. There’ll be a longer video explaining our findings early next week.
0
0
10
In their experiments, few-shot examples work great on large datasets, but don't work well on small scale datasets like ARC. Puzzle embeddings present obvious limitations for generalization, but seem like a very interesting starting point for future work.
1
0
9
5. Task embeddings seem critical for HRM’s learning efficiency. HRM uses embedding layers for unique task-ids rather than GPT-3 style few-shot example contexts. We did not run these experiments ourselves, but the authors kindly shared their experience.
1
0
6
4. Data augmentations matter, but significantly less than the 1000 per task proposed in the paper are sufficient. As with the outer loop, training with augmentations has a bigger impact than using augmentations at inference time to get a more predictions for the same task.

1
0
7
Side note: that outer refinement loop is similar to the Universal Transformer https://t.co/HWvC2HugVj by @m__dehghani @sgouws @OriolVinyalsML @kyosu @lukaszkaiser (shout out to @ClementBonnet16 for the pointer).

arxiv.org
Recurrent neural networks (RNNs) sequentially process data by updating their state with each new data point, and have long been the de facto choice for sequence modeling tasks. However, their...
1
0
11
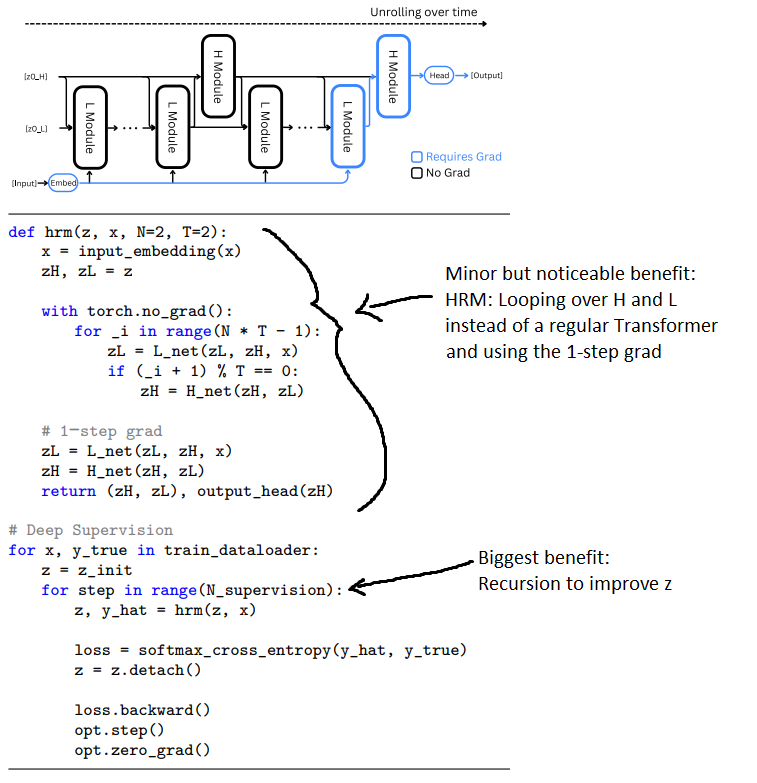
3: The outer loop makes a dramatic difference. From 1 outer loop to 2 boosts by 13pp, from 1 to 8 doubles performance. Interestingly, refinement loops seem more important during training than during inference. Models trained with refinement have better one-shot performance.


1
0
7
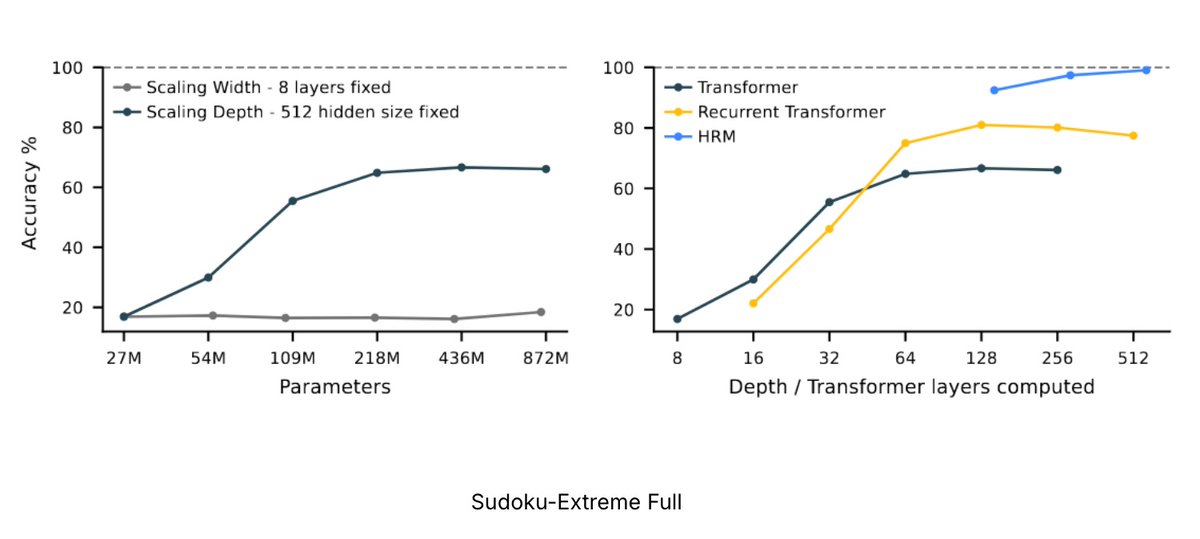
2: The hierarchical component of the model had only minimal impact on overall performance. Swapping the HRM model with a regular transformer got within a few percentage points on arc v1 public eval. The hierarchical inner loops help, but don’t explain the overall performance.

1
0
9
1. Scores on ARC (pass@2): * ARC-AGI-v1: public: 41%, semi-private: 32% * ARC-AGI-v2: public 4%, semi-private: 2% The public scores are in line with what the authors had reported. v1 scores are good for a small model trained only on arc-data. Drops on semi-private are expected.

1
0
6
We took a closer look at Hierarchical Reasoning Models by @makingAGI. We verified scores and pulled it apart to understand what makes it work. Main take-aways below, full story here:
arcprize.org
We scored on hidden tasks, ran ablations, and found that performance from the Hierarchical Reasoning Model comes from an unexpected source
4
14
157

Summary of the findings for the Hierarchical Reasoning Model on ARC

Analyzing the Hierarchical Reasoning Model by @makingAGI We verified scores on hidden tasks, ran ablations, and found that performance comes from an unexpected source ARC-AGI Semi Private Scores: * ARC-AGI-1: 32% * ARC-AGI-2: 2% Our 4 findings:

13
96
814
Analyzing the Hierarchical Reasoning Model by @makingAGI We verified scores on hidden tasks, ran ablations, and found that performance comes from an unexpected source ARC-AGI Semi Private Scores: * ARC-AGI-1: 32% * ARC-AGI-2: 2% Our 4 findings:
39
203
1K
What makes the HRM model work so well for its size on @arcprize? We ran ablation experiments to find out what made it work Our findings show that you could replace the "hierarchical" architecture with a normal transformer with only a small performance drop We found that an

14
87
842

Blaise Agüera explains interrelated paradigm shifts which he believes are core to the future development in AI. I like his take on collective intelligence, the future of artificial life research, and the (somewhat philosophical) discussions about consciousness and theory of mind.

0
5
37
New Essay by @BlaiseAguera (@Google): “AI Is Evolving — And Changing Our Understanding Of Intelligence” Advances in AI are making us reconsider what intelligence is and giving us clues to unlocking AI’s full potential. https://t.co/PEzHQmoB9z

noemamag.com
Advances in AI are making us reconsider what intelligence is and giving us clues to unlocking AI’s full potential.
9
34
178