

Alexia Jolicoeur-Martineau
@jm_alexia
Followers
19K
Following
30K
Media
151
Statuses
9K
Senior AI Researcher at the Samsung SAIT AI Lab 🐱💻 I build generative AI for images, videos, text, tabular data, weights, molecules, and video games.
Montréal, Québec
Joined March 2017
New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs. Blog: https://t.co/w5ZDsHDDPE Code: https://t.co/7UgKuD9Yll Paper:

arxiv.org
Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on...
136
651
4K
RWKV7+ROSA 1M params solving 40 digits +/- with 99% digit accuracy, without CoT 🌹 demo: https://t.co/j0eFQDISvu

RWKV7 vs RWKV7+ROSAv251020 vs RWKV7 + ROSAv251021 (same arch¶ms as v251020, better training method) 🚀
6
13
93

🚨 ATTN. New Jersey: We can do SO much better than Mikie Sherrill. She voted against the child tax credit… She voted for tax hikes… She voted to give your money to illegals… Reject her on Nov. 4th.
75
191
556

What's most interesting to me about the HRM and TRM results on ARC-AGI is that these approaches leverage zero external knowledge (either pretraining knowledge or hardcoded priors, such as those found in an ARC-specific DSL). TRM is the public SotA for such approaches. The lack
41
47
544
@jm_alexia @ritteradam Well, further scaling from 448 to 896 still yields a slight performance gain, but as you can imagine, the computation time becomes insane (on 4 L40s, batch size = 768). The Pareto frontier between performance and efficiency could definitely be improved.
2
1
21

Looks like Sam Altman's Neuralink competitor, Merge Labs, is about to announce. The FT reported in August they were raising $250m at a $850m valuation, most of that capital coming directly from OpenAI. Sam will co-found Merge. They plan to alter neurons through gene therapy, then

During a recent talk, Shapiro said his mission is “to develop ways to interface with neurons in the brain and cells elsewhere in the body that would be less invasive” He’s joining Altman’s BCI startup, which I’m told will be announced soon
45
59
712

The scariest stories this October aren’t fiction—they’re funded. Read the new Capital Research magazine issue on our website!
0
0
8

New blog post! This one is a purely theoretical one attempting identifying the central reason why LLMs suffer from mode collapse in RL and fail to generate novel or truly diverse outputs. It's actually a way more complicated problem than you think! Naively encouraging
23
60
551
This is legit insane and it makes so much sense. This idea will be a key piece for true machine intelligence.
3
4
95
Insane finding! You train on at most 16 improvement steps at training, but at inference you do as many steps as possible (448 steps) and you reach crazy accuracy. This is how you build intelligence!!

@jm_alexia @ritteradam Indeed, @jm_alexia @ritteradam I also find that simply increasing the number of inference steps, even when the model is trained with only 16, can substantially improve performance. (config: TRM-MLP-EMA on Sudoku1k; though the 16-step one only reached 84% instead of 87%)
16
34
381
I built a Continuous Attractor Network with 3 motor neurons which learn to guide the mice towards food using Reward‑modulated Hebbian plasticity No backpropagation and no SGD. In this case at first, the networked learned to circle around the food 😯 Source code is open

Spiking Neural Network from scratch achieves 8% accuracy. no backpropagation or SGD I created a genetic hyper parameter optimizer and it now, on average, can get 8% accuracy which is ~3% above chance Link to source code with a detailed video and markdown explanations in comment
37
92
1K


A new Latent Diffusion Model without VAE from Kuaishou Technology is here! Introducing SVG: it ditches the VAE for self-supervised representations, enabling 62x faster training & 35x faster inference, all while boosting generative quality.
8
55
307

@jm_alexia Hey Alexia, congrats, your model is amazing! I could improve the Sudoku-Extreme example from 87% to 96% by improving on the evaluation, but the results so far haven't translated to the ARC dataset, because the q heads are not accurate enough there.
2
7
78
Look at what my wife surprised me with, she's a menace! https://t.co/HVbNVW9P6f
linkedin.com
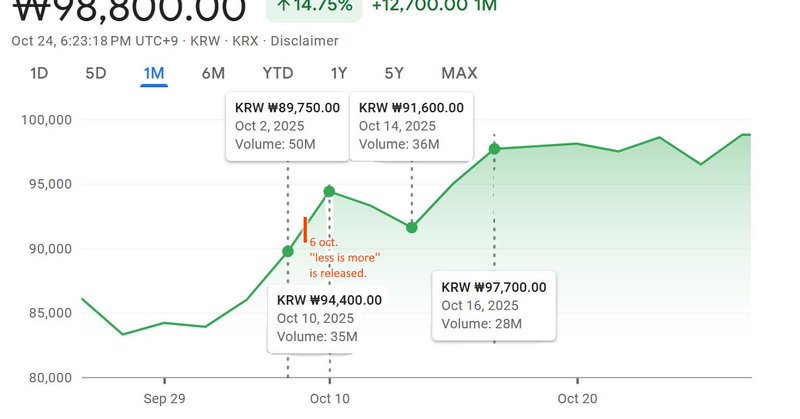
Contextual facts for people unfamiliar with the korean market: Between the 3rd of October (Gaecheonjeol(National Foundation Day)) and the 9th of October (Hangeulnal(Hangeul Proclamation Day)),...
4
5
63

>crashes the biggest videogame economy from 6 billion dollars down to 3 billion in less than 2 days >makes thoudsands of traders face financial ruin >makes all knives affortable for regular users >goes back to his yacht to play Dota 2 Based Gabe

692
6K
118K

Security Onion 2.4.190 now available including Onion AI Assistant! Introducing the all-new Onion AI, an advanced LLM-based security analyst assistant, built directly into the Security Onion console. Designed BY defenders FOR defenders!
1
6
12

Congratulations @Yoshua_Bengio!! Possibly the first scientist with one million citations in the world. Crazy how fast the field has grown 🤯
76
371
5K

a great way to limit your growth is to think everything is already solved

if you are thinking along the lines of the sakana cto i implore you to realize - you are not the first person to think this - you're not even the 100th person to think this and you're going to need to think more OOD than slapping an evolutionary algorithm on top to make a dent
7
7
350

Tiny Reasoning Language Model (trlm-135) - Technical Blogpost⚡ Three weeks ago, I shared a weekend experiment: trlm-135, a tiny language model taught to think step-by-step. The response was incredible and now, the full technical report is live:
shekswess.github.io
Exploring the capabilities of Tiny Language Models to reason and understand complex tasks.
11
75
538


Introducing DOJE: The first U.S. memecoin ETF giving you spot exposure to Dogecoin via a traditional ETF.
3
42
86

I got my paper for this weekend folks we are going to figure out how this fish library is able to crank up RL to 1M steps per seconds without spending the equivalent in compute of a small slavic country gdp
31
43
818

Yann Lecun: Since early 2023, and until recently, Llama 2, 3 and 4 have been in the hands of GenAI Yuandong Tian: our team (FAIR) put down all the research we are currently doing, was (forced?) to move to GenAI <2 months before the llama 4 release Meta is vibe managing & firing
42
56
828

Had some really interesting discoveries recently: If a model performs extremely stable on one benchmark. Let's say a model is always getting 62% on SWEBench no matter what prompts or scaffold you used. It DOES NOT mean that the model is robust. It actually means that the model
12
15
253

Meta has gone crazy on the squid game! Many new PhD NGs are deactivated today (I am also impacted🥲 happy to chat)

Several of my team members + myself are impacted by this layoff today. Welcome to connect :)
112
94
2K