
Dougall
@dougallj
Followers
3K
Following
12K
Media
136
Statuses
3K
he/they | mastodon: https://t.co/d5YdiePIr8 / @[email protected]
Joined February 2007
0
0
2




very sad that cohost is going. maybe its unique genre of posting, the css crime, will go with it. well, i'm glad that there's this worthy goodbye to it
0
1
17

After 27 years of providing in-depth coverage of the amazing world of PC and mobile hardware, AnandTech is saying farewell. We want to thank everyone from the AnandTech community for their support and passion for what we’ve done over the years https://t.co/3EGh4FJguE
forums.anandtech.com
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
433
1K
7K

CRC checksum is not a cryptographic hash function. It is easy to add a few bytes of garbage at the end of a file so that the CRC of the entire file becomes a desired value. But did you need to do that in the linker? Yes. https://t.co/Wu7gU2j5Hb
3
15
110

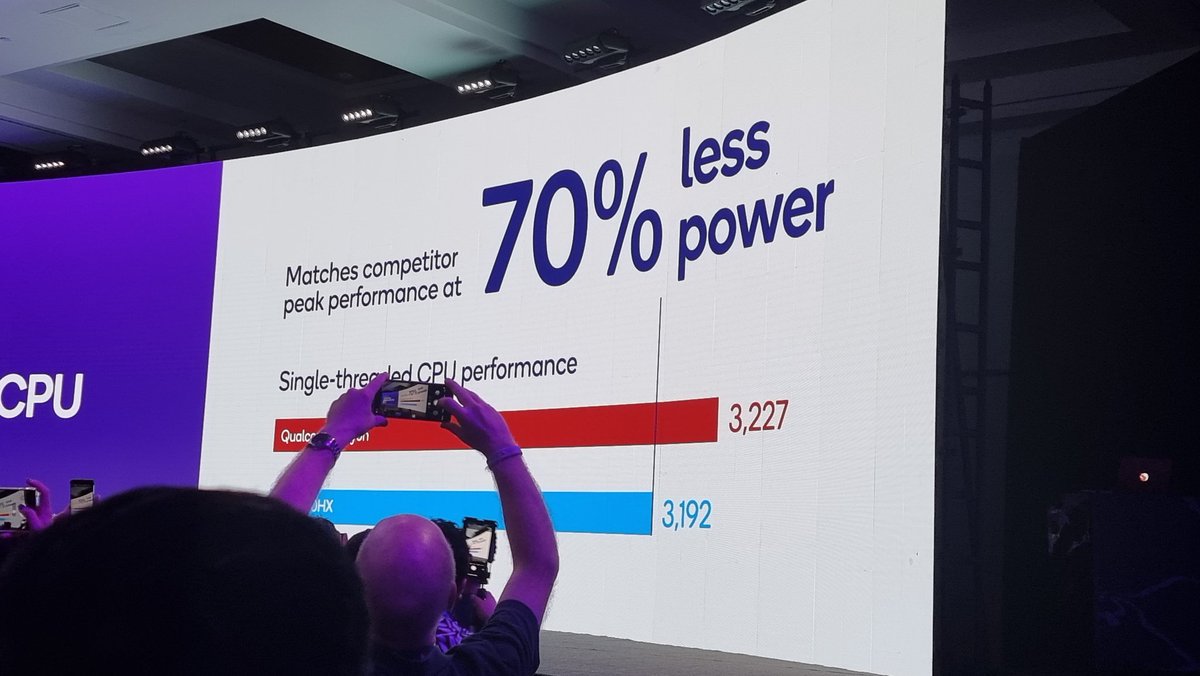
Analysis of the M4 by @techinsightsinc „key design choice in the Apple M4 is the use of TSMC's high-performance standard cell library for CPU1“ …“UHD libraries for GPU and CPU2“ aka TSMC FinFlex CPU1: P-Cores CPU2: E-Cores https://t.co/DMuS9Tkg3h

9
61
380


Intel is now essentially following Apple's design philosophy, with an integrated memory architecture, a large front-end, a large L1 cache, removal of SMT, 4+4 cores

39
96
1K


With Lisa's keynote over, I will casually drop this to confirm that y-cruncher v0.8.5 will get #Zen5 optimizations with it's big and fat #AVX512. Release date still ETA - pending final silicon. https://t.co/dohnqbg7Ex ST and BBP will be where the light shines the brightest.


y-cruncher's BBP digit extractor will turn into a proper benchmark for v0.8.5. It's a pure SIMD/AVX workload that doesn't touch memory. Why? The CPU/memory perf gap is becoming so large that the classic Pi benchmarks are turning into pure memory tests. https://t.co/jNWoc0sXKt

6
13
94

@dyaroshev @geofflangdale @HaroldAptroot @FUZxxl FWIW, I've also given it a decent write-up at https://t.co/lQoW9gnNMr. Only notable change is putting maskz on the shuffle rather than on the permutexvar, as https://t.co/V5fqZLYP4G suggests maskz costs a few cycles, so might as well put it on the cheaper of the two instructions.
corsix.org
1
8
23

Fantastical deep information about optimizing for Apple Silicon can now be found here:
7
31
168

Example of why power draw is a poor proxy for how well a program is utilizing your hardware (i7-7700K CPU in this case). In one case, execution port use is heavy and IPC is high, so the CPU's pipeline is running at high utilization. However power draw is low. Second case...

3
13
71

New blog post: "Entropy decoding in Oodle Data: x86-64 6-stream Huffman decoders"

fgiesen.wordpress.com
It’s been a while! Last time, I went over how the 3-stream Huffman decoders in Oodle Data work. The 3-stream layout is what we originally went with. It gives near-ideal performance on the las…
1
20
74





oh my god

hmm did the guy famous for baselessly accusing someone he didn’t like of being a “pedo guy” just suspend @JUNlPER after she did the same to him?


16
190
3K
* 8-bit floating-point, separately configurable to use E5M2 or E4M3 formats for different operands Scalar highlights: * "Checked pointer" add/sub/multiply-add/multiply-sub – for faster/safer top-byte-ignore? * New "enhanced" pointer authentication ops.
1
1
6
New Arm extensions just dropped: https://t.co/9tQFfJNPOH SIMD highlights: * LUTI2 and LUTI4 – powerful pshufb/tbl-like instructions, decoding bit-packed 2-bit or 4-bit indices to 8-bit or 16-bit values * Floating-point absolute min/max
2
9
35