

Christy Bergman
@cbergman
Followers
376
Following
123
Media
35
Statuses
350
AI DevAdvocate. I blog about AI, Machine Learning and wine. Tweets are my own
San Francisco, CA USA
Joined March 2008
Don't🍷about #OOM running out of memory!.@huggingface is making it easier to run huge #TransformerandDiffuser models on consumer GPUs w quantization, tensor parallelism, offloading. Hear from @stevhliu how to fit these models on your setup. #HuggingFace

0
0
1
RT @TDataScience: Thankfully @cbergman's article can help you identify key convos with an AI hack to perform semantic clustering simply by….
towardsdatascience.com
As a Developer Advocate, it’s challenging to keep up with user forum messages and understand the big picture of what users are saying. There’s plenty of valuable content — but how can you quickly...
0
2
0
RT @deepseek_ai: 🚀 Day 5 of #OpenSourceWeek: 3FS, Thruster for All DeepSeek Data Access. Fire-Flyer File System (3FS) - a parallel file sys….
0
1K
0
@TDataScience TL;DR my blog is about how to go from (data science + code) → (AI prompts + LLMs) for the same results—just faster and with less effort! . Here is the @TDataScience archive link:
towardsdatascience.com
As a Developer Advocate, it’s challenging to keep up with user forum messages and understand the big picture of what users are saying. There’s plenty of valuable content — but how can you quickly...
0
1
7
I just published a blog in #DataScienceCollective, the new free open version of @TDataScience. Here, I look at 9 different discords and prompt #LLMs to do #Clustering on user messages.
linkedin.com
500 million+ members | Manage your professional identity. Build and engage with your professional network. Access knowledge, insights and opportunities.
1
0
1
0
0
1
Seems devil is in the details for accuracy/latency tradeoff decisions. #w8a8fp: 1. Weights quantized using usual symmetric fp8 method. 2. Activations quantized without pre-calibration i.e. symmetric quantization parameters calculated on-the-fly during model inference.
0
0
0
🤔hmm, but this paper shows w8a8-fp (symmetric weight and dynamic per-token activation quantization in fp8) is "essentially lossless" in accuracy.
Interesting! The most common inference quantization int8/fp8 is not necessarily the best. bf16 #quantization is a way better accuracy/latency tradeoff.
1
0
0
Interesting! The most common inference quantization int8/fp8 is not necessarily the best. bf16 #quantization is a way better accuracy/latency tradeoff.

aidan bench update:. i ran llama 3.1 405b at bf16 (shoutout to @hyperbolic_labs) and we got a *way* better score. 405b fp8 is around gpt-4o-mini-level.405b bf16 beats claude-3.5-sonnet. give me bf16 or give me death
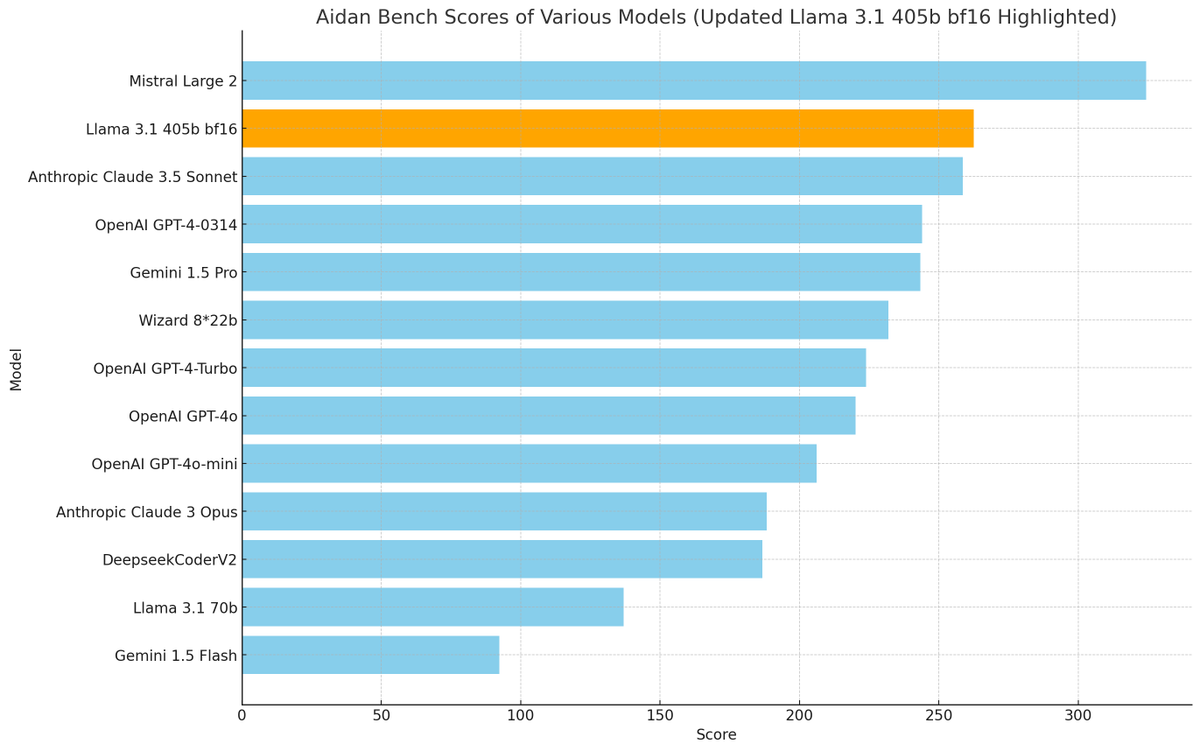
0
0
1
Nice to meet and chat w/you too! @adamse @felipehoffa It was fun to get some hands-on time and see what's new with @awscloud Bedrock.




0
1
3
I just tried this hack. Thanks, I really needed that! 😂.

Self-care life hack: if you feel a bit down/tired, paste the url of your website/linkedin/bio in Google's NotebookLM to get 8 min of realistically sounding deep congratulations for your life and achievements from a duo of podcast experts 😂
0
0
2
Interesting take-down how to do LoRA properly, quickly, with less memory, on all layers @danielhanchen's tweet and blog !.> For continued pretraining, I advise people to train on all layers (inc gate) + lm_head, embed_tokens, use RS LoRA, use rank>=256.
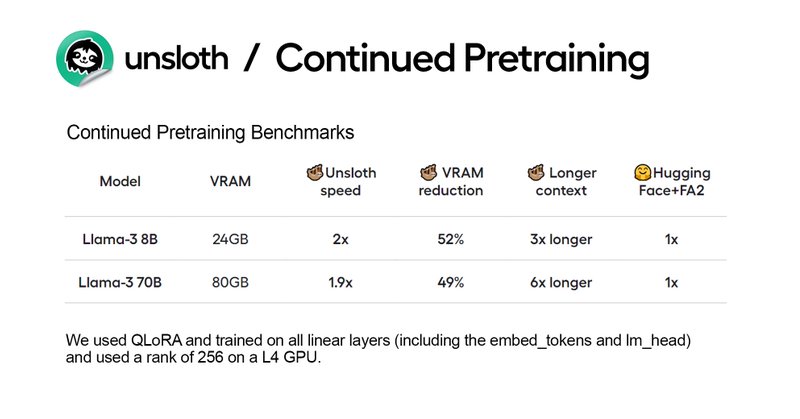
unsloth.ai
Make a model learn a new language by doing continued pretraining with Unsloth using Llama 3, Phi-3 and Mistral.

My take on "LoRA Learns Less and Forgets Less". 1) "MLP/All" did not include gate_proj. QKVO, up & down trained but not gate (pg 3 footnote). 2) Why does LoRA perform well on math and not code? lm_head & embed_tokens wasn't trained, so domain shifts not modelled. Also reason why

0
0
0
RT @AIconference: 🌟Join our expert panel at The AI Conference 2024 to explore advanced RAG (Retrieval-Augmented Generation) techniques. Le….
0
5
0
RT @zilliz_universe: Monday Meetup is right around the corner! 🗣 Join us in SF on August 5 for exciting talks: .🔢 Using Ray Data for Multim….
0
5
0
Thanks @TDataScience for the reshare! Iterate to find the best RAG combinations by: . Changing the Chunking Strategy 📦.Changing the Embedding Model 📷.Changing the LLM Model 📷. I made a video Thanks to @GregKamradt for the original chunking article!.

Learn how to adopt RAG best practices by incorporating evaluations into your pipeline: @cbergman covers the ins and outs of optimizing chunkings, embeddings, and more.
1
2
6
Had a blast creating this #MultiModal tutorial/demo! Used fun mix of tools for awesome results! 💡✨.🖼️@milvusio for the #VectorDatabase.🧠 a tiny Clip #EmbeddingModel by @ashvardanian.🤖 @chatgpt4o as the #LLM. Check it out! ➡️ #AI #MachineLearning.

🤯 📣 Weekend Project! Test out BOTH #multimodal and #multilingual capabilities by following this tutorial using #Milvus and #GPT4o. 🎥 @cbergman
1
0
10
RT @TDataScience: Learn how to adopt RAG best practices by incorporating evaluations into your pipeline: @cbergman covers the ins and outs….
0
14
0
🌟 Join us #SF #IRL this Monday! 🌟. Connect with speakers from #DSPy and chat with founders from @YCombinator cohorts diving into #UnstructuredData and #GenerativeAI. 👉🏼 Register here:
linkedin.com
500 million+ members | Manage your professional identity. Build and engage with your professional network. Access knowledge, insights and opportunities.
0
0
4