

Steven Liu
@stevhliu
Followers
902
Following
3K
Media
23
Statuses
181
docs @huggingface 🤗 | sucking at something is the first step towards being sorta good at something
Bay Area
Joined January 2019
Super excited to start my first day as a technical writer @huggingface! Feels like the first day of school all over again 🤗
11
9
186

The Jagged AI Frontier is a Data Frontier Wrote up my thoughts on how coding and math succeeded through data abundance and verification, why science lags behind, and how distillation equalizes the field while RL may just be another data generator. https://t.co/0bNRnIwk66
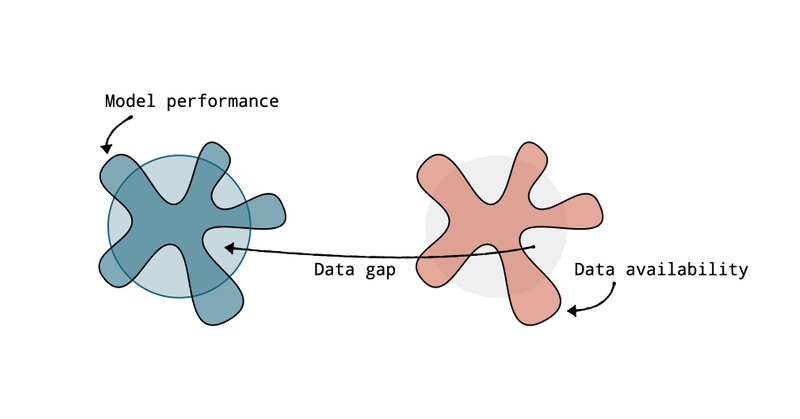
huggingface.co
10
39
300

Using AI to do more AI at HF. We added chatbot on every hf doc page so that one can get answers faster we are using open source embedding models & llms through hugging chat and one of our inference providers to serve answers
1
4
27
🪦text-generation-inference is now in maintenance mode. Going forward, we will accept pull requests for minor bug fixes, documentation improvements and lightweight maintenance tasks. TGI has initiated the movement for optimized inference engines to rely on a transformers
13
6
133
i'm printing out some commemorative stamps to celebrate transformers 5, let me know if you want some!

Transformers v5's first release candidate is out 🔥 The biggest release of my life. It's been five years since the last major (v4). From 20 architectures to 400, 20k daily downloads to 3 million. The release is huge, w/ tokenization (no slow tokenizers!), modeling & processing.
2
1
9


for anyone that had issues with tokenizers with a lot of added tokens, my gift is 10x faster loading :)

github.com
8-9x speedup on special tokens and about 4x on non-special cases for deserialization Fixes #1635 and superseeds #1782
0
1
22

Why are vLLM and transformers so damn fast? ⚡ Continuous batching. That's the secret sauce 🔥 Never heard of it? We just dropped a blog post building it up from first principles 🤗 See what happens inside the minds of the engineers pushing inference to the edge 🧠
4
34
192
After ~4 years building SOTA models & datasets, we're sharing everything we learned in ⚡The Smol Training Playbook We cover the full LLM cycle: designing ablations, choosing an architecture, curating data, post-training, and building solid infrastructure. We'll help you
36
163
1K

The main breakthrough of GPT-5 was to route your messages between a couple of different models to give you the best, cheapest & fastest answer possible. This is cool but imagine if you could do this not only for a couple of models but hundreds of them, big and small, fast and
120
158
2K
Likewise, claude code fetches Hugging Face’s docs markdown instead of html — reducing token usage by about an order of magnitude

When Claude Code fetches Bun’s docs, Bun’s docs now send markdown instead of HTML by default This shrinks token usage for our docs by about 10x
0
1
12

ring attention fixes this by passing K/V pairs from each GPU around in a ring, overlapping communication and computation. eventually, each GPU will have collected all the K/V shards it needs for attention a single GPU doesn't store the full K/V because they share the load
1
0
1
we have something cool coming your way in diffusers! context parallelism splits sequence length across GPUs, making it faster to generate images/videos. but splitting the attention module has issues of its own because each token needs to see the K/V pairs from all other token🤔
1
0
1

🔧 We’re working on refactoring transformers’ benchmarking suite to make it prettier, more meaningful, and more extendable. We’ll be measuring the standard metrics you want to see when talking about inference: - TTFT: time to first token, or the time it takes for the first
1
3
21

If you love open models, you’ll love this: Crush now runs with @huggingface Inference Providers 🤗✨
14
15
159
↳ a dispatch function routes your call to the correct backend ↳ if you don't select a backend, it defaults to PyTorch native scaled dot product attention, which selects the best backend based on inputs/hardware https://t.co/txu9eV99cd

huggingface.co
0
0
0
it has never been easier to use different attention backends (FlashAttention, SageAttention, etc) in Diffusers ↳ offers single interface for multiple backends ↳ each backend is logged in a registry (implementation, constraints, supported params)
1
0
3
Xet by Hugging Face is the most important AI technology that nobody is talking about! Under the hood, it now powers 5M Xet-enabled AI models & datasets on HF which see hundreds of terabytes of uploads and downloads every single day. What makes it super powerful is that it
17
42
345