
Ankit Shah
@ankitjs
Followers
224
Following
469
Media
11
Statuses
155
Research Scientist at The Boston Dynamics AI Institute. Prev at Brown CS, Ph.D. from MIT. Making robots easy to program and deploy. https://t.co/MjcDjhu9pd
Cambridge, MA
Joined August 2013

A new handheld interface from MIT gives anyone the ability to train a robot for tasks in fields like manufacturing. The versatile tool can teach a robot new skills using one of three approaches: natural teaching, kinesthetic training, & teleoperation: https://t.co/SQDdh0FAuE
8
28
99

Yale Philosophy offers a course on “Formal Philosophical Methods” — a broad introduction to probability, logic, formal semantics, etc. Instructor Calum McNamara has now made all materials for the course (78 pages) freely available https://t.co/3ayerQBpHz
13
134
596

Wow! The core finding in the much-maligned Apple paper from @ParshinShojaee et al – that reasoning models generalize poorly in the face of complexity – has been conceptually replicated three times in three weeks. C. Opus sure didn’t see that coming. And a lot of people owe Ms.

@GaryMarcus @JonnyCoook @silviasapora @aahmadian_ @akbirkhan @_rockt @j_foerst @ParshinShojaee @i_mirzadeh @MFarajtabar @nouhadziri The programs we look at are quite simple and all represent novel combinations of familiar operations. We also find lower performance for more complex programs, especially for the compositions. Also, I have a sense that LLMs can handle OOD problems easier when represented in code
3
15
59
Ok I’ve read it now and as I expected the complaints about it are ill founded. It seems fine. I think it convincingly shows a lot of what I’ve been saying about these thinking models.

I still haven’t read that Apple paper but I see a lot of people complaining about it. To me, the complaints I’ve seen seem ill founded given what I understand about it, but obviously it’s hard for me to judge without having read the paper. What are the most reasonable complaints?
5
12
238

Friends, need your help. @antarikshB, a senior from IIT B has launched an incredible project of organizing all Sanskrit literature in one place, in a user-friendly manner. The service is free, not-for-profit, created purely out of passion. Media coverage will go a long way in
180
3K
5K

I like how they use the infinite rotation to make planning easier. Taking advantage of how your humanoid doesn't need to be human
3
6
69
How can robots understand spatiotemporal language in novel environments without retraining? 🗣️🤖 In our #IROS2024 paper, we present a modular system that uses LLMs and a VLM to ground spatiotemporal navigation commands in unseen environments described by multimodal semantic maps
1
11
22

Recent results like Apple’s show that LLMs (even o1) flub on reasoning with simple changes to problems that shouldn’t matter. A consensus is building that it shows they are “just pattern matching.” But that metaphor is misleading: good reasoning itself can also be framed as “just
28
25
209

Evaluation in robot learning papers, or, please stop using only success rate a paper and a 🧵 https://t.co/3cUad03GUl

arxiv.org
The robot learning community has made great strides in recent years, proposing new architectures and showcasing impressive new capabilities; however, the dominant metric used in the literature,...
1
41
201

My (pure) speculation about what OpenAI o1 might be doing [Caveat: I don't know anything more about the internal workings of o1 than the handful of lines about what they are actually doing in that blog post--and on the face of it, it is not more informative than "It uses Python
25
112
567

@jasonxyliu will present their @IJCAIconf survey paper on robotic language grounding. Please check out his talk (8/8 11:30) if you are at #IJCAI2024 In colab w/ @VanyaCohen, Raymond Mooney from @UTAustin, @StefanieTellex from @BrownCSDept, @drdavidjwatkins from The AI Institute

How do robots understand natural language? #IJCAI2024 survey paper on robotic language grounding We situated papers into a spectrum w/ two poles, grounding language to symbols and high-dimensional embeddings. We discussed tradeoffs, open problems & exciting future directions!
0
3
10
All the talk recordings are available at
youtube.com
https://sites.google.com/view/rss-taskspec
0
1
1
We will hear from an amazing line of speakers at our #RSS2024 workshop on robotic task specification tomorrow at 2 PM (CEST) in Aula Hall B @HadasKressGazit, @PeterStone_TX, @ybisk, @dabelcs, @cedcolas More details at: https://t.co/Y0ik9nCHqU
1
5
5

RL in POMDPs is hard because you need memory. Remembering *everything* is expensive, and RNNs can only get you so far applied naively. New paper: 🎉 we introduce a theory-backed loss function that greatly improves RNN performance! 🧵 1/n
5
57
318

Ever wonder if LLMs use tools🛠️ the way we ask them? We explore LLMs using classical planners: are they writing *correct* PDDL (planning) problems? Say hi👋 to Planetarium🪐, a benchmark of 132k natural language & PDDL problems. 📜 Preprint: https://t.co/kXItV6j6Dg 🧵1/n
9
40
196
Enforcing safety constraints with an LLM-modulo planner. Presented by @ZiyiYang96 at #ICRA2024

I'm at #ICRA2024 and will be presenting my paper titled "Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents" ( https://t.co/UxWUhy5adg). Excited++ 🦾🤖
0
2
7
Solving new tasks zero shot using prior experience in a related task! Find @jasonxyliu at #ICRA2024
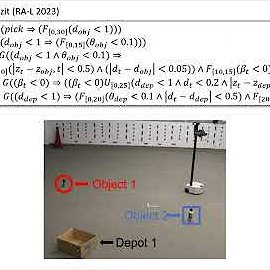
How can robots reuse learned policies to solve novel tasks without retraining? In our #ICRA2024 paper, we leverage the compositionality of task specification to transfer skills learned from a set of training tasks to solve novel tasks zero-shot
0
0
3
How can robots reuse learned policies to solve novel tasks without retraining? In our #ICRA2024 paper, we leverage the compositionality of task specification to transfer skills learned from a set of training tasks to solve novel tasks zero-shot
1
3
12

Back on April 1st I posted my three laws of robotics. Here are my three laws of AI. 1. When an AI system performs a task, human observers immediately estimate its general competence in areas that seem related. Usually that estimate is wildly overinflated. 2. Most successful AI
9
48
162

@krishnanrohit It’s likely not about divining a smarter training set. Need fundamental advances in learning to get vastly more efficient scaling, e.g. going beyond next token prediction, or Kolmogorov-Arnold Networks, or something such.
0
1
2