
Antoine Bosselut
@ABosselut
Followers
4K
Following
2K
Media
46
Statuses
1K
Helping machines make sense of the world. Asst Prof @ICepfl; Before: @stanfordnlp @allen_ai @uwnlp @MSFTResearch #NLProc #AI
Joined March 2013
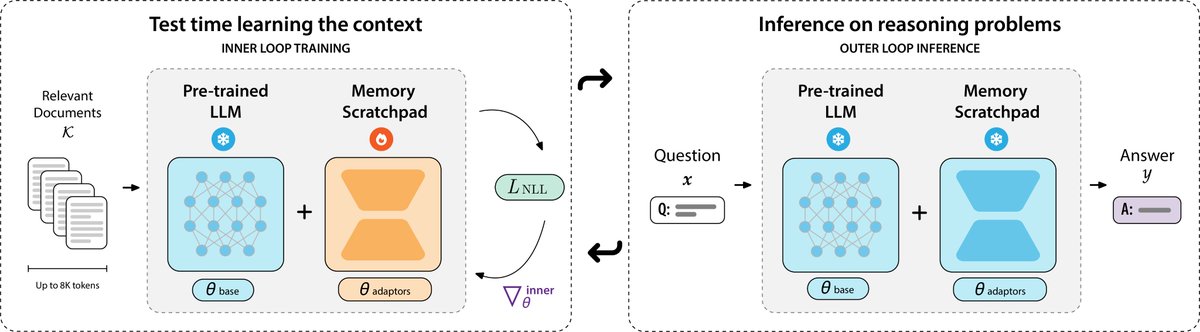
Check out Eric's new preprint on how we can do more reliable reasoning over long-contexts up to 128k tokens!.

🗒️Can we meta-learn test-time learning to solve long-context reasoning?. Our latest work, PERK, learns to encode long contexts through gradient updates to a memory scratchpad at test time, achieving long-context reasoning robust to complexity and length extrapolation while
0
0
9
RT @natolambert: If we want to build good open models we need to have well-funded labs dedicated to it. It's easy to get excited about com….
0
8
0

RT @negarforoutan: 🚀Introducing Parity-aware #BPE, a variant of the widely-used BPE algorithm with better token-count parity across languag….
0
5
0
RT @rajammanabrolu: By popular demand we've extended the Wordplay Workshop deadline by a couple of weeks until Sept 12! The competition on….
0
8
0
RT @clara__meister: 🚨New Preprint!. In multilingual models, the same meaning can take far more tokens in some languages, penalizing users o….
0
29
0
RT @GretaTuckute: Can't wait for #CCN2025! Drop by to say hi to me / collaborators!. @bkhmsi @yingtian80536 @NeuroTaha @ABosselut @martin_….
0
10
0
RT @maksym_andr: 🚨 Incredibly excited to share that I'm starting my research group focusing on AI safety and alignment at the ELLIS Institu….
0
85
0

The EPFL NLP lab is looking to hire a postdoctoral researcher on the topic of designing, training, and evaluating multilingual #LLMs. (link below). Come join our dynamic group in beautiful Lausanne!.
5
22
83
RT @eric_zemingchen: 🗒️Can we meta-learn test-time learning to solve long-context reasoning?. Our latest work, PERK, learns to encode long….
0
10
0
RT @zamir_ar: We benchmarked leading multimodal foundation models (GPT-4o, Claude 3.5 Sonnet, Gemini, Llama, etc.) on standard computer vis….
0
93
0
RT @SkanderMoalla: 🚀 Big time! We can finally do LLM RL fine-tuning with rewards and leverage offline/off-policy data!. ❌ You want rewards,….
0
37
0
RT @zamir_ar: We open-sourced the codebase of Flextok. Flextok is an image tokenizer that produces flexible-length token sequences and repr….
0
83
0
RT @cndesabbata: Huge thanks to my incredible coauthors for making this possible 🙏.@tedsumers, @bkhmsi, @abosselut, @cocosci_lab . Check ou….

arxiv.org
Being prompted to engage in reasoning has emerged as a core technique for using large language models (LLMs), deploying additional inference-time compute to improve task performance. However, as...
0
1
0
Check out @silin_gao 's paper done in collaboration with on reinforcing abstract thinking in #Reasoning traces!.

NEW PAPER ALERT: Recent studies have shown that LLMs often lack robustness to distribution shifts in their reasoning. Our paper proposes a new method, AbstRaL, to augment LLMs’ reasoning robustness, by promoting their abstract thinking with granular reinforcement learning.

1
0
7
RT @megamor2: What makes some jailbreak suffixes stronger than others?. We looked into the inner workings of GCG-like attacks and found a c….
0
1
0
RT @Cohere_Labs: Global MMLU is revolutionizing multilingual AI. 🌍. Recognized by Stanford HAI and adopted by top labs, it's the benchmark….
0
16
0
Check out Badr's work on specializing experts in MoE-style models to individually represent the operation of different brain networks.

🚨New Preprint!!. Thrilled to share with you our latest work: “Mixture of Cognitive Reasoners”, a modular transformer architecture inspired by the brain’s functional networks: language, logic, social reasoning, and world knowledge. 1/ 🧵👇

0
4
20
RT @negarforoutan: Got ideas for making LLMs more inclusive and culturally aware? 🌍✨.Submit to #MELT Workshop 2025!.We’re all about multili….
0
2
0