

Skander Moalla
@SkanderMoalla
Followers
236
Following
349
Media
22
Statuses
114
PhD @ the Caglar Gulcehre Lab for AI Research (CLAIRE) @EPFL. Deep Reinforcement Learning, RLHF, foundation models.
Lausanne, Switzerland
Joined January 2017
🚀 Big time! We can finally do LLM RL fine-tuning with rewards and leverage offline/off-policy data!. ❌ You want rewards, but GRPO only works online?.❌ You want offline, but DPO is limited to preferences?.✅ QRPO can do both!. 🧵Here's how we do it:
3
36
138
RT @MiTerekhov: Well, to avoid steganography, let's make sure our multi-agent LLM research workflows are composed of agents with different….
0
2
0
RT @XiuyingWei966: If you’re interested in long-context efficiency, don’t miss our recent paper RAT—a joint effort with @anunay_yadav, Razv….
0
3
0
RT @MiTerekhov: AI Control is a promising approach for mitigating misalignment risks, but will it be widely adopted? The answer depends on….
0
20
0
RT @caglarml: I am proud that our latest work on a novel RL method for foundation models/LLMs is finally out!. 1️⃣ Why does QRPO matter?.Al….
0
6
0
RT @matrs01: I couldn’t be prouder to share this. 🎉.Our work on Quantile Reward Policy Optimization (QRPO) for LLM RL‑finetuning bridged de….
0
2
0
I’m really proud of this work! It’s been an amazing collaboration with @matrs01 and @caglarml!. 📰 Paper: Hidden gems and open questions in the 30+ page appendix💎. 🧑💻 Code: Star to show interest⭐. 🌐 Blog:
claire-labo.github.io
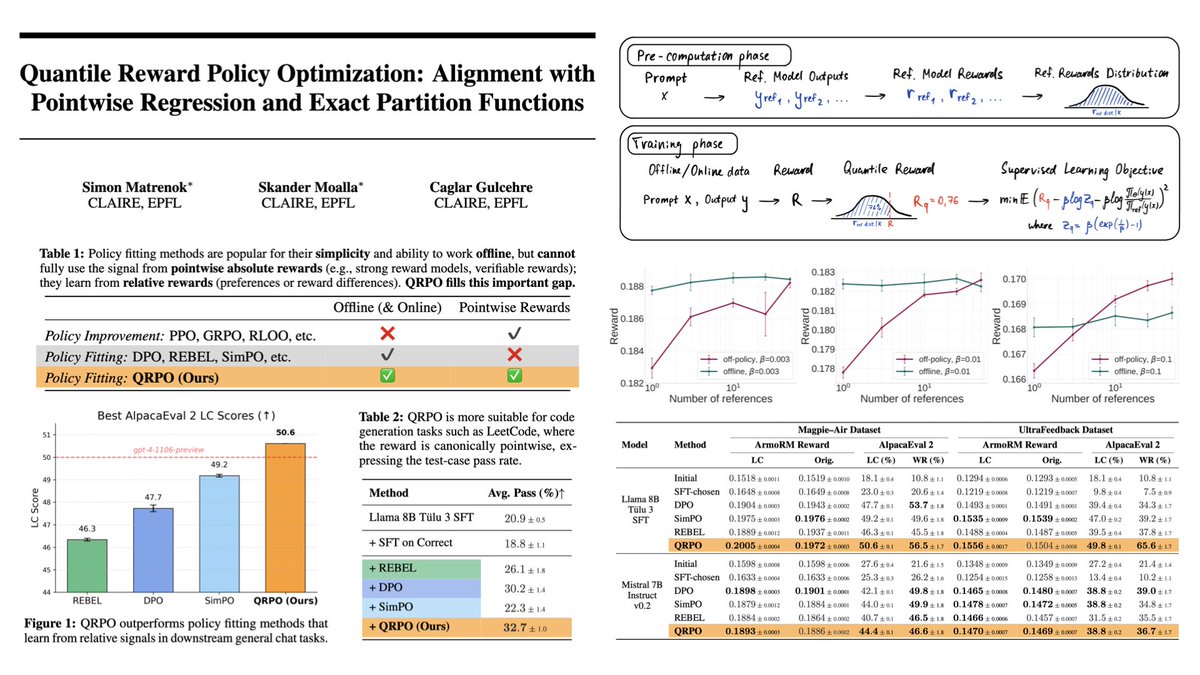
Alignment with Pointwise Regression and Exact Partition Functions
0
1
4
QRPO is a framework. You can shape the optimal policy! 🎛️. We derive a framework around QRPO for using transformations on top of the quantile reward. Each transformation reshapes the reward distribution and affects the properties of the optimal policy, while having

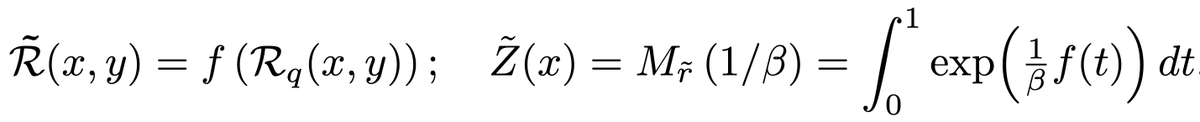
1
0
3
Is QRPO still subject to the "chosen probabilities decreasing" problem?. Our understanding of the KL-regularized closed-form solution gives insights into the "DPO chosen probabilities decreasing" problem! 🤔. For QRPO, this is not a mystery anymore; we know exactly where the
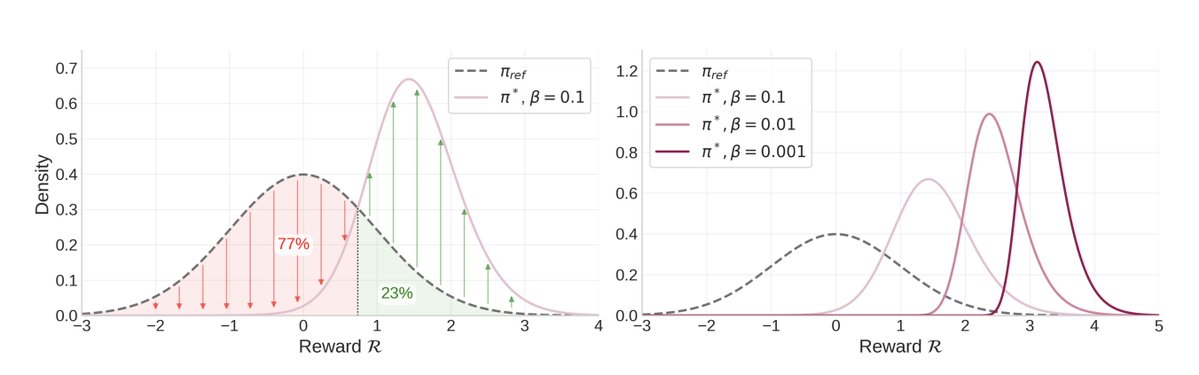
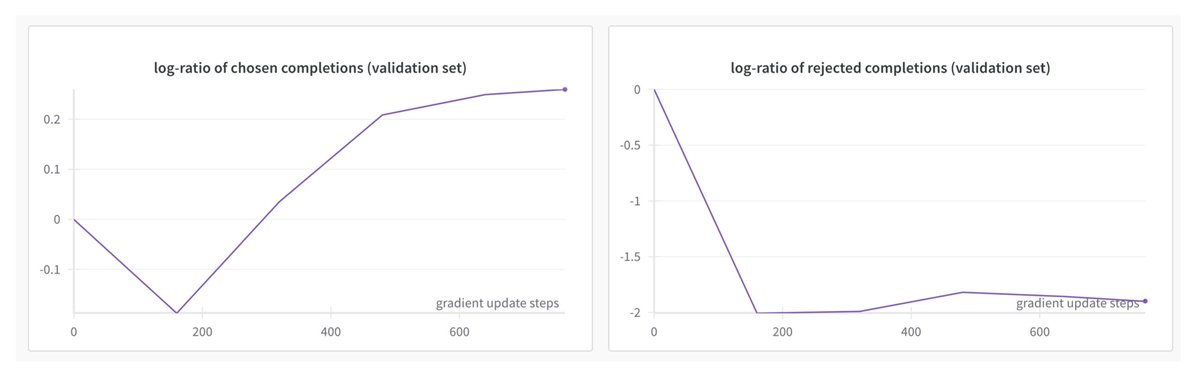
1
0
3
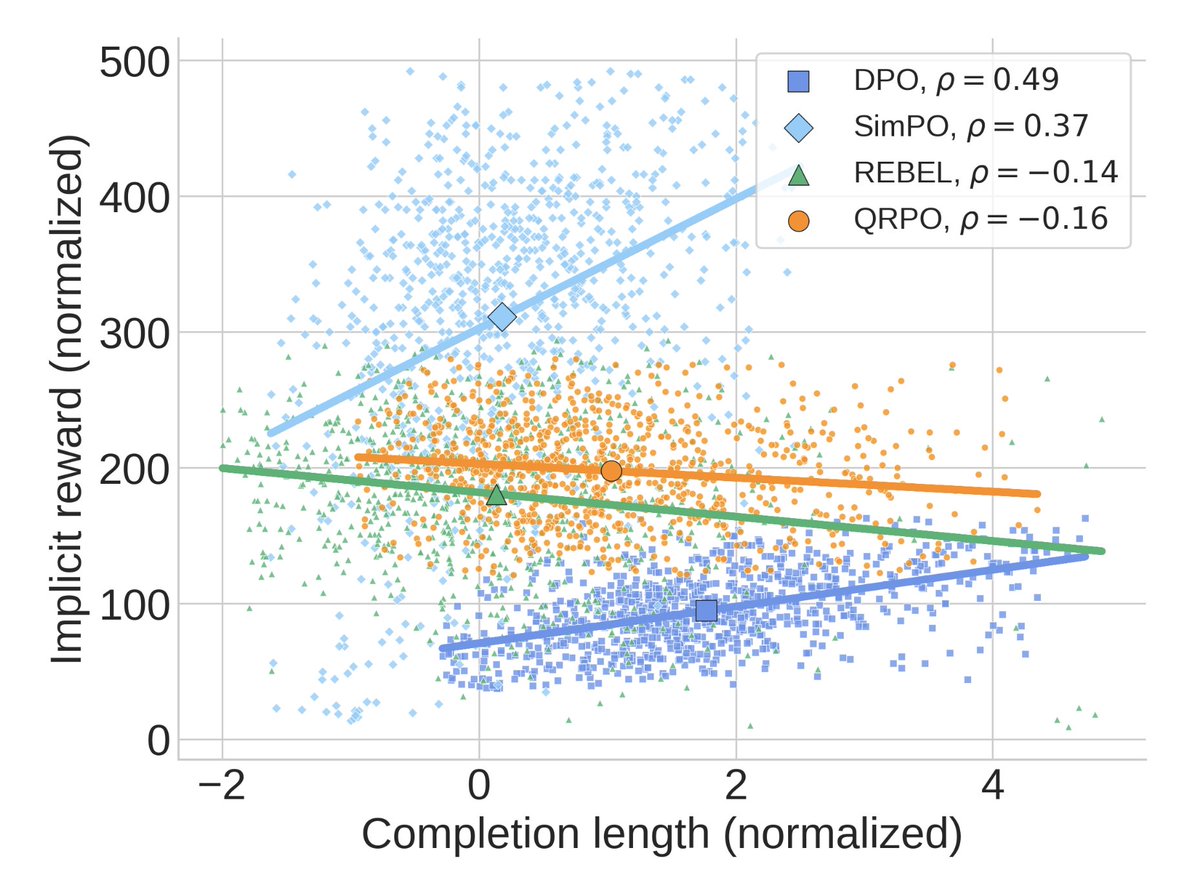
💬 The reward model we use has been trained to be robust to length bias, and we see that this is preserved in QRPO and REBEL, which use rewards. But when compressed to preferences for DPO and SimPO, it leads to the typical length bias trend, despite the reduction in mean length.
1
0
3
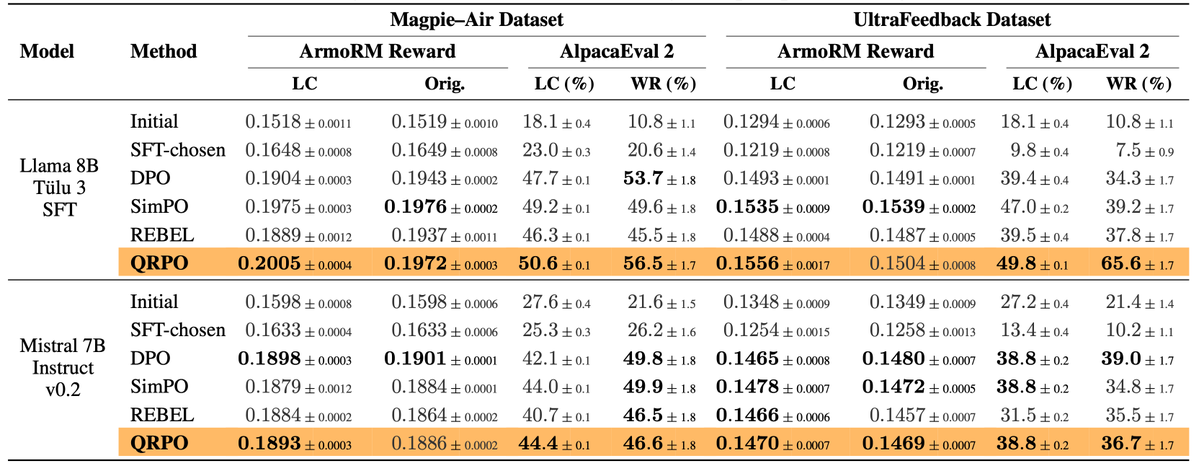
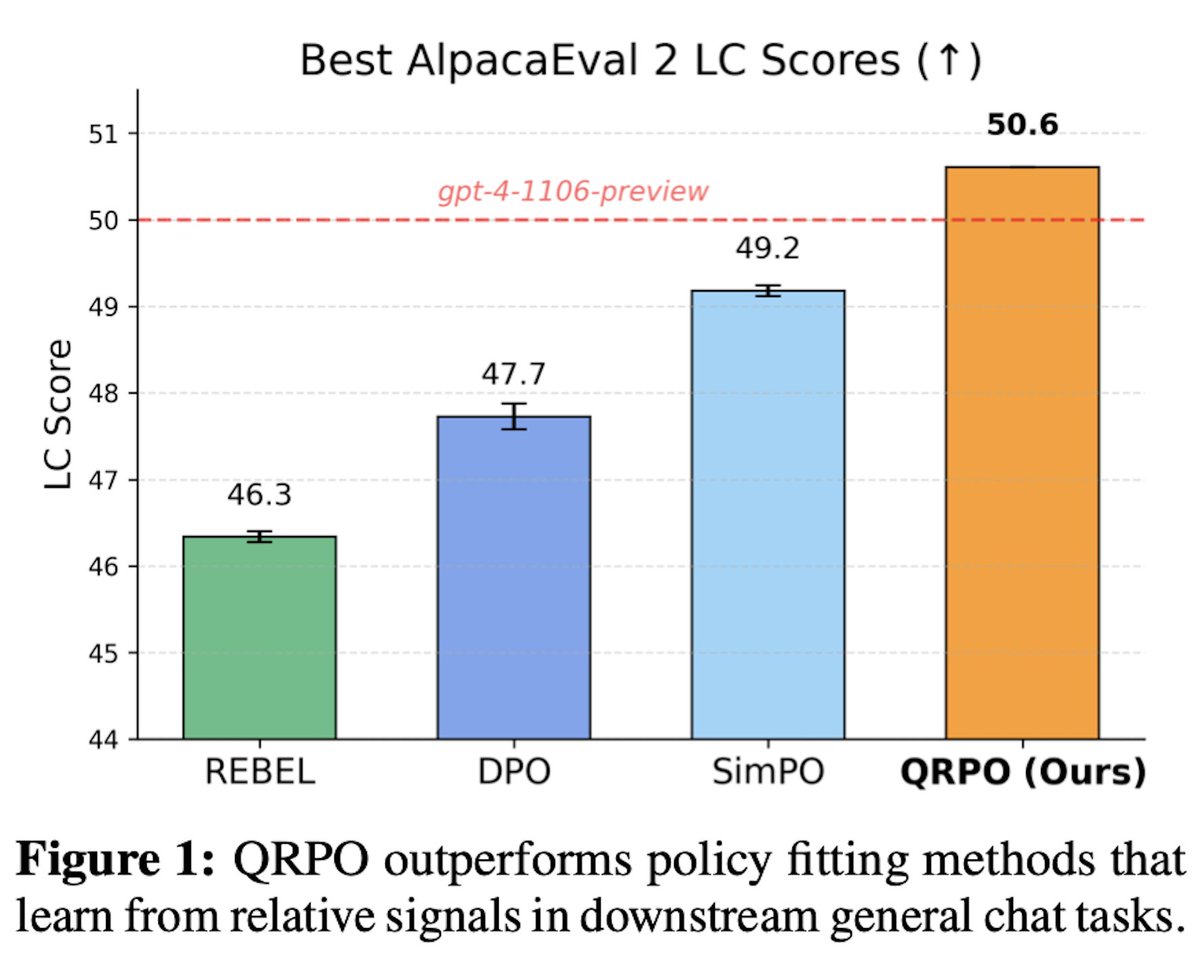
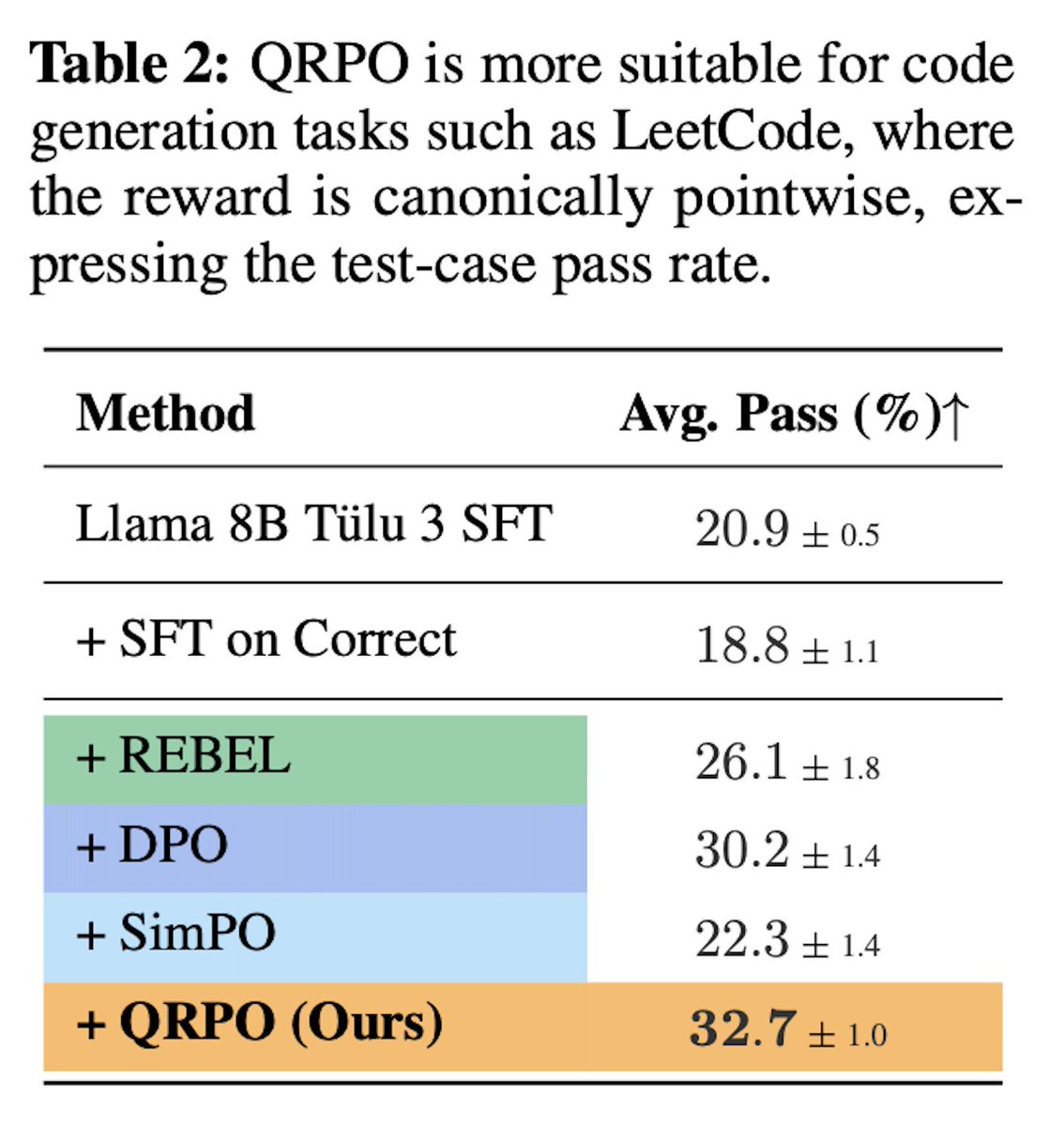
🥇 QRPO achieves top performance in chat and coding compared to DPO, REBEL, and SimPO, each capturing a different way to learn from the reward signal (preference, reward difference, length normalization).
1
0
4
Obviously, nothing comes for free, but we give you a great deal! 🤝. * QRPO does not need many reference rewards to estimate quantiles: for high-quality offline datasets, 1-3 are enough!. * And you can scale this number for off-policy data generated from the reference model! 📈
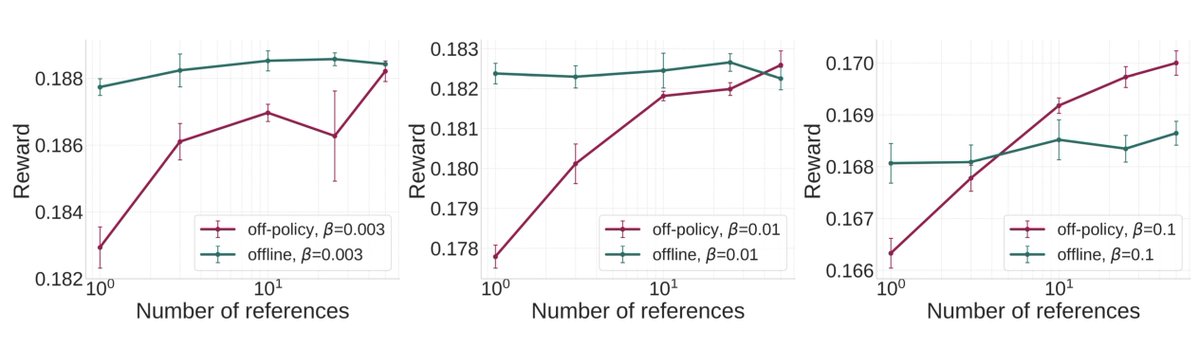
1
0
3
We tackle the infamous “. partition function is known to be intractable. ” problem 🧐. This is the problem that limits DPO-like methods to pairwise data. We solve it thanks to 3 insights! 💡. 1️⃣ The “infinite sum over all possible LLM generations” argument is a myth. We
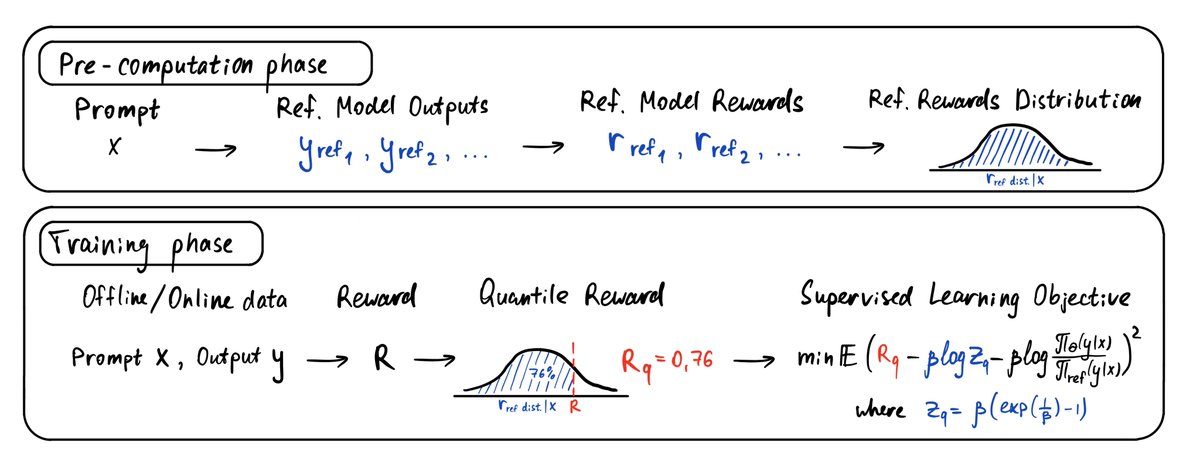

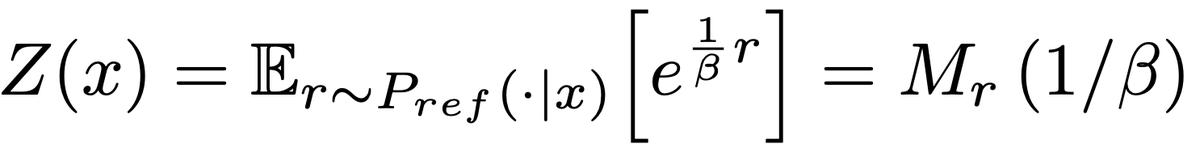
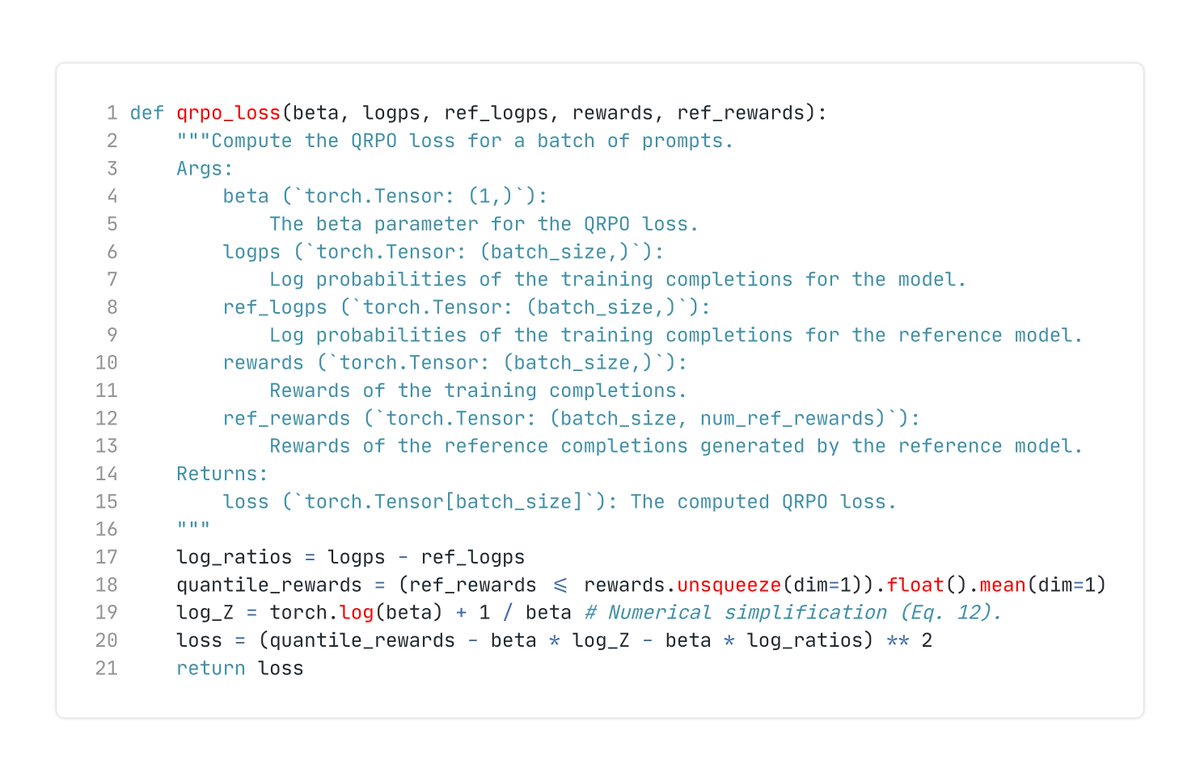
1
1
7
RT @XiuyingWei966: Curious about making Transformers faster on long sequences without compromising accuracy? ⚡️🧠 Meet RAT—an intermediate d….
0
9
0
RT @abeirami: As we go through a lot of excitement about RL recently with lots of cool work/results, here is a reminder that RL with a reve….
0
52
0
RT @manuelmlmadeira: Unfortunately I’m not attending @iclr_conf , but excited to share our workshop papers!. 📡 Graph Discrete Diffusion: A….
0
5
0
RT @AnjaSurina: Excited to share our latest work on EvoTune, a novel method integrating LLM-guided evolutionary search and reinforcement le….
0
31
0
A dream come true! I presented "No Representation, No Trust" on my favorite RL podcast, @TalkRLPodcast !.Make sure to check it out to learn why training with PPO for too long makes your agent collapse!.

E63: NeurIPS 2024 - Posters and Hallways 1. @JiahengHu1 of @UTCompSci on Unsupervised Skill Discovery for HRL.@SkanderMoalla of @EPFL: Representation and Trust in PPO.Adil Zouitine of IRT Saint Exupery/@Hugging Face : Time-Constrained Robust MDPs.@Shoumo_ of @hplabs :

1
3
19
RT @jdeschena: Just taking advantage of the wave of excitement around diffusion LLMs to announce that our acceleration method for diffusion….
0
8
0