

Zeming Chen
@eric_zemingchen
Followers
554
Following
465
Media
24
Statuses
60
PhD Candidate, NLP Lab @EPFL; Research Scientist Intern @AIatMeta; Ex @AIatMeta (FAIR) @allen_ai #AI #ML #NLP
Lausanne, Switzerland
Joined July 2021

In collaboration with my wonderful co-authors: @agromanou, @gail_w , & @ABosselut!. Links 🔗:.Project Page: Paper: Code:
1
0
3
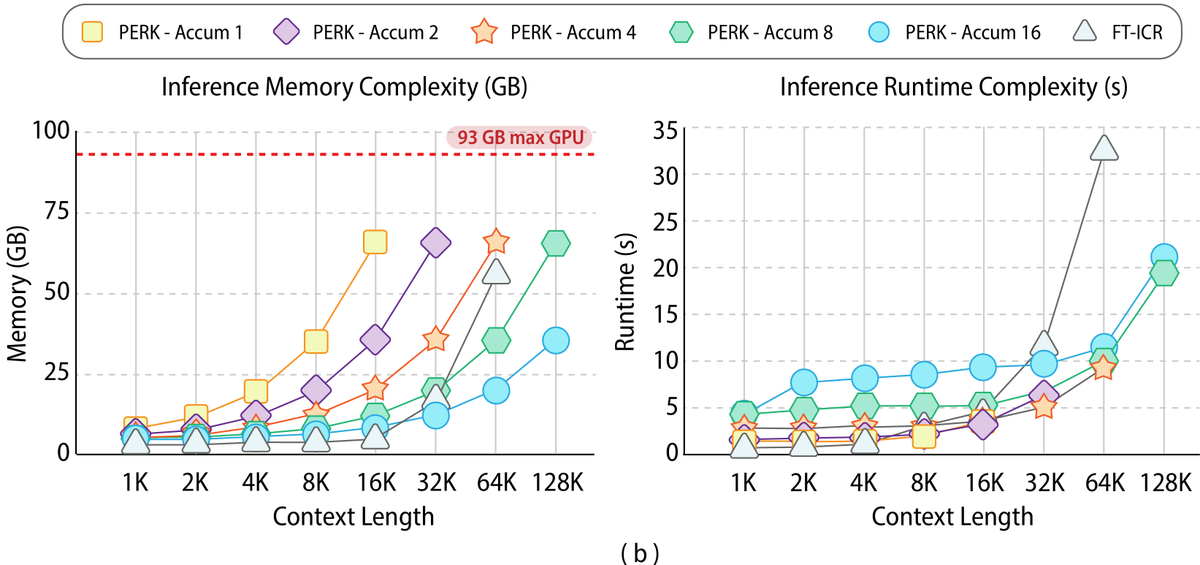
💻Finally, PERK demonstrates more efficient scaling in both memory and runtime, particularly for extremely long sequences. While in-context reasoning is initially more efficient, its memory and runtime grow rapidly, leading to OOM errors at a context length of 128K. In contrast,
1
0
2
🧭PERK also bypasses the “lost in the middle” effect. When trained on contexts with relevant documents randomly located or fixed at a particular position, PERK consistently outperforms the in-context baseline when generalizing to test-time position changes.

1
0
2
💪In fact, as we keep growing the inference-time context length for PERK models only trained on 8k sequence lengths, we see that PERK can still get most answers right even as we extrapolate to 128k tokens. In contrast, the in-context reasoning baseline fine-tuned on 8k sequence

1
0
2
We also evaluate PERK's ability to generalize to inputs of different lengths than those seen in training. ⬅️PERK interpolates (generalizing to shorter sequences) perfectly, while the in-context baseline’s interpolation degrades. ➡️For extrapolation (generalizing to longer

1
0
2
We evaluate PERK on long-context reasoning over two tasks: (1) Needles-in-a-Haystack (NIAH with BabiLong) and (2) Drops-in-an-Ocean (DIO), a new evaluation setting that forms long contexts from structurally similar documents. 📈PERK outperforms all baselines consistently across

1
0
2
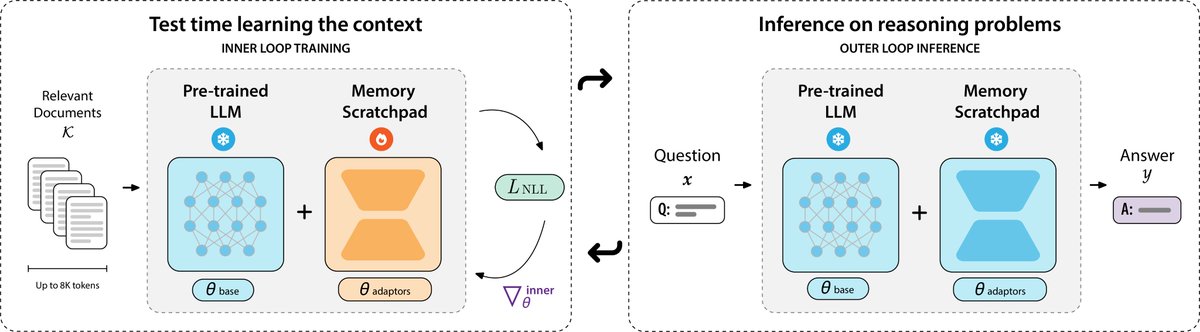
The training procedure involves a nested inner and outer loop. The inner loop optimizes the likelihood of a batch of long context segments with respect to the parameters of the LoRA-based memory scratchpad. In the outer loop, the model uses the encoded information in the memory

1
0
2
PERK uses a parameter-efficient test-time adaptation to reduce both the size and amount of gradient unrolling required during optimization. Specifically, in the inner and outer loops, we optimize only a parameter-efficient adapter, LoRA, to encode the contexts, and apply

1
0
2
🗒️Can we meta-learn test-time learning to solve long-context reasoning?. Our latest work, PERK, learns to encode long contexts through gradient updates to a memory scratchpad at test time, achieving long-context reasoning robust to complexity and length extrapolation while
1
10
18
RT @QiyueGao123: 🤔 Have @OpenAI o3, Gemini 2.5, Claude 3.7 formed an internal world model to understand the physical world, or just align p….
0
44
0
RT @bkhmsi: 🚨New Preprint!!. Thrilled to share with you our latest work: “Mixture of Cognitive Reasoners”, a modular transformer architectu….
0
84
0
RT @agromanou: If you’re at @iclr_conf this week, come check out our spotlight poster INCLUDE during the Thursday 3:00–5:30pm session! . I….
0
14
0
RT @silin_gao: NEW PAPER ALERT: Generating visual narratives to illustrate textual stories remains an open challenge, due to the lack of kn….
0
11
0
RT @bkhmsi: 🚨 New Preprint!!. LLMs trained on next-word prediction (NWP) show high alignment with brain recordings. But what drives this al….
0
64
0
RT @bkhmsi: 🚨 New Paper!. Can neuroscience localizers uncover brain-like functional specializations in LLMs? 🧠🤖. Yes! We analyzed 18 LLMs a….
0
31
0
RT @agromanou: 🚀 Introducing INCLUDE 🌍: A multilingual LLM evaluation benchmark spanning 44 languages!.Contains *newly-collected* data, pri….
0
61
0
RT @bkhmsi: 🚨 New Paper!!. How can we train LLMs using 100M words? In our @babyLMchallenge paper, we introduce a new self-synthesis trainin….
0
24
0
RT @Walter_Fei: Alignment is necessary for LLMs, but do we need to train aligned versions for all model sizes in every model family? 🧐. We….
0
25
0
RT @ABosselut: Hey #NLProc folks, we had a lot of fun last year, so we're inviting guest lecturers again for our Topics in NLP course durin….

docs.google.com
The EPFL Natural Language Processing Lab invites applications to give a guest lecture in the EPFL Topics in Natural Language Processing course during the Fall 2024 semester. Background: Since 2022,...
0
6
0