
Ziming Liu
@ZimingLiu11
Followers
9,315
Following
640
Media
61
Statuses
419
PhD student @MIT , AI for Physics/Science, Science of Intelligence & Interpretability for Science
Joined May 2021
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
BECKY X MAYBELLINE LIVE
• 230469 Tweets
Northern Lights
• 211450 Tweets
オーロラ
• 170154 Tweets
#Auroraborealis
• 92475 Tweets
DeNA
• 61864 Tweets
#baystars
• 61443 Tweets
THE SIGN in MANILA
• 43046 Tweets
京王杯SC
• 22051 Tweets
Fulham
• 21610 Tweets
太陽フレアのせい
• 18177 Tweets
ベイスターズ
• 18129 Tweets
ハマスタ
• 17413 Tweets
バチコン
• 16802 Tweets
ウインマーベル
• 10671 Tweets




















Pinned Tweet

MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
117
1K
5K
To make neural networks as modular as brains, We propose brain-inspired modular training, resulting in modular and interpretable networks! The ability to directly see modules with naked eyes can facilitate mechanistic interpretability. It’s nice to see how a “brain” grows in NN!
69
624
3K
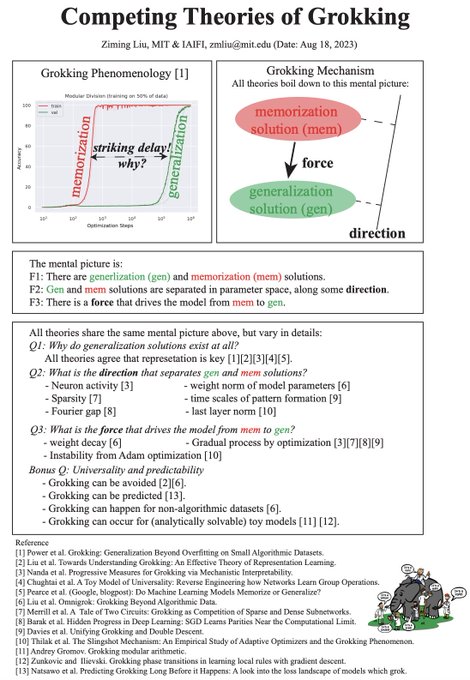
Deep learning has many mysterious phenomena, and grokking is one of the extreme. Want to catch up with the grokking literature? I've compiled a one-page summary of what's going on in the grokking world. Enjoy! :-)
18
137
750
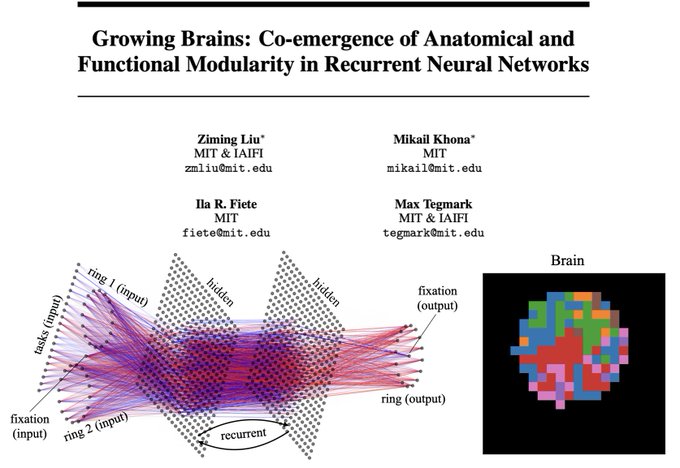
Mechanistic interpretability is not only for ML or LLM, but is even more promising for Science! A few months ago, we proposed a brain-inspired method (BIMT) for NN interpretability; Now we're happy to see that it can give something back to neuroscience - Growing brains in RNNs!
8
114
617
We now release BIMT codes and welcome you to train your own modular & interpretable networks, like growing a "brain"! This thread 🧵will cover the basic idea & beyond (1/N)
📃Paper:
📷Code:
🔗Demo:
9
134
569
Extremely boring paper alert‼️ Training 100000 small networks, studying their statistics and interpreting them. This "boring" stuff leads to an intriguing mechanism for neural scaling laws, which happens to explain the 0.34 exponent observed in Chinchilla (our prediction is 1/3).

11
63
541
Many scientific problems hinge on finding interpretable formulas that fit data, but neural networks are the outright opposite! Check out our recent work that make neural networks modular and interpretable. If you have interesting datasets at hand, we're happy to collaborate!
11
86
496
A good machine learning (ML) theory is probably like physics. As an example, I demonstrate how we, trained as physicists, take our unique perspectives to demystify grokking.

11
90
407
Many scientific problems can be formulated as regression. In this blogpost, I argue structure regression is probably a better goal than symbolic regression. If you are interested in applying structure regression to your scientific field, please DM me!😀
9
58
366
@loveofdoing
Thanks for sharing our work! In case anyone's interested in digging more, here's my tweet 😃:
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
117
1K
5K
5
11
354
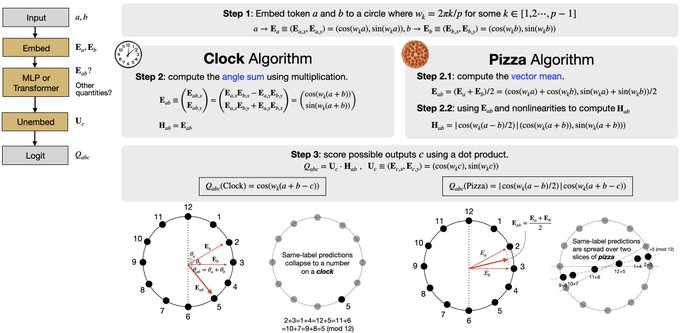
NN interpretability can be more diverse than you think! For modular addition, we find that a “pizza algorithm” can emerge from network training, which is significantly different from the “clock algorithm” found by
@NeelNanda5
. Phase transitions can happen between pizza & clock!
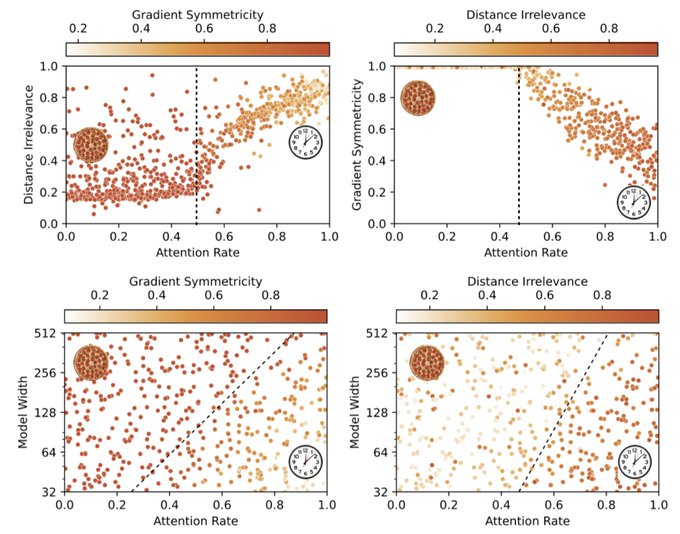
3
54
336
Are you a fan of neural loss landscape/neural dynamics/geometric learning like me? This is a 🧵 for related ICLR papers.
21
44
313
It's been long I haven't read a paper till the last word. Especially sympathize with Max's take on scaling. Highly recommend!

1
37
303
If deep learning is the question, what's the answer? Probably compression! As much as I liked the weight norm explanation for grokking, weight norm isn't information. Remembering DNNs are just local linear computations, we define a new metric, showing that grokking = compression.

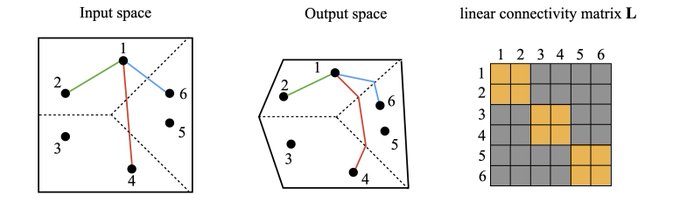
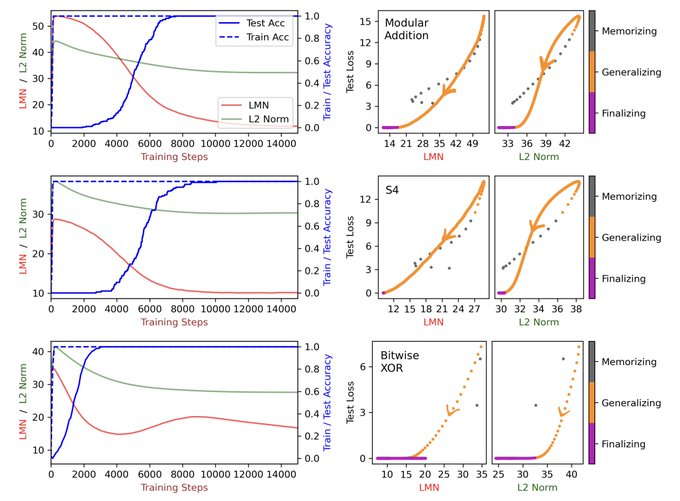
8
42
285
Macroscopic phase transitions must have microscopic reasons! Atomic interaction is the answer for physical phase transitions, but what about phase transitions of learning? The physical intuition applies to machine learning as well; representation learning = interacting "repons"!
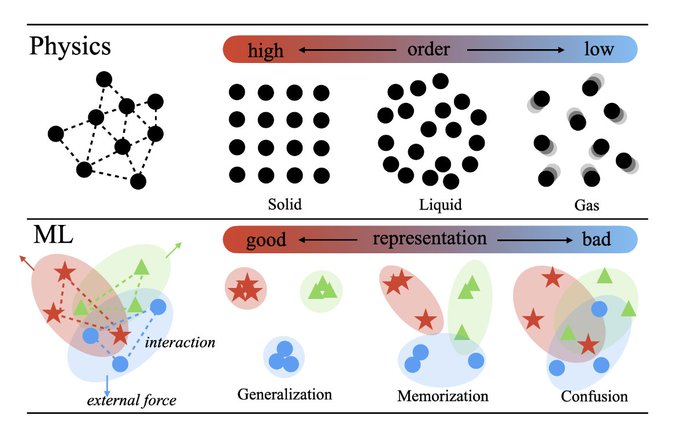
2
45
286
The grokking phenomenon seemed very puzzling and uncontrollable, but no more! We understand grokking via the lens of neural landscapes, and show we can induce or eliminate grokking on various datasets as we wish. Joint work with
@tegmark
@ericjmichaud_
.

4
53
281
Spent a whole day skimming through titles of 9k+ papers submitted to ICLR this year🥲, I picked around 200 papers that piqued my interest, including "science of deep learning", "deep learning for science", "voodoos", "interpretability" and/or "LLM".
link:

5
42
272
Training dynamics is my favourite, this time for diffusion models! Diffusion models have three learning phases, similar to humans -- confusion, memorization and (finally!) generalization! I also enjoy imagining the formation of the manifold as weaving a net of data.
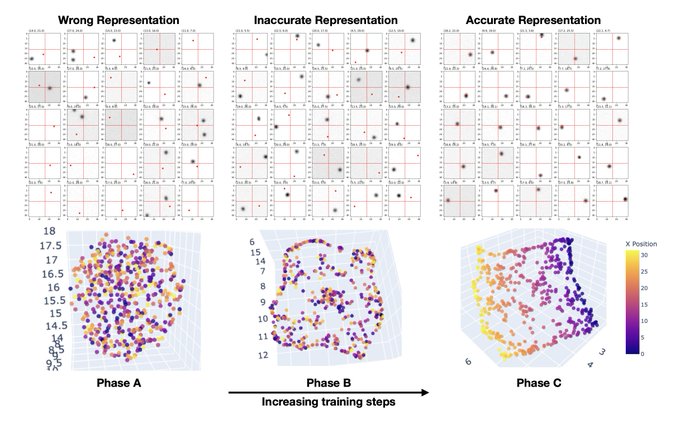
2
29
258
@tegmark
1/N MLPs are foundational for today's deep learning architectures. Is there an alternative route/model? We consider a simple change to MLPs: moving activation functions from nodes (neurons) to edges (weights)!
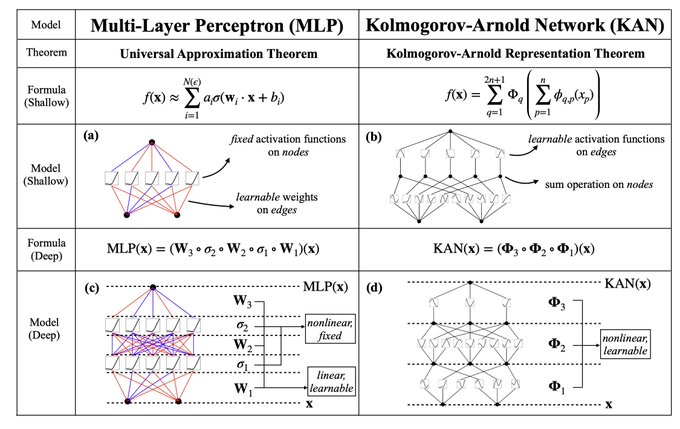
5
44
297
This fall, I’ll be on job market looking for postdoc and faculty positions in US! My research interests span in AI + physics (science). If there’re opportunities to present in your school, institute, group, seminar, workshop etc., I really appreciate it! 🥹
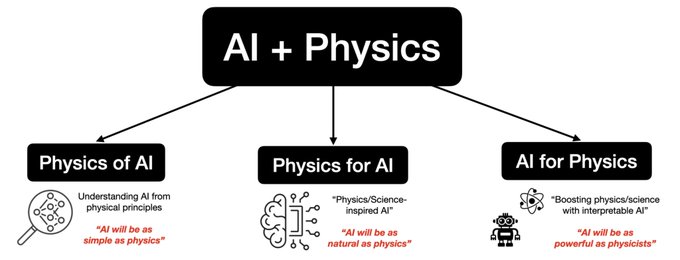
6
53
239
Neural networks sometimes leverage a strange "pizza algorithm" to implement modular addition. After posting our Pizza paper , many readers have complained that it is not easy to understand. Here's our effort to visualize it; hopefully it's helpful!
2
33
239
You probably don't need/want to use LLMs for science! We propose an incredibly simple & interpretable algorithm that discovers conservation laws. Novel conservation laws are discovered (not rediscovered!) for the first time, in fluid mechanics and in atmospheric chemistry.

6
37
231
Generative models have been inspired by physics, but Eureka-type “inspirations” are mysterious. Is there a systematic way to convert physical processes to generative models? The answer is yes! This will largely augment design space of generative models.
2
55
231
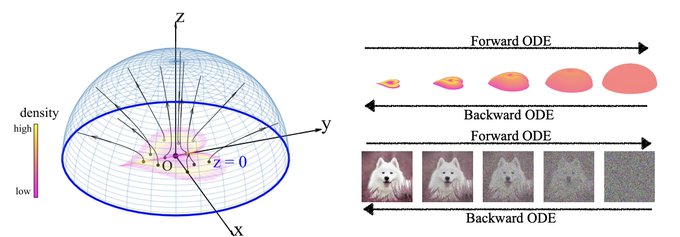
If we view generative models (e.g., diffusion models) as physical processes, will the concept of "time travel" help? We propose restart, interpreted as traveling back in time, which can augment ODE samplers to outperform SDE samplers with better performance & efficiency.
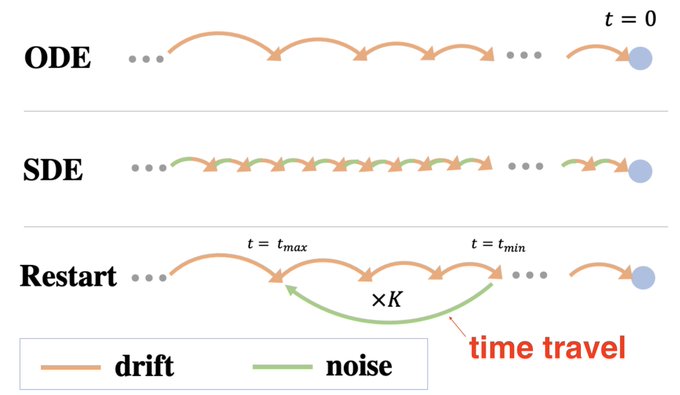
3
30
204
In a week, I can probably cross out my whole todo list. 🥲

3
7
208
What do large language models and quantum physics have in common? They are both quantized! We find that a neural network contains many computational quanta, whose distribution can explain neural scaling laws. Happy to be part of the project lead by
@ericjmichaud_
and
@tegmark
!

4
30
178
How do multiple tasks compete for resources in a neural network? Competition for resource is prevalent in nature and in society, but how about neural networks? Here's our resource model of neural networks for neural scaling laws. We show homogeneous growth like gas equilibrium!🥳
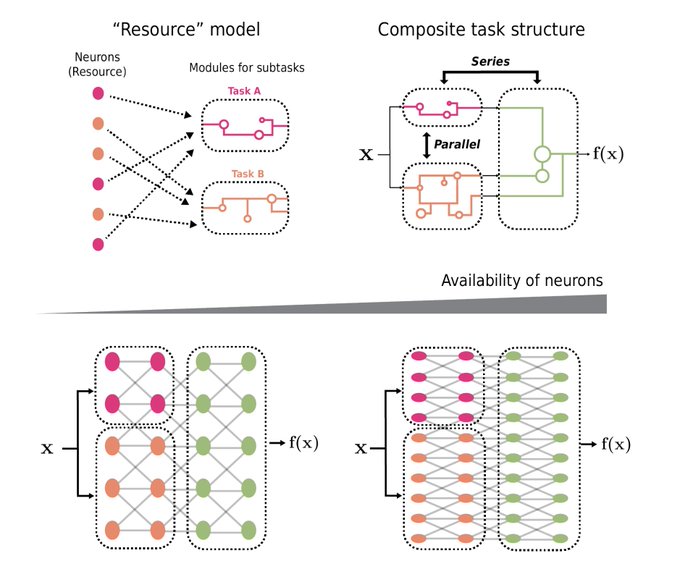
1
27
173
13/N We used KANs to rediscover mathematical laws in knot theory. KANs not only reproduced Deepmind's results with much smaller networks and much more automation, KANs also discovered new formulas for signature and discovered new relations of knot invariants in unsupervised ways.
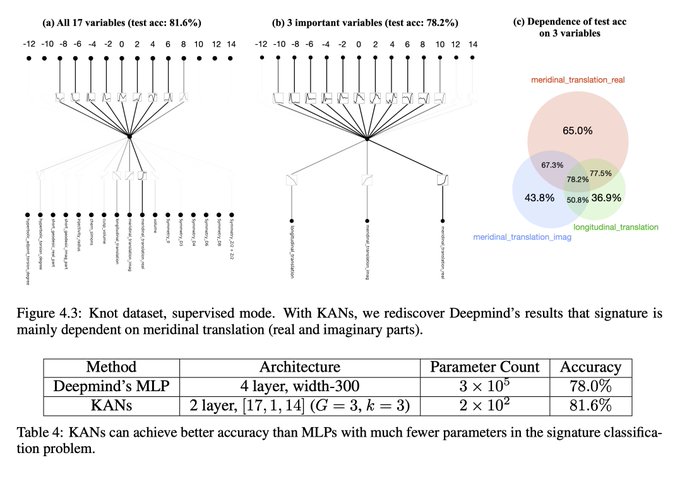
3
12
199
Two recent physics-inspired generative models, diffusion models and Poisson flows, are they really that different? We show they can be unified under a framework called PFGM++. More intriguingly, interpolation between two models gives a sweet spot with SOTA performance!
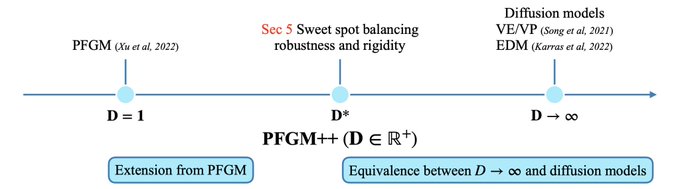
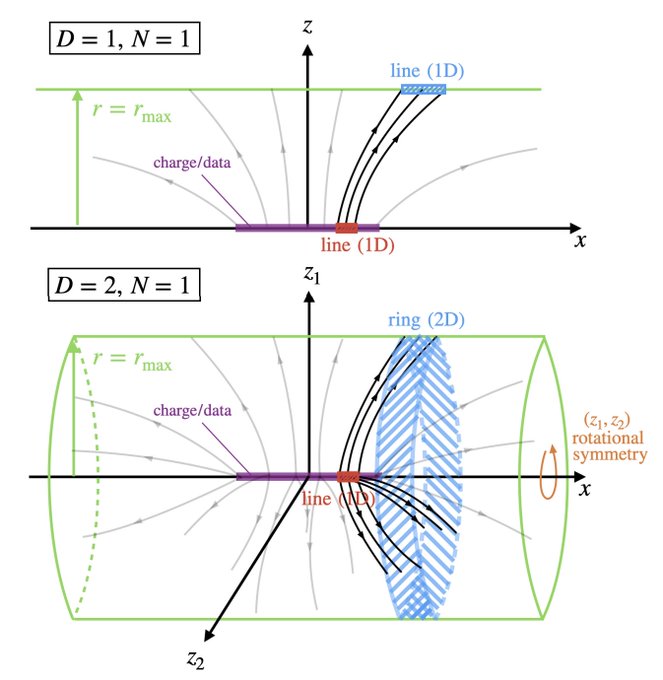
1
33
169
17/N Given our empirical results, we believe that KANs will be a useful model/tool for AI + Science due to their accuracy, parameter efficiency and interpretability. The usefulness of KANs for machine learning-related tasks is more speculative and left for future work.
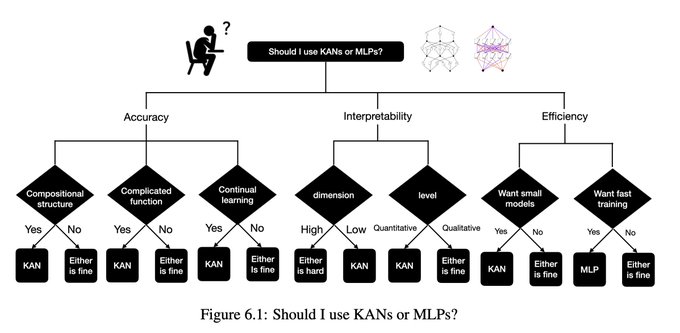
3
11
178
10/N As a bonus, we also find KANs' natural ability to avoid catastrophic forgetting, at least in a toy case we tried.
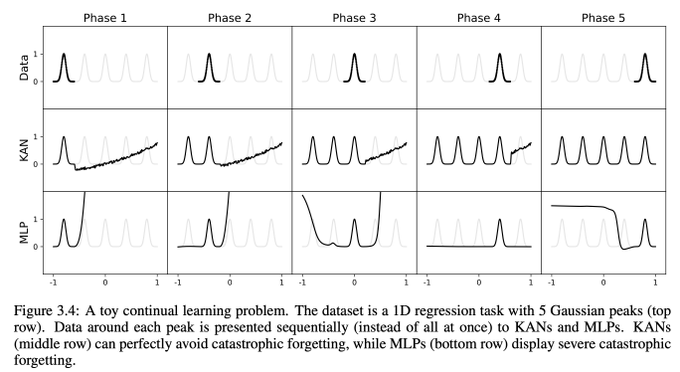
4
7
163
19/N Why is training slow?
Reason 1: technical. learnable activation functions (splines) are more expensive to evaluate than fixed activation functions.
Reason 2: personal. The physicist in my body would suppress my coder personality so I didn't try (know) optimizing efficiency.
6
6
165
20/N Adapt to transformers: I have no idea how to do that, although a naive (but might be working!) extension is just replacing MLPs by KANs.
8
3
157
@tegmark
3/N Inspired by the representation theorem, we explicitly parameterize the Kolmogorov-Arnold representation with neural networks. In honor of two great late mathematicians, Andrey Kolmogorov and Vladimir Arnold, we call them Kolmogorov-Arnold Networks (KANs).
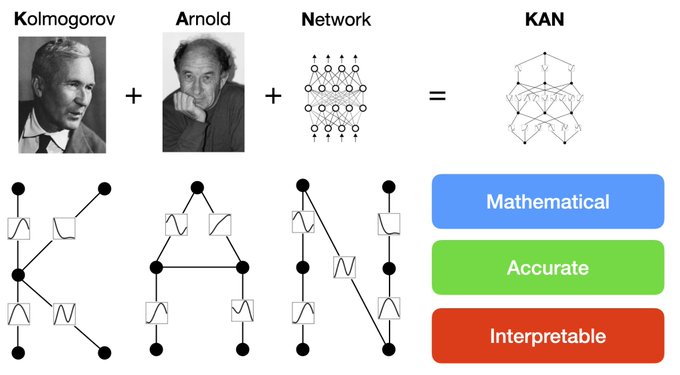
3
8
160
I'm glad to present our recent works in Prof. Levin's group! I talked about how neuroscience can help AI interpretability and how it in turn helps neuroscience. Here's the recording:
Growing "Brains" in Artificial Neural Networks via
@YouTube

0
25
133
14/N In particular, Deepmind’s MLPs have ~300000 parameters, while our KANs only have ~200 parameters. KANs are immediately interpretable, while MLPs require feature attribution as post analysis.
1
6
154
7/N Neural scaling laws: KANs have much faster scaling than MLPs, which is mathematically grounded in the Kolmogorov-Arnold representation theorem. KAN's scaling exponent can also be achieved empirically.
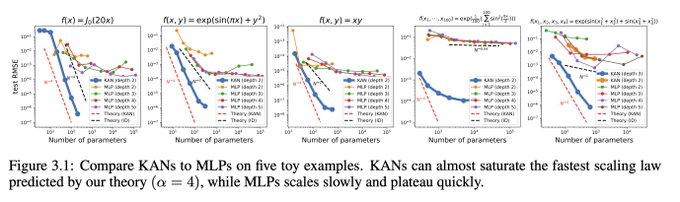
3
12
149
11/N KANs are also interpretable. KANs can reveal compositional structures and variable dependence of synthetic datasets from symbolic formulas.
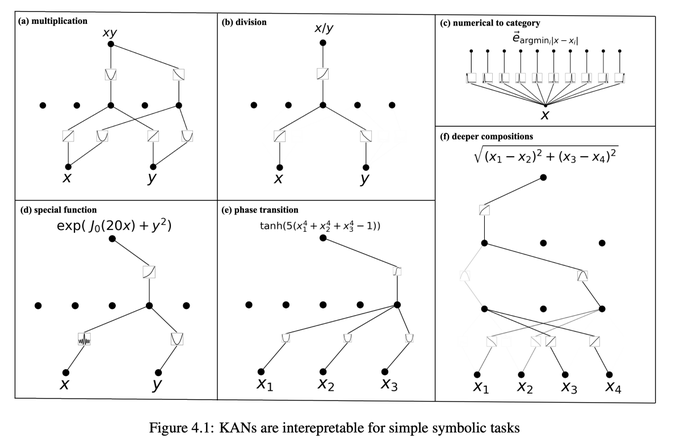
1
7
141
5/N From the algorithmic aspect: KANs and MLPs are dual in the sense that -- MLPs have (usually fixed) activation functions on neurons, while KANs have (learnable) activation functions on weights. These 1D activation functions are parameterized as splines.
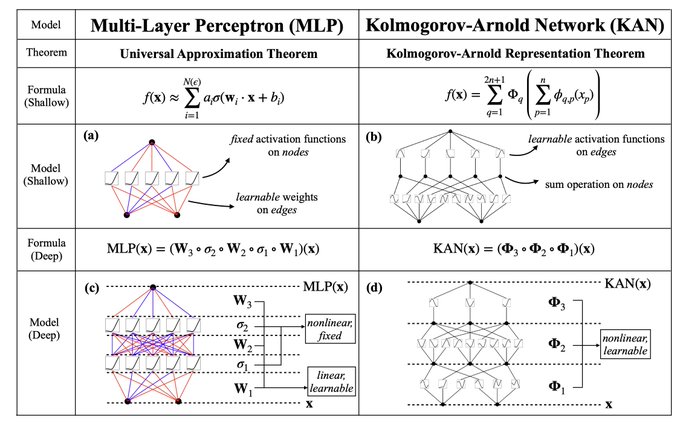
5
8
131
12/N Human users can interact with KANs to make them more interpretable. It’s easy to inject human inductive biases or domain knowledge into KANs.
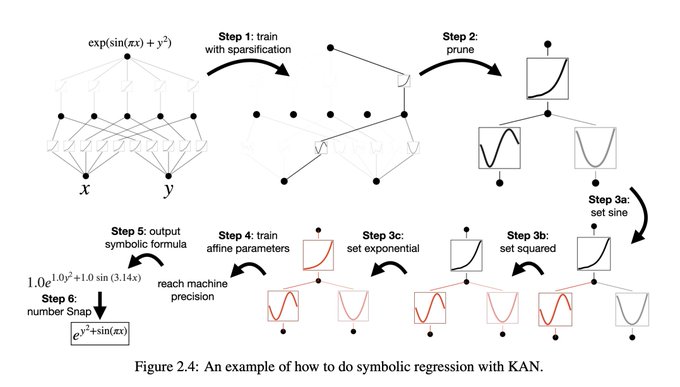
2
6
134
@tegmark
2/N This change sounds from nowhere at first, but it has rather deep connections to approximation theories in math. It turned out, Kolmogorov-Arnold representation corresponds to 2-Layer networks, with (learnable) activation functions on edges instead of on nodes.
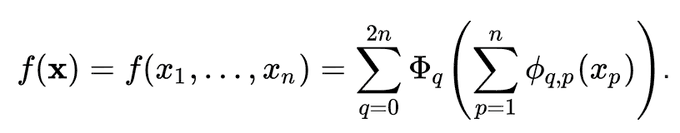
1
7
131
18/N Computation requirements:
All examples in our paper can be reproduced in less than 10 minutes on a single CPU (except for sweeping hyperparams). Admittedly, the scale of our problems are smaller than many machine learning tasks, but are typical for science-related tasks.
4
6
122
@tegmark
4/N From the math aspect: MLPs are inspired by the universal approximation theorem (UAT), while KANs are inspired by the Kolmogorov-Arnold representation theorem (KART). Can a network achieve infinite accuracy with a fixed width? UAT says no, while KART says yes (w/ caveat).
2
3
121
6/N From practical aspects: We find that KANs are more accurate and interpretable than MLPs, although we have to be honest that KANs are slower to train due to their learnable activation functions. Below we present our results.
2
4
119
A strange conservation law discovered by our AI method is now understood by domain experts (see this paper )! This is a special moment for me - never felt this proud of the tools we're building! And, NO, AI isn't replacing scientists, but complementing us.

It's funny that our "AI for conservation laws" methods become increasingly simpler, more interpretable, but also less publishable (rejected by PRL first🥲, but then accepted by PRE 🥳). Curiosity-driven science need interpretability, not scale. We want less, not more. Fun collab!
3
9
66
3
24
101
A review on Scientific discovery in the Age of AI, now published in
@Nature
! Happy to be part of this exciting project with
@AI_for_Science
friends!
…

1
14
94
This is a joint work w/
@tegmark
and awesome collaborators from MIT, Northeastern, IAIFI and Caltech.
1
4
106
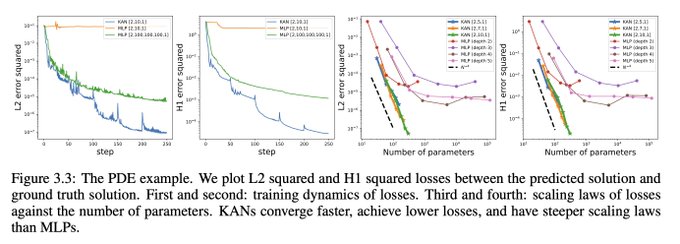
9/N KANs are more accurate than MLPs in PDE solving, e.g, solving the Poisson equation.
1
5
100
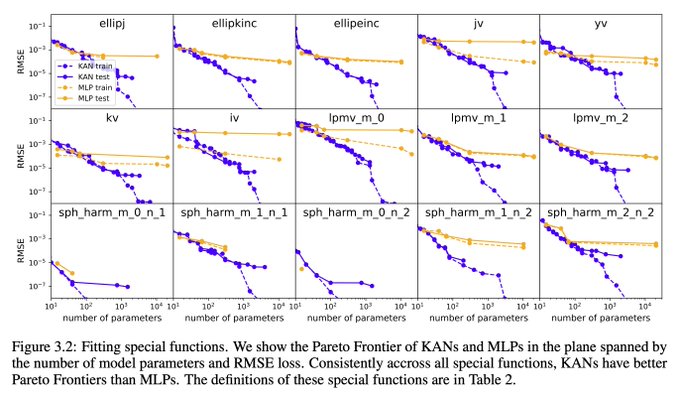
8/N KANs are more accurate than MLPs in function fitting, e.g, fitting special functions.
1
5
97
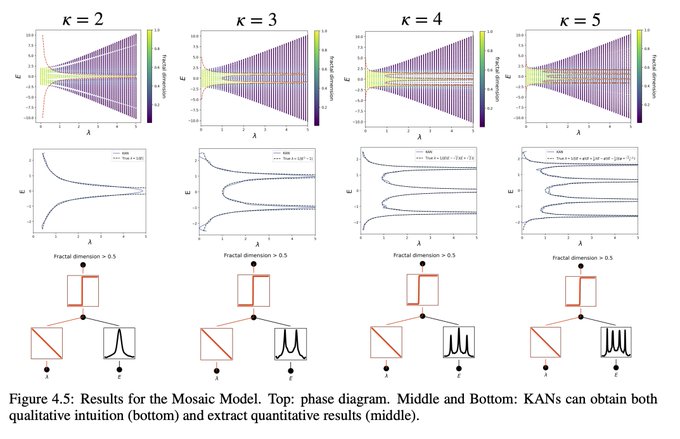
15/N KANs are also helpful assistants or collaborators for scientists. We showed how KANs can help study Anderson localization, a type of phase transition in condensed matter physics. KANs make extraction of mobility edges super easy, either numerically,
1
2
95
The pizza paper is accepted by
#NeurIPS23
as an oral presentation: Mechanistic interpretability can be more diverse (but also more subtle) than you think! This calls for (automatic) classification of algorithms, which is less biased by human intuition than the way MI is done now.
NN interpretability can be more diverse than you think! For modular addition, we find that a “pizza algorithm” can emerge from network training, which is significantly different from the “clock algorithm” found by
@NeelNanda5
. Phase transitions can happen between pizza & clock!
3
54
336
3
3
76

Our work “Omnigrok: grokking beyond algorithmic data” has been highlighted in ICLR 2023 as spotlight! Besides grokking, our unique way of visualizing loss landscapes holds promise to explain other AI emergent capabilities, study neural dynamics and unravel generalization as well.
The grokking phenomenon seemed very puzzling and uncontrollable, but no more! We understand grokking via the lens of neural landscapes, and show we can induce or eliminate grokking on various datasets as we wish. Joint work with
@tegmark
@ericjmichaud_
.
4
53
281
2
8
69
It's funny that our "AI for conservation laws" methods become increasingly simpler, more interpretable, but also less publishable (rejected by PRL first🥲, but then accepted by PRE 🥳). Curiosity-driven science need interpretability, not scale. We want less, not more. Fun collab!
3
9
66

Happy new year, my friends on twitter! 2023 was quite challenging for me: I might be lucky enough to not have any early PhD crisis, but mid PhD crisis is real! I do not hope that 2024 has fewer challenges for me, but hope that I’ll be more peaceful, more matured, more strong.

2
0
61
It’s definitely my greatest pleasure to be on Cognitive Revolution Podcast!
@labenz
and I discussed in depth my recent work w/
@tegmark
on making neural networks modular and interpretable using a simple trick inspired from brains! Mechanistic interpretability can be much easier!

[new episode]
@labenz
intereviews
@ZimingLiu11
at MIT about his research: making neural networks more modular and interpretable.
They discuss:
- The intersection of biology, physics, +AI research
- mechanistic interpretability advancements
- Those visuals!
Links ↓
1
4
14
0
6
50
Human scientists in the time of AI. Which party do you identify yourself in? 🤪 Borrowed some terminology from the Three-Body Problem by Cixin Liu.

1
5
49
Input your favorite differential equations, our AI can spit out ALL conservation laws! An extension of our first AI Poincare paper published in PRL!
0
3
48
Really excited that our research on grokking + pizza are covered by
@QuantaMagazine
! Artificial intelligence is more or less "Alien Intelligence" -- just like in biology, we need scientific methods to study these "new lives".

2
6
46
@Sentdex
Thanks for sharing our work! In case anyone's interested in digging more, here's my tweet 😃:
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
117
1K
5K
1
3
49
If I ever grew taller, these two photos will be more similar 😝
@ke_li_2021
@YuanqiD
Look up to role models
@geoffreyhinton
, Yoshua Bengio,
@ylecun


2
0
43
Amazingly, algorithmic advantages come from a beautiful physical fact: Coulomb interactions are long-ranged!
0
4
43
Happy to read this paper evaluating the ability of BIMT for automated circuit discovery! One reason our BIMT gets rejected by NeurIPS is due to lack of evaluation, so really awesome to read this work!
2
7
40
Here is the link, in case you can bear with the boredom :)

0
0
38
Tired of diffusion models being too slow, but don't know how to start with our new physics-inspired model PFGM? This is the perfect blog for you, very approachable in both understanding the picture and getting hands-on experience!

Stable Diffusion runs on physics-inspired Deep Learning.
Researchers from MIT (first authors
@ZimingLiu11
and
@xuyilun2
) have recently unveiled a new physics-inspired model that runs even faster!
This introduction has everything you need to know 👇
2
34
165
1
4
37
Paper link here in case you're interested😃:

Ziming Liu
@ZimingLiu11
from
@MIT
discussing A Neural Scaling Law from Lottery Ticket Ensembling
#MITAIScaling
@MITFutureTech

0
1
6
0
5
36
Our recent work on physics-inspired generative AI is covered by Quanta magazine! 🚀 Check this out!

0
4
36
Really nice write up on grokking from google 👍

Do Machine Learning Models Memorize or Generalize?
An interactive introduction to grokking and mechanistic interpretability w/
@ghandeharioun
,
@nadamused_
,
@Nithum
,
@wattenberg
and
@iislucas
20
255
1K
0
1
31
Advertisement alert🚨
I'll be presenting five projects at
#NeurIPS2023
, with topics include mechanistic interpretability, neural scaling law, generative models, grokking and neuroscience-inspired AI for neuroscience🧐. Welcome!
2
1
31
Also fun to collaborate (again) with my friend
@RoyWang67103904
whom I knew from elementary school :)
0
0
35
@shaohua0116
Sad, but still better than what I’ve got from my 600-word rebuttal addressing all the questions they asked: “after reading other reviewers’ comments, I decided to lower my score.” 😂
1
0
30
Next week I’ll be attending NeurIPS! Looking forward to meeting all of you! Reach out if you want to chat (topics including but not limited to: physics of deep learning, AI for science, mech interp etc.)
Also don’t forget to come to our
@AI_for_Science
workshop on Saturday! 🤩
1
0
31
People have different opinions but I believe:
- AI safety can be achieved by engineering
- AI safety can be achieved by mechanistic interpretability
- Mech interp can’t be achieved w/o science
In conclusion, if I want to rush for AI safety, I won’t bet on mech interp.
2
2
30
@aidan_mclau
Thanks for sharing our work! In case anyone's interested in digging more, here's my tweet 😃:
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
117
1K
5K
0
1
30
Will compose a more detailed thread when the arXiv link is ready🙂
2
0
29
@arankomatsuzaki
Thanks for sharing our work! In case anyone's interested in digging more, here's my tweet:
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
117
1K
5K
2
5
29
Excited to attend
#NeurIPS2022
Tuesday to Saturday. If you are also a fan of AI + Physics, let's chat! DMs are welcome.
3
0
28
0
4
24
🔔🔔🔔talk alert
Welcome to my talk at Caltech tomorrow (Jan 5) 4pm at annenberg 213! I’ll discuss human scientists’ situation in the time of AI, and my personal solution to that. 🙋♂️
3
1
24
First time working on a math paper😎 A huge pleasure to work with my friend Yixuan Wang and Prof. Andrew Stuart!
2
0
24
Following up my previous tweet, I'll be at
#NeurIPS2023
from Tuesday to Saturday! I've been thinking about these questions and would love to hear people's thoughts on this. In return, I'll also provide my two cents if you're interested :-). A thread🧵.
1
1
24
link:
0
3
23
Truly inspiring work! Atomic physics helps representation learning 😎🥳

0
4
24
We present a simple effective theory and phase diagrams to demystify grokking, a generalization puzzle discovered by
@OpenAI
last year.
arXiv:
3
2
23
Tomorrow I will be sharing our recent works in the exciting neural scaling law workshop. I will talk about phase transitions of deep learning, emergence of representations/algorithms, and mechanistic interpretability etc.
0
1
23
@kaufman35288
The examples in our paper are all reproducible in less than 10 minutes on a single cpu (except parameter sweep). I have to be honest that the problem scales are obviously smaller than typical machine learning tasks, but are typical scales for science-related tasks.
3
0
25
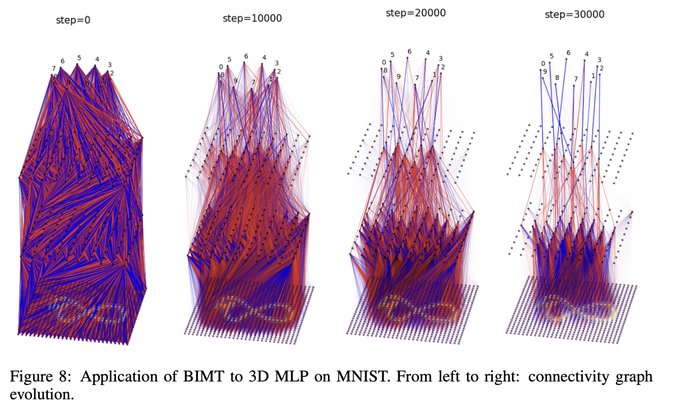
14/N ..., and finally image classification (neural networks embedded in the 3D Euclidean space)!
1
4
20
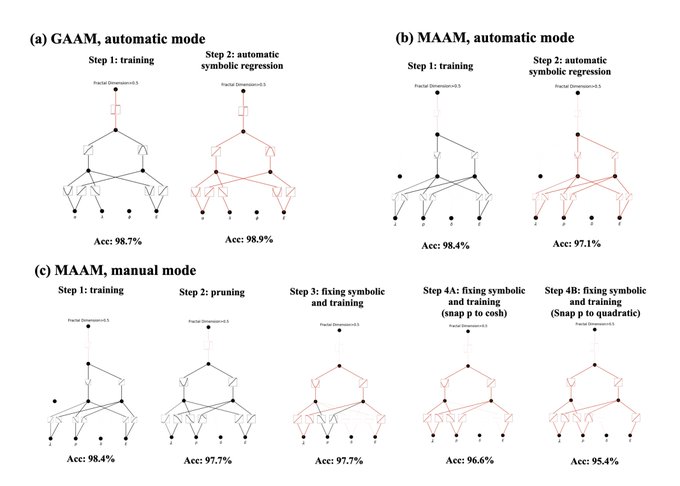
Symbolic regression (finding symbolic formulas from data) has been quite successful on some examples, but it also fail completely for others. Instead, our goal is structure regression (finding modular structures from data), which can provide visible insights for all cases.
4
4
21
Honored to get a mention in this nice review article published in Nature! The journey has just started 🚀😎
0
3
19
@_akhaliq
Thank you so much for sharing our work! In case anyone's interested in digging more, here's my tweet:
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
117
1K
5K
0
0
19