

Yilun Xu
@xuyilun2
Followers
2K
Following
1K
Media
23
Statuses
98
World Sim @GoogleDeepMind. Prev: @NVIDIA, PhD @MIT_CSAIL, BS @PKU1898 . views are my own
Joined September 2018
It's rewarding to see my work back in 2019 still in the conversation.

# A new type of information theory. this paper is not super well-known but has changed my opinion of how deep learning works more than almost anything else. it says that we should measure the amount of information available in some representation based on how *extractable* it is,

5
2
63
For more information, please refer to our paper:. paper:. project page: 6/N, N=6.
1
1
7
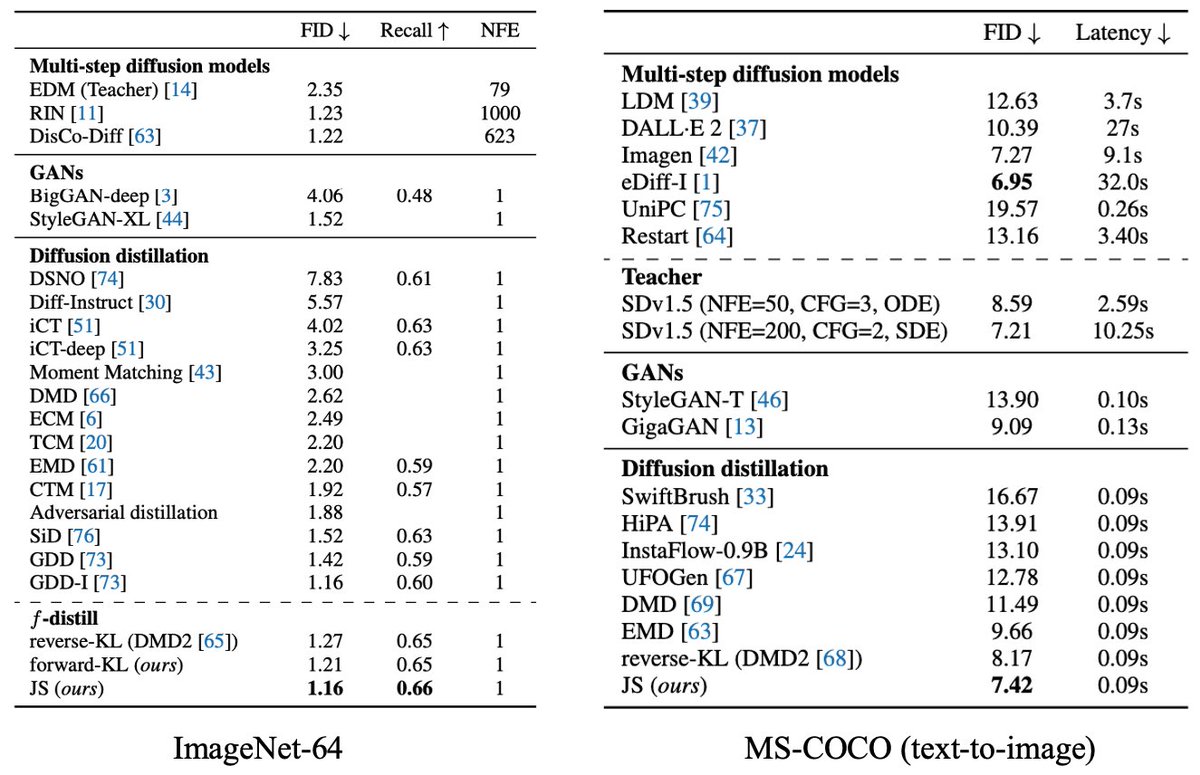
Our experiments on image generation show that less-mode-seeking divergences perform better! For example, Jensen-Shannon divergence achieves the sota FID score on zero-shot MS-COCO w/ SD1.5. Not only that, we show that the diversity of samples improves given a text prompt. 5/N
1
1
5
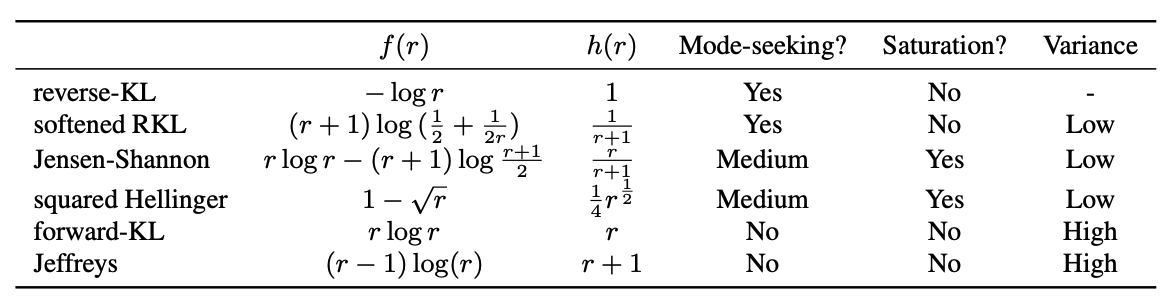
Different f-divergences exhibit distinct characteristics in diffusion distillation, including mode-seeking behavior, saturation, and training variance. We encourage users to select the f-divergence best suited to their specific needs. 4/N
1
1
3
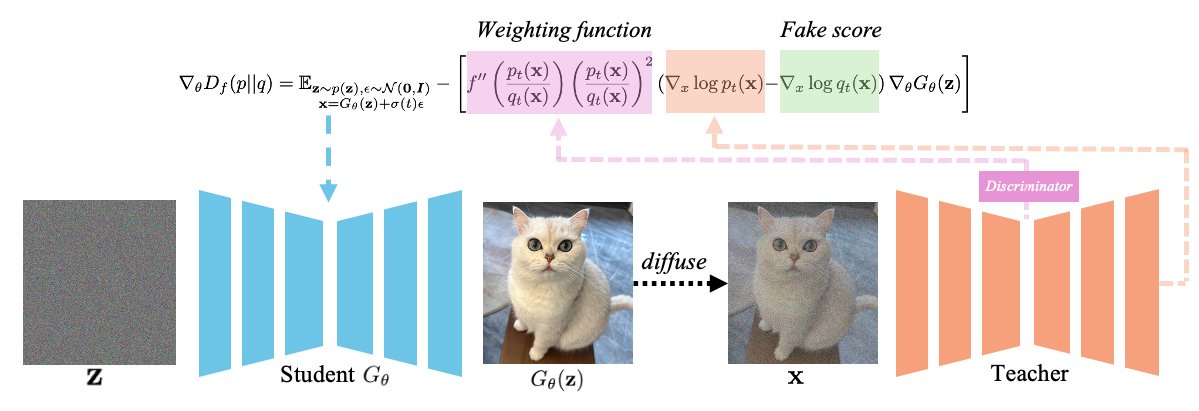
The gradient of the f-divergence is expressed as the product of their *score differences* and a *weighting function* determined by their density ratio. It naturally emphasizes higher density in the teacher distribution, w/ less mode-seeking divergence (mitigate mode drop). 3/N.
1
1
5
The previous popular variational score distillation approach minimizes the reverse-KL divergence, known as mode-seeking. We generalize the VSD approach using a novel f-divergence minimization framework, termed f-distill, that covers different divergences. 2/N
1
2
5
Tired of slow diffusion models? Our new paper introduces f-distill, enabling arbitrary f-divergence for one-step diffusion distillation. JS divergence gives SOTA results on text-to-image! Choose the divergence that suits your needs. Joint work with @wn8_nie @ArashVahdat 1/N

8
49
243
⚡️ New recipe for diffusion models -> one-step generator!. Intuition: information flows in consistency training *propagate* from data to noise. It enables multi-stage training for better model capacity allocation. Excited to see simple intuition gives SOTA consistency models!
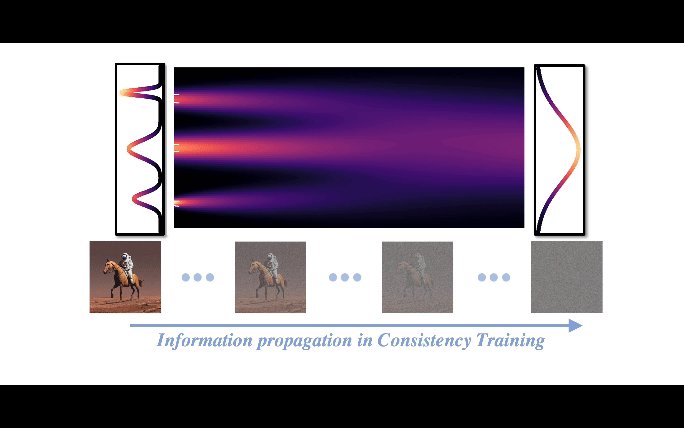
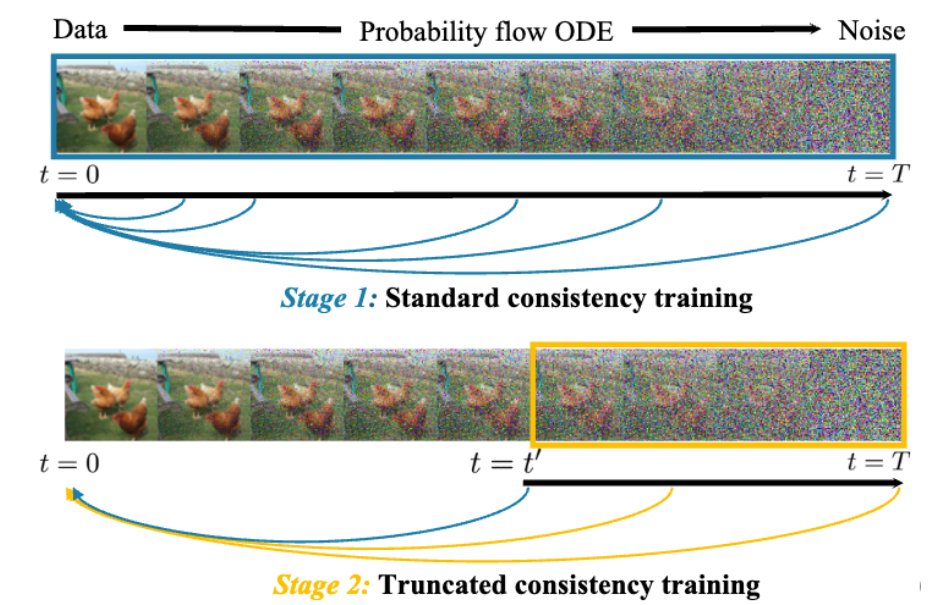

Time to make your diffusion models one step! Excited to share our recent work on Truncated Consistency Models, a new state-of-the-art consistency model. TCM outperforms a previous SOTA, iCT-deep, using more than 2x smaller networks in both one-step and two-step FIDs. Joint work.
2
19
154
Check out our new model for heavy-tailed data 🧐, with Student-t kernel. Through this project, I came to realize PFGM++ uses the Student-t kernel Nature is magical! Thermodynamics gives us Gaussian (diffusion models), electrostatics gives us Student-t (PFGM++). What's next?.

🌪️ Can Gaussian-based diffusion models handle heavy-tailed data like extreme scientific events? The answer is NO. We’ve redesigned diffusion models with multivariate "Student-t" noise to tackle heavy tails! 📈. 📝 Read more:

0
15
92
The generation process of discrete diffusion models can be simplified by first predicting where the noisy tokens are by a *planner*, and then refining them by a *denoiser*. An adaptive sampling scheme naturally emerges based on the planner: more noisy tokens, more sampling steps.

Discrete generative models use denoisers for generation, but they can slip up. What if generation *isn’t only* about denoising?🤔. Introducing DDPD: Discrete Diffusion with Planned Denoising🤗🧵(1/11). w/ @junonam_ @AndrewC_ML @HannesStaerk @xuyilun2 Tommi Jaakkola @RGBLabMIT

0
1
31
Does my PhD thesis title predict the Nobel outcome today? 😬. “On physics-inspired Generative Models”.
Officially passed my PhD thesis defense today! I'm deeply grateful to my collaborators and friends for their support throughout this journey. Huge thanks to my amazing thesis committee: Tommi Jaakkola (advisor), @karsten_kreis , and @phillip_isola ! 🎓✨


4
7
160
For more information, please visit our project page: . Shout out to my awesome collaborators and advisors @GabriCorso , Tommi Jaakkola, @ArashVahdat and @karsten_kreis (9/9).
research.nvidia.com
DisCo-Diff combines continuous diffusion models with learnable discrete latents, simplifying the ODE process and enhancing performance across various tasks.
0
4
15
We believe DisCo-Diff could be further.extended text-to-image/video generation, where.we would expect discrete latent variables to offer complementary benefits to the text conditioning, similar to how discrete latents boost performance in our class-conditional experiments. (8/9).
6
0
7
We also test DisCo-Diff on molecular docking, building upon the DiffDock framework. We see that also in this domain discrete latents provide improvements, with the success rate on the full dataset increasing from 32.9% to 35.4% and from 13.9% to 18.5%. (7/9)
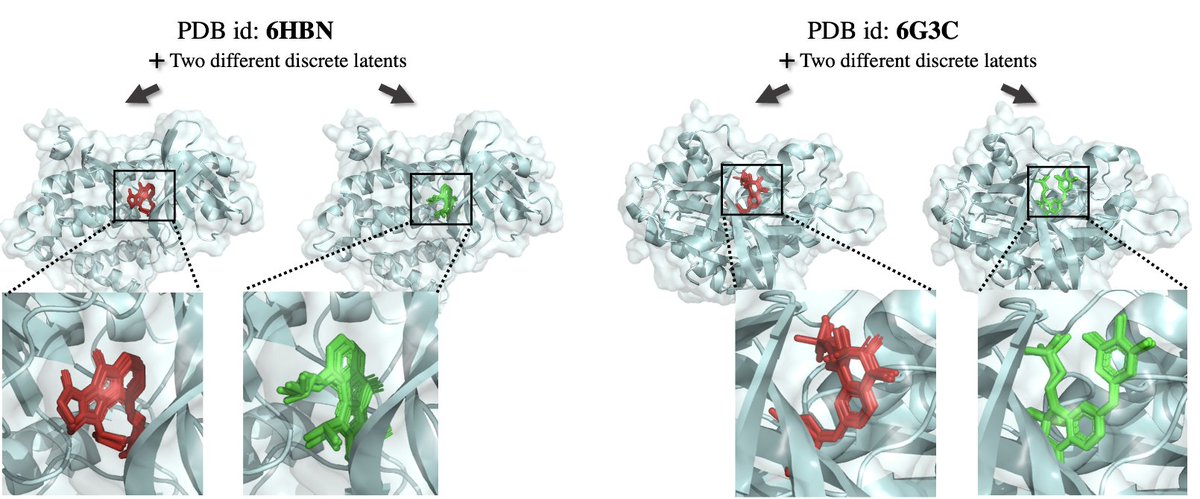
1
0
9
Empirically, DisCo-Diff consistently improves model performance on several image synthesis tasks and molecular docking. It achieves the new state-of-the-art on ImageNet-64/ImageNet-128 with an ODE sampler. (6/9)
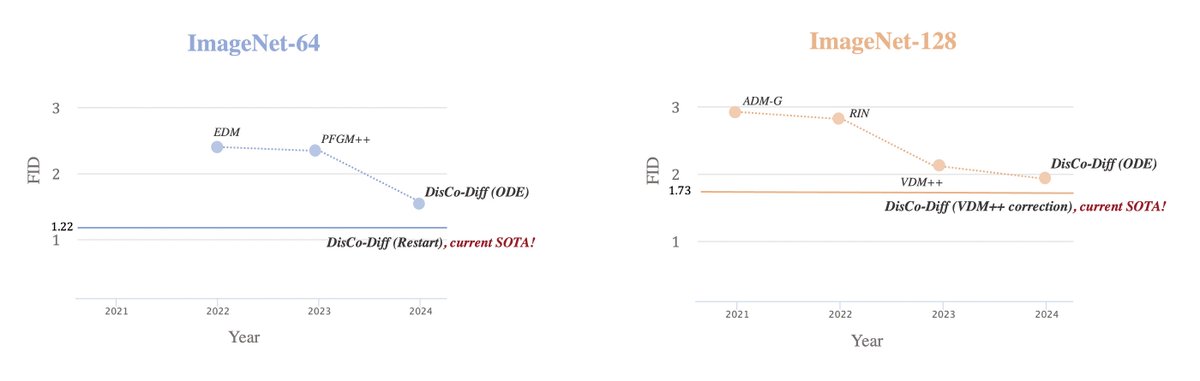
1
1
9
An additional autoregressive model post-hoc the distribution of the discrete latent. The discrete latent captures global statistics in Euclidean space, such as layouts, shapes, and color variations. These statistics are complementary to semantics, such as class labels. (5/9)

1
0
12
To this end, we augment diffusion model with learnable discrete latent, inferred with an encoder, and train diffusion model and encoder end-to-end. The encoder is encouraged to encode global discrete structure into the latent and help the denoiser to reconstruct the data (4/9).
1
1
9
Conversely, using the known global discrete structure (e.g., index of modes) of data as input for diffusion models reduces the curvature of the ODE path (see right figure above). A key challenge remains: how to infer this discrete structure directly from the data? (3/9).
1
0
6