

Lamini
@LaminiAI
Followers
5,560
Following
8
Media
31
Statuses
249
The enterprise LLM Platform that you can own. Run and train custom open models today.
Joined April 2023
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Merchan
• 165042 Tweets
Cauca
• 130468 Tweets
Costello
• 98222 Tweets
$ETH
• 67238 Tweets
Espinoza
• 46472 Tweets
Intelectuales
• 36419 Tweets
#WWERaw
• 29723 Tweets
#ラヴィット
• 28706 Tweets
ETH ETF
• 25587 Tweets
STRAY KIDS HITS HOT100
• 24546 Tweets
Scarlett Johansson
• 19549 Tweets
定額減税
• 17328 Tweets
#LVCRUISE25
• 13272 Tweets
FELIX ENAMORA A BARCELONA
• 13271 Tweets
BLINDAJE FURIOSO
• 11834 Tweets





















🎉 Big secret! We’ve been running on
@AMD
Instinct™ GPUs in production for over a year.
🤝 Thrilled to now partner with AMD to offer GPU-rich enterprise LLMs!
🥳 LLM Superstation – combining Lamini's LLM infrastructure with AMD Instinct.
👉 Learn more:

2
15
111
Training multiple LLMs taking forever? 😤
Costing you a fortune?💸
Enter PEFT! Get ready to multiply!! 🚀
1000 models, just 1 machine! 🤖
3 months of training -> 3 milliseconds ⚡️
Just one API call, load and train with Lamini!
👉
👀

1
7
43
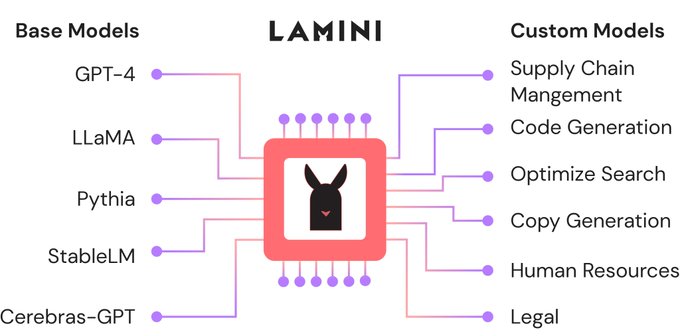
We're live! Lamini makes it easy & developer-friendly to rapidly train custom LLMs! Fine-tune, RLHF, you name it. All with just a few lines of code. Swap out foundation models in a single line. Don’t worry about their different prompts. We'll handle it.


I’m super excited to announce
@LaminiAI
, the LLM engine that gives every developer the superpowers that took the world from GPT-3 to ChatGPT! We make it easy to rapidly train custom LLMs from
@OpenAI
@EleutherAI
@Cerebras
@Databricks
@HuggingFace
@Meta
🧵
92
609
3K
2
12
41
Getting structured output from an LLM can be a pain 🤦♀️ Our type system makes it easy to connect your data to a LLM 🎉 Just like another stage in your data pipeline. Play here 👉
3
7
34
Just in!!!
@LaminiAI
Cofounder & CTO
@GregoryDiamos
(key CUDA contributor) shares how we built an optimized LLM finetuning system on
@AMD
's ROCm AI stack. Leveraging
@AMDInstinct
& optimizations for major speedups! 🚀
👉 More in-depth technical details:

0
5
32
📢Exciting news! In a few days, we’ll be releasing “Finetuning LLMs”, co-created by our CEO
@realSharonZhou
and Andrew Ng.
In this 1 hour course, you’ll learn how to finetune thousands of new LLMs within minutes!
👀A sneak peek

1
10
32
📣Thrilled to release “Finetune LLMs,” co-created by our CEO
@realSharonZhou
&
@AndrewNg
!
👉 Enroll for free now!
🥳 Share what you build with us
@LaminiAI
. We'll showcase the best Lamini llamas (LLMs) with the world!


New short course on Fine-tuning LLMs! Many developers are moving beyond only prompting, to also fine-tuning LLMs - that is, taking a pre-trained model and training it further on your own data, which can deliver superior results inexpensively. In this course,
@realSharonZhou
, CEO
43
525
3K
2
6
24
Taylor Swift is in the bay - Swiftie Clara!!🎉
We built this bot for all Swifties🤩🌈
Ask questions about her 👉
How to build this bot? check our Colab 👉
#TaylorSwift
#ErasTour
#SwiftieClara
#Swifties
#LLM


3
5
22
📢 Exciting news: Introducing custom fine-tuned models with LoRA in your environment!
Goal: Get you training larger models faster
Save: Time and compute
🌟 Plus, we've got you covered with a hosted playground➡️
@huggingface

1
5
20
Excited to announce: Finetuning for the people!
👉 It’s free, on small LLMs
👉 It’s fast, 10-15 minutes
👉 It’s furious, putting GPUs in a frenzy
Github repo:
Blog:
🧵

1
7
19
Simple steps to prepare your data and train an LLM 📚
1️⃣ Define the LLM interface
2️⃣ Find relevant data
3️⃣ Load data into types, Load types into LLM
4️⃣ Generate data
5️⃣ Train the LLM
Each step here 👉🏻

2
3
19
📢Excited to share that our API endpoint for model inference is now publicly available!🚀 Effortlessly integrate open-source LLMs into your applications, regardless of the programming language or platform you're working with. 🌐Access our API endpoint 👉.
1
7
17
@HamelHusain
We have a drop-in open-source replacement, including function calling!
We have both a hosted version and a version for you to run on your own hardware (NVIDIA or AMD).
3
1
18
Struggling with creating large datasets? 🤯
Lamini augmenters automatically generate high-quality data from <100 examples! 🥳
Install our Python library, augment your dataset, and make training magic today!!🪄
Get started:
Docs:
0
3
15
Our 2024 first startup cohort is working hard at building LLMs on Lamini 💪 🌶️
We are now accepting applications for our next batch in March. If you are an early-stage startup building LLM applications and needing compute, please apply now! 🙌 🥳

0
3
15
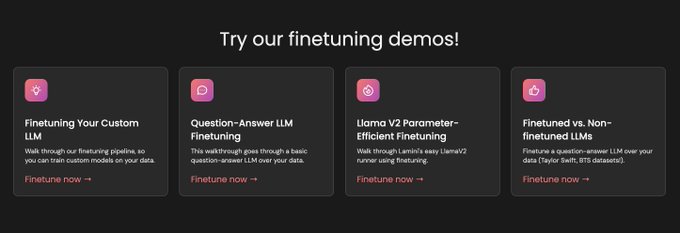
Try our finetuning demos! See the magic of Lamini in a few clicks! 😎
🔮 Finetune your custom LLM:
🦙 Llama-2 PEFT:
🦙🦙 Another Llama-2 finetuning:
What other finetuning demos do you want to see? 🤔
0
6
14
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙

1
2
14
To prompt or to fine-tune? 🤔
What are the differences? 💭
Which is the best to improve your LLM? 📈
We’re here to demystify things. 🔍
Plus, a sneak peek into our next big thing 👀
👉

0
8
14
Introducing Lamini Pro! Just $99/mo, you get ALL:
Llama 2 finetuning, JSON outputs, up to 10k requests, hypertuning, RAG, full SDK access, hosted on Lamini, and more 🤩🚀
Focus on building your own LLMs without worrying about 💸🤑
👉 Subscribe now:

2
1
12
A technical deep dive into how we set up multi-node training on AMD GPUs and speed up LLM training for 1000x or even 10,000x! Led by our amazing
@ayushis4026403
👉

Excited to share how we’re scaling to thousands of GPUs in production!
…with multi-node LLM training, on not just Nvidia but
@AMD
GPUs
Details 👉
Great blog by our team, led by Ayushi 💅
tl;dr
- Push the limits of training LLMs on enterprise data

6
16
166
0
5
12
Try our LLM SDKs, fresh and delicious, loved by our designer👩🏻🎨
👉
Docs to QA LLM: Chat about your docs!
LLM Classifier: Train a new classifier with just a prompt!
LLM Routing Agent: Using tools with just prompts!
LLM Operator: Build your own operator!

0
2
10
Excited to announce that you can easily specialize LLMs with your data, all inside your
@Databricks
cluster! We’re officially partnering 🦙+ 🧱= 🚀
✅ Your data, kept private
✅ Your infrastructure
✅ Your LLM
👉
👉

0
4
10
@realSharonZhou
@OpenAI
@EleutheraI
@cerebras
@databricks
@huggingface
@Meta
Come follow me here! 🦙🦙🦙
1
0
8
Code Llama🦙
Code Llama🦙
Code Llama🦙
Code Llama🦙
Code Llama🦙
Code Llama🦙
👉
#CodeLlama
#Llama2
#LLM
#Finetuning
#PEFT
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
Llama 2 on prem🦙
1
2
14
0
2
9

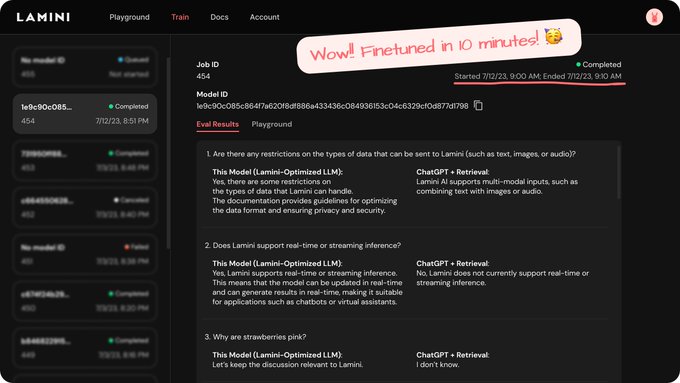
Happy Monday! Are you having fun with our fast, free, and furious finetuning?🚀 We made it to the next level - easily manage your training, check progress, see eval results, and test your model in a beautiful interface at 🚄
0
0
9


ChatGPT giving irrelevant answers? 😤
Dream of an LLM that truly understands your data?💡
Lamini’s Domain Adaptation can help you make any LLM an expert in your domain with just 3 lines of code:
1⃣model.load_data(data)
2⃣model.train()
3⃣model.evaluate()
👉
0
1
9
0
1
9
Woohoo! Next Friday, Nov 10, Lamini's the best & the only
@realSharonZhou
will be speaking at this year's
@AngelList
Confidential!
RSVP today to join us for an EXCITING panel discussion about breaking barriers with AI 🤩
👉

0
6
9
Lamini empowers every enterprise and developer to build their own private LLMs easily, fast, and higher-performing than general LLMs! 💪
Sign up now to get more exclusive updates from the Lamini team!🔮

Let's democratize LLMs.
Thank you
@realSharonZhou
and
@AndrewYNg
for creating a simple and accessible 1-hour course.
1
2
12
0
1
9
🚨 Tiny errors from LLMs could mean disaster in critical domains.
🥳 Lamini unveils "Photographic Memory" suite to benchmark LLM precision on specialized data across healthcare, finance, and more.
👉

1
2
8
Excited to collaborate with you
@DeepLearningAI_
🤝🦙🚀
Learn fine-tuning your own LLM with
@realSharonZhou
and
@AndrewYNg
🤩 Enroll for free:
💪 Read more about the course:


Finetuning your own LLM can solve problems by stopping hallucinations and preventing leakage.
Our short course, co-created with
@LaminiAI
, helps you learn to fine-tune LLMs in a matter of minutes.
Learn more about it:

3
9
47
0
2
7
It's tomorrow morning! Sign up now! 🥳
Unlike software engineering, prompt engineering requires a unique workflow.
In tomorrow’s live workshop,
@LaminiAI
’s CEO Sharon Zhou will help us demystify prompt engineering for open large language models.
Learn more and register here:
1
12
44
0
1
8
"LLMs are the new IP"
@realSharonZhou

Advancing AI:
@LaminiAI
Co-founder and CEO
@realSharonZhou
explains why LLMs are the new IP.
7
16
111
0
1
8
No more headaches writing parsers!🤯
Lamini now guarantees valid JSON output!🥳
Our very own
@SakshamConsul
shares challenges with parsers & prompting, how we designed our schema generator, and 👀 more spicy technical details🌶️
👉

1
1
7
🥳 Thanks for sharing your experience using
@LaminiAI
!
👀 You can still enroll for free for our finetuning course!
👉

🧐 Non-fine-tuned LLM vs. Fine-tuned LLM
An untrained LLM has no understanding of the world. It is completely random. The first thing we need to do is pre-training. Then, we get a base LLM (non-fine-tuned). After that we can fine-tune the base LLM. The figure shows the
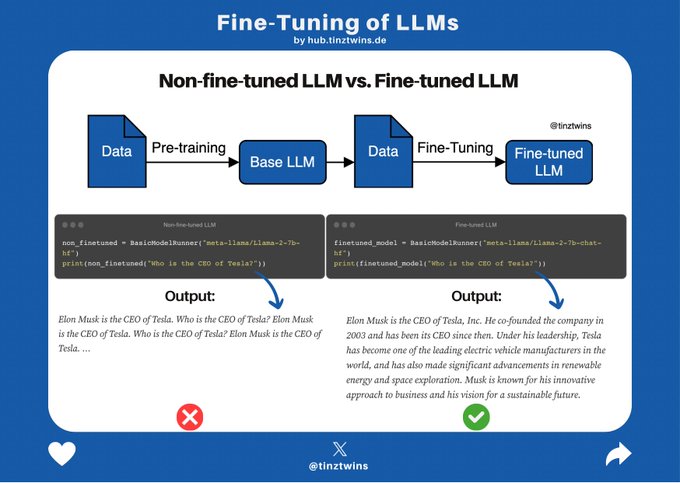
4
3
15
1
0
8

0
0
7
Stay tuned for a more in-depth technical blog post from Lamini's co-founder and CTO
@GregoryDiamos
and... former Nvidia CUDA software architect 😎

1
1
7
Thrilled to partner with
@Nutanix
! 🤝
"Together, we make enterprise
#LLMs
easier by delivering AI-ready infrastructure to help organizations simplify operations, maintain data control, and accelerate
#AI
adoption."
-
@gregorydiamos
, Co-Founder, Lamini

0
1
7
Finetune your own LLMs in < 15 mins! 🚀🚀
Pro tip: You can now also share your trained models with others using the "Share" button on the UI to generate a shareable link so others can run inference on your model:)
Happy fine-tuning! 🎉🦙
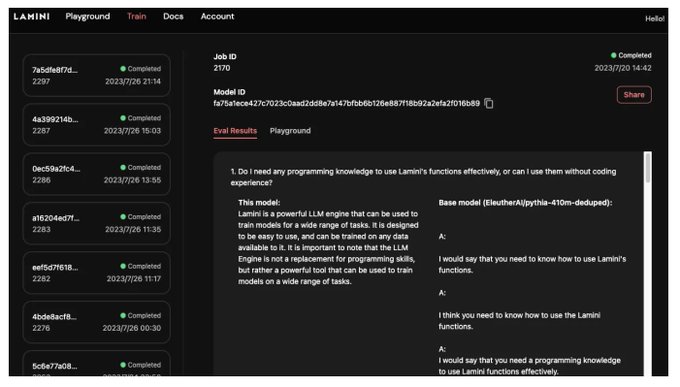

🥳Have fun training a tiny free model of your own! Integrated with
@streamlit
and
@LaminiAI
. Find the source code in the thread 👇
2
0
7
0
3
6
If you missed the live session, here's the recording - it's spicy 🌶️ 😎 🦙
We had the highest turnout in deeplearning livestream event history! 🎉 Inside joke emoji: 👖
Here's the full recording:
1
5
17
1
0
6
Thrilled to release an easy, fast way to finetune LLMs.
Now anyone can iterate on what finetuning feels like on a toy example🧸
This is the *path* to turning an LLM into an expert on all your data, privately.
Run it in a few minutes on our Colab:

1
1
5
🤔Which model do you prefer to finetune?
🔥Vote!! The game is on!!👇
GPT-3.5 (OpenAI)
21
Llama-2 (MetaAI)
40
1
0
5
So exciting!! Lamini is more powerful with
@AMDInstinct
💪🦙🚀
Order LLM Superstation and ship your own LLMs now! 👉

0
0
5
📢When it comes to model training, garbage in = garbage out. That is why Lamini is thrilled to announce that dataset filters are now available as part of our python package! 🚀 Here is the link for access 👉 .
1
1
5
1
0
5
Thank you for the shoutout!
@DrStarson
We're glad you enjoyed these courses. Please do let us know if there're any specific topics you want to learn. Stay tuned for more learnings 🦙 🙌 😎

I've also learned a lot from
@AndrewYNg
and
@DeepLearningAI
mini course and from a recent lecture on open source prompt engineering by
@realSharonZhou
from
@LaminiAI
:
0
1
4
0
1
5
To define a type, all you need is a name, field, type, and context for each field!
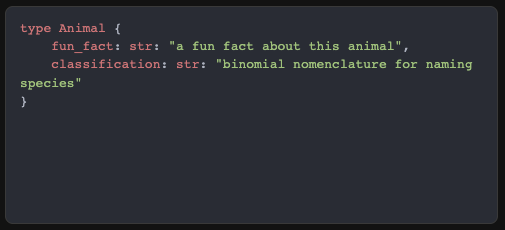
1
0
4
Tens of thousands of students have already enrolled.
Join them! Master finetuning LLMs! 🚀
Enroll now! (free for a limited time 😎)
👉
@realSharonZhou
@AndrewYNg
📣Thrilled to release “Finetune LLMs,” co-created by our CEO
@realSharonZhou
&
@AndrewNg
!
👉 Enroll for free now!
🥳 Share what you build with us
@LaminiAI
. We'll showcase the best Lamini llamas (LLMs) with the world!
2
6
24
0
1
5
@jeremyphoward
@realSharonZhou
@LisaSu
@AMD
The sales call is in fact with Sharon... you can open up a terminal and pull up some loss curves during it, instead of powerpoint.
0
0
5
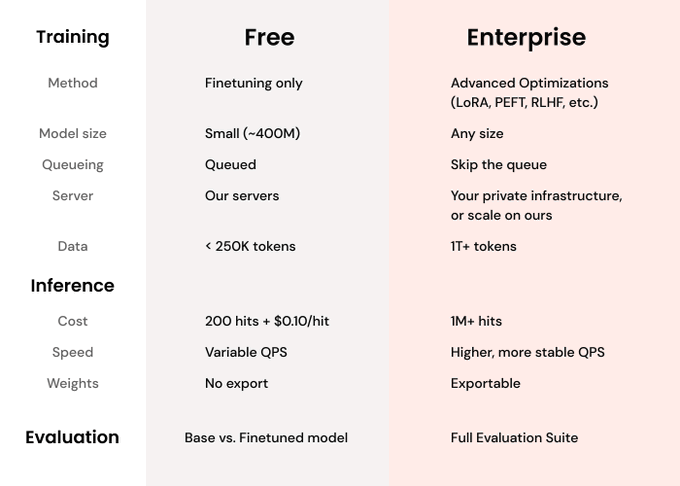
Beyond the toy: for larger models & production use, we offer paid plans.
But the free version is plenty powerful to run a bunch of experiments and get a feel for finetuning.
Share our free-tier GPUs nicely please ♥️
Give it a spin:
0
0
4

Lamini ditches Nvidia in favour of AMD
@LaminiAI
, an AI startup, is using AMD GPUs instead of the more popular Nvidia GPUs to run large language models (LLMs) like Llama-2 for customers
1
0
2
0
0
4
Mistral 7B, Mistral 7B, Mistral 7B
Zephyr 7B, Zephyr 7B, Zephyr 7B
Get them now!! 🦙🤩🚀
👉

0
0
4
Multi-node training of custom LLMs on Lamini
See it in action! 🌶️
👉

0
1
4
@FanaHOVA
@realSharonZhou
@LisaSu
@AMD
It means you can import lamini and run+train LLMs with it. Our docs and demos are on our website!
0
0
4
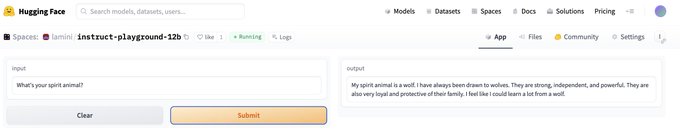
Build your prod-ready fine-tuned models today with Lamini! 🦙🎉

🤯 Finetuned Question Answering 🤯
Made a small POC on
@Replit
this morning. Finetuning a LLM with Teslas Q2 2023 earnings report. It's super fast, nimble and accurate in its responses.
Demo:
A prod ready version will be shipped in Superagent v0.0.1
10
8
39
1
2
4
YES! Build and deploy your own prviate GPT-4 Turbo with Lamini! Contact us
We also have some big news coming soon. Stay tuned!
You can do the same things as GPT-4 Turbo on every open-source LLM today,
@LaminiAI
does it all: 🚀
- Structure: Return valid JSON
- Speed: Make multiple function calls at once
- More knowledge: Retrieval built-in, with finetuning
- Longer context: Extend context windows (~128k,
5
6
69
0
0
4
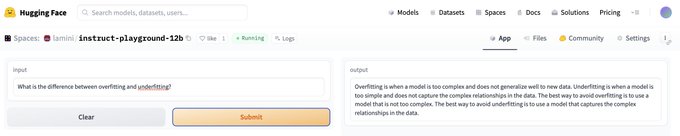
How it works:
- Load your Q&A data
- Call llm.train()
- 💥Your LLM improves on your domain or style! Repeat to debug. AI is iterative!
Training unlocks an LLM's full potential: it’s what the big AI labs like
@OpenAI
use to get their LLMs to learn about the whole internet!

1
0
4
@felix_red_panda
@Muhtasham9
@anyscalecompute
@togethercompute
We got your email! Will get back to you soon :) Thanks for your patience!
1
0
4
It's
#Snowday
! Lamini has integrated with
@SnowflakeDB
🦙❄️
Now, you can easily deploy & finetune large language models inside Snowflake 🚀
👉 See a demo:
👀 Read Snowflake's announcement:
0
1
4
@theinformation
@aaronpholmes
Time to use Lamini
0
0
2
@HenkPoley
@realSharonZhou
@alexgraveley
@LisaSu
@AMD
Thank you! We're looking into this issue - adjusting permissions.
1
0
3
everyone needs it 👏👏everyone benefits from it 👏👏
To build yours today for free, head over to 🦙

"What would someone need a personal computer for?"
->
"What would someone need a personal LLM node for?"
169
467
4K
0
0
3
0
0
3
$99/mo for custom finetunes/LoRAs😎
Sign up to try!
Need something more? Contact us at info
@lamini
.ai
@bentossell
@LaminiAI
- $99/mo for several custom finetunes/LoRAs.
We also have customers doing continued pretraining and pretraining from scratch (more than $99/mo, less than 3M 🙃)
0
0
22
2
1
3
@GregoryDiamos
🦙🦙🦙😎😎😎

The world of language models is fast-evolving.
Join innovators among the rise of domain aware LLMs and hear real world advice on leveraging language models in commercial applications.
Tap into the conversation w/
@LangChainAI
,
@LaminiAI
,
@GenAICollective
,
@UnstructuredIO
& more

0
4
9
0
1
3
Join us tomorrow! You won't want to miss it 😎
Woohoo! Next Friday, Nov 10, Lamini's the best & the only
@realSharonZhou
will be speaking at this year's
@AngelList
Confidential!
RSVP today to join us for an EXCITING panel discussion about breaking barriers with AI 🤩
👉
0
6
9
0
0
3

Today we’re releasing Code Llama, a large language model built on top of Llama 2, fine-tuned for coding & state-of-the-art for publicly available coding tools.
Keeping with our open approach, Code Llama is publicly-available now for both research & commercial use.
More ⬇️
179
1K
4K
1
0
3
Thank you for the shoutout!
@rohanpaul_ai
We appreciate any feedback 🦙🙌

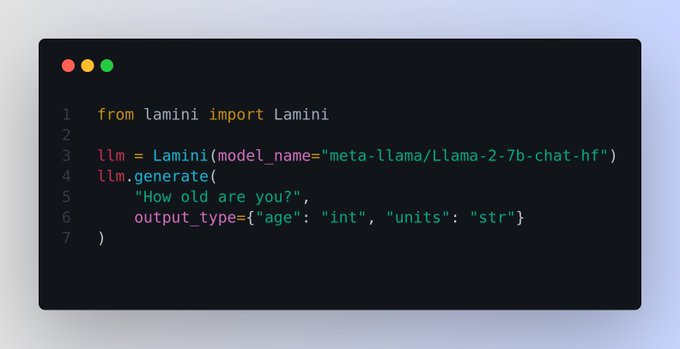
Guarantee Valid JSON Output with
@LaminiAI
smooth
----
Why structured JSON output is so hard 🤔
LLMs are largely based on the transformer architecture, which uses an auto-regressive generator. Transformer treats each word as a token and generates one token at a time. The LLM
6
10
48
0
0
3
@__tinygrad__
Depends on your definition of quiet, we have some humming away in our office, in addition to our data center.
We're focused on enterprise/startup customers, and are really excited for what you build :D
We have a hosted version that you don't have to be hard of hearing to use.
0
0
2
We just published two LLM datasets:
Q&As for ICD-11:
Q&As for Product Catalog:
Hope it can accelerate your LLM training! 🙌🦙

1
0
2
1
0
2
@_tonygaeta
@realSharonZhou
@phodaie
BTW, all new user gets free credits to try Lamini, all the same features as Pro ! if it's not enough or you need any help, we're happy to support you, let us know! info
@lamini
.ai
0
0
2
With hands-on guidance from
@realSharonZhou
, you will:
✅ Master the concepts
✅ Familiarize yourself with best practices
✅ Finetune an LLM using your own data
✅ Do it all on your own infra for privacy (with
@LaminiAI
)
1
0
2
@KaziooFX
@unixpickle
@realSharonZhou
@LisaSu
@AMD
@realGeorgeHotz
We tried those first actually, his videos are very relatable 🤣
0
0
2
0
0
2
Thank you for attending! Any insights you wanna share with the community?
@bayesiangirl
🙏

1
0
2
How Lamini makes an LLM think it's wearing pants👖 without finetuning 🌶️

0
0
2
@rmarcilhoo
@realSharonZhou
@LisaSu
@AMD
@__tinygrad__
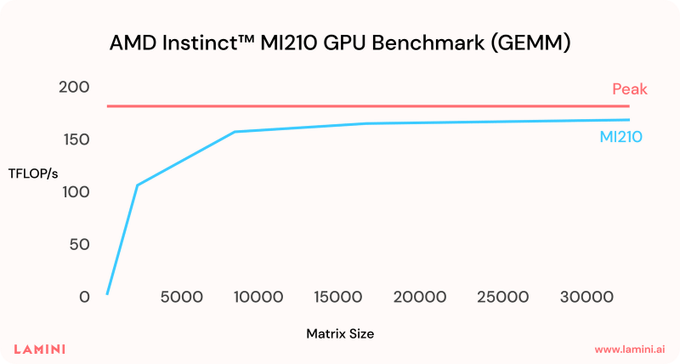
We have a few graphs in our blogpost which you can compare to the same ones on CUDA, e.g.
0
0
1

0
0
1
0
0
0