

Konstantin Willeke
@KonstantinWille
Followers
1K
Following
22K
Media
11
Statuses
222
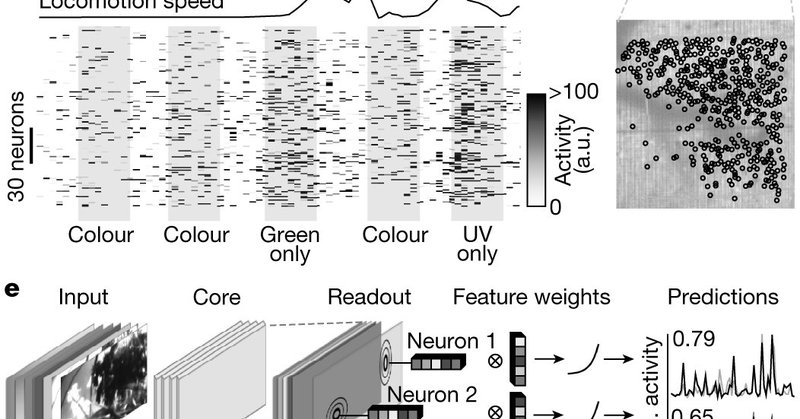
New paper out now in @Nature🥳. We use CNNs, population recording of mouse V1 & pharmacology to show how feature tuning in visual cortex changes /w internal brain state. Shared work with @kfrankelab . Fantastic collaboration between @sinzlab & @AToliasLab.
nature.com
Nature - Computational modelling and functional imaging of awake, active mice show that behaviour directly changes neuronal tuning in the visual cortex through pupil dilation.

So excited this is out @Nature 🎉. Pupil dilation with internal brain state rapidly shifts neural feature/color selectivity in mouse visual cortex by switching between rod&cone photoreceptors👁️🧠. Shared work with @KonstantinWille, @AToliasLab & @sinzlab
5
15
96
RT @kellerjordan0: New NanoGPT training speed record: 3.28 FineWeb val loss in 2.966 minutes on 8xH100. New record-holder: Vishal Agrawal (….
0
39
0
For anyone making it this far in the thread: We're training frontier models on 1T++ tokens of brain data, and we're looking for engineers and scientists 🧠 DM's are open!. [7/6] fin.
2
3
24
Thanks to the enigma ml team: @AdrianoCardace @alexrgil14 @AtakanBedel @vedanglad 💪. Special thanks to our partner @mlfoundry for the support and their affordable H100 nodes! 💙. [6/6].
2
1
18
We also use torch's asynchronous all_reduce operation, so that we can do useful training housekeeping while we wait for the gradients to arrive, e.g. logging and stepping of schedulers. [5/6].
1
0
6
Our new method is very simple. We first build buckets with ideal sizes for current hardware, and fill them up with parameters from 10-20 layers. Then, after the backwards() call is complete, we only have to communicate ~10 buckets, with 64MB worth of gradients each. [4/6]

1
0
13
@AToliasLab @naturecomputes The previous elegant state of the art by @YouJiacheng bypasses torch DDP, and manually reduces the gradients after the backwards is completed, resulting in a significant efficiency gain. However, the gradients of each layer are communicated for each layer independently.

1
0
14
@AToliasLab @naturecomputes In torch's DDP, as the gradients get computed during the backwards() call, they are communicated across all devices via all_reduce. However, when using torch.compile, this overlap of communication and computation is not as efficient as it can be. [2/6]

1
1
15
New NanoGPT training speed world record from the Enigma Project 🎉 (@AToliasLab, @naturecomputes, . We improve the efficiency of gradient all_reduce. Short explainer of our method 👇. [1/6].

New NanoGPT training speed record: 3.28 FineWeb val loss in 2.990 minutes on 8xH100. Previous record: 3.014 minutes (1.44s slower).Changelog: Accelerated gradient all-reduce. New record-holders: @KonstantinWille et al. of The Enigma project


1
17
154
RT @MoonL620922: (1/6) Thrilled to share our triple-N dataset (Non-human Primate Neural Responses to Natural Scenes)! It captures thousands….
0
43
0
RT @naturecomputes: Enigma's excited to co-sponsor Foundry's AI for Science Symposium in San Francisco on May 16th. Join us for an exciting….
0
5
0
RT @AToliasLab: After 7 years, thrilled to finally share our #MICrONS functional connectomics results!. We recorded activity from ~75K neur….
0
95
0
RT @dyamins: New paper on 3D scene understanding for static images with a novel large-scale video prediction model. .
0
8
0
RT @KlemenKotar: 🚀 Excited to share our new paper!. We introduce the first autoregressive model that natively handles:.🎥 Novel view synthes….
0
5
0
RT @dyamins: New paper on self-supervised optical flow and occlusion estimation from video foundation models. @sstj389 @jiajunwu_cs @SeKim….
0
18
0
RT @AToliasLab: With Nvidia’s shares plummeting by ~17% and other big tech taking hits, today alone saw a market value loss exceeding $589….
0
11
0
RT @naturecomputes: Enigma's hosting a post-workshop social with @newtheoryai tonight: NEURREPS x UNIREPS X NEUROAI 7-11pm. RSVP link below….
0
6
0
Come find us at NeurIPS to chat about large scale multimodal models of the brain.

Enigma's at NeurIPS - come find us. New jobs posted on our website for research scientists & engineers in multi-modal modeling & interpretability.


0
2
22
RT @karpathy: People have too inflated sense of what it means to "ask an AI" about something. The AI are language models trained basically….
0
2K
0